

Syntho's kwaliteitsfersekeringsrapport beoardielet generearre syntetyske gegevens en toant de krektens, privacy en snelheid fan 'e syntetyske gegevens yn fergeliking mei de orizjinele gegevens.
By Syntho begripe wy it belang fan betroubere en krekte syntetyske gegevens. Dêrom leverje wy in wiidweidich rapport foar kwaliteitsfersekering foar elke run fan syntetyske gegevens. Us kwaliteitsrapport omfettet ferskate metriken lykas distribúsjes, korrelaasjes, multivariate distribúsjes, privacymetriken, en mear. Op dizze manier kinne jo maklik beoardielje dat de syntetyske gegevens dy't wy leverje fan 'e heechste kwaliteit binne en kinne wurde brûkt mei itselde nivo fan krektens en betrouberens as jo orizjinele gegevens.
In glimp fangen: dizze seksje yllustrearret hichtepunten út ús syntetyske gegevenskwaliteitsrapport. Us beoardielingen ûndersykje de syntetyske gegevens yn ferliking mei de echte gegevens oer ferskate dimensjes.
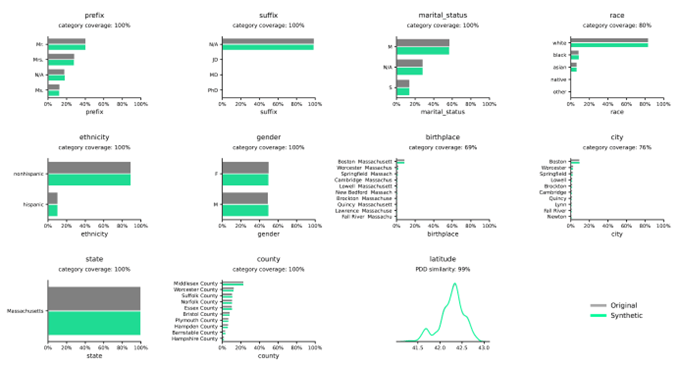
Syntetyske gegevensdistribúsjes yn ferliking mei echte gegevens
Distribúsjes yllustrearje de frekwinsje fan fariabelen binnen opjûne kategoryen of wearden en wurde sekuer fêstlein troch de Syntho Engine.
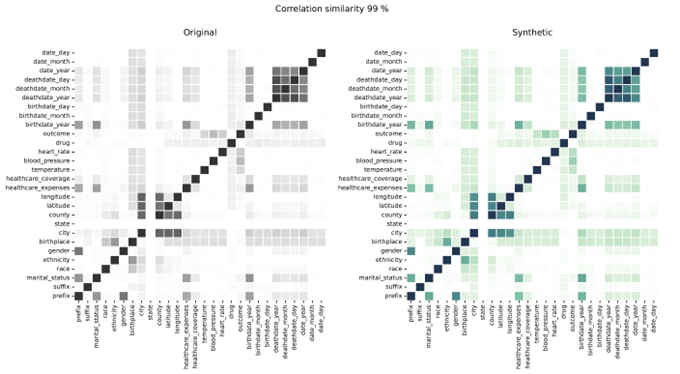
Syntetyske gegevenskorrelaasjes yn ferliking mei echte gegevens
Korrelaasjes litte de relaasje tusken fariabelen sjen, yllustrearje de mjitte wêryn't fariabelen besibbe binne. De Syntho Engine vangt dizze relaasjes krekt.
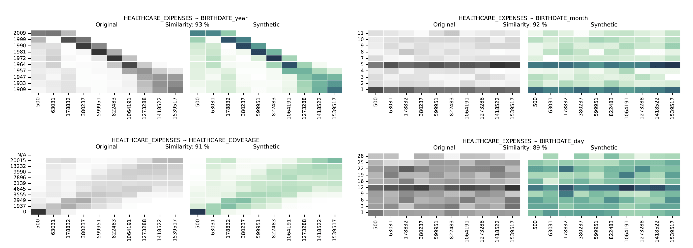
Syntetyske gegevens Multivariate Distributions yn ferliking mei echte gegevens
Multivariate distribúsjes en multifariate korrelaasjes bringe ús fierder as ientallige diminsjes, en jouwe in wiidweidich sicht fan hoe't meardere fariabelen besibbe binne. De Syntho Engine vangt dizze relaasjes.
Syntetyske gegevensgeneraasje is kompleks en pitfalls bestean en moatte wurde kontrolearre foar. Mei AI-algoritmen is overfitting in risiko en dit is ek it gefal foar syntetyske gegevensgeneraasje mei AI. Dêrom moat men kontrolearje foar it risiko fan overfitting by it generearjen fan syntetyske gegevens. It risiko fan overfitting wurdt kontrolearre foar yn 'e Syntho Engine. Dêrnjonken lit it rapport fan Syntho Quality Assurance (QA) organisaasjes sjen litte dat de syntetyske gegevens net oerfit hawwe op 'e orizjinele gegevens. Wy beoardielje ek mear privacy-relatearre aspekten, dy't faak wurde brûkt troch ynterne auditors.
Test op "eksakte oerienkomsten" mei de identike wedstriidferhâlding (IMR)
Demonstraasje dat de ferhâlding fan 'e syntetyske gegevensrecords dy't oerienkomme mei in echte rekord fan' e orizjinele gegevens net signifikant grutter is as de ferhâlding dy't kin wurde ferwachte by it analysearjen fan de treingegevens.
Test op "Soarlike wedstriden" mei de Distance to Closest Record (DCR)
Demonstraasje dat de normalisearre ôfstân foar syntetyske gegevensrecords nei har tichtste werklike rekord binnen de orizjinele gegevens net signifikant tichterby is dan de ôfstân dy't kin wurde ferwachte by it analysearjen fan de treingegevens.
Test op "Outliers" mei de Nearest Neighbour Distance Ratio (NNDR)
Demonstraasje dat de ôfstânferhâlding tusken it tichtste en op ien neiste syntetyske rekord nei har tichtste rekord binnen de oarspronklike gegevens net signifikant tichterby is as de ferhâlding dy't te ferwachtsjen is foar de treingegevens.
Dit is mar in momintopname dy't de essinsje gearfettet fan ús ferkenning en kwaliteitsfersekering foar syntetyske gegevenskwaliteit. It biedt in nuansearre begryp fan distribúsjes, korrelaasjes en multivariate distribúsjes as ûnderdiel fan syntetyske gegevens lykas fêstlein troch de avansearre mooglikheden fan 'e Syntho Engine. Mear details oer ús rapport oer kwaliteitsfersekering binne op oanfraach beskikber.