AI-generearre syntetyske gegevens, maklike en rappe tagong ta gegevens fan hege kwaliteit?
AI generearre syntetyske gegevens yn 'e praktyk
Syntho, in ekspert yn AI-generearre syntetyske gegevens, is fan doel om te draaien privacy by design yn in kompetitive foardiel mei AI-generearre syntetyske gegevens. Se helpe organisaasjes om in sterke databasis op te bouwen mei maklike en snelle tagong ta gegevens fan hege kwaliteit en wûnen koartlyn de Philips Innovation Award.
Syntetyske gegevensgeneraasje mei AI is lykwols in relatyf nije oplossing dy't typysk faak stelde fragen yntrodusearret. Om dizze te beantwurdzjen begon Syntho in case-stúdzje tegearre mei SAS, merklieder yn Advanced Analytics en AI-software.
Yn gearwurking mei de Nederlânske AI Koalysje (NL AIC) ûndersochten se de wearde fan syntetyske gegevens troch AI-generearre syntetyske gegevens te fergelykjen troch de Syntho Engine mei orizjinele gegevens fia ferskate beoardielingen oer gegevenskwaliteit, juridyske jildichheid en brûkberens.
Is anonymisaasje fan gegevens gjin oplossing?
Klassike anonimisearringstechniken hawwe it mienskiplik dat se orizjinele gegevens manipulearje om it opspoaren fan persoanen te hinderjen. Foarbylden binne generalisaasje, ûnderdrukking, wiskjen, pseudonymisaasje, gegevensmaskering, en skodzjen fan rigen en kolommen. Jo kinne foarbylden fine yn 'e tabel hjirûnder.
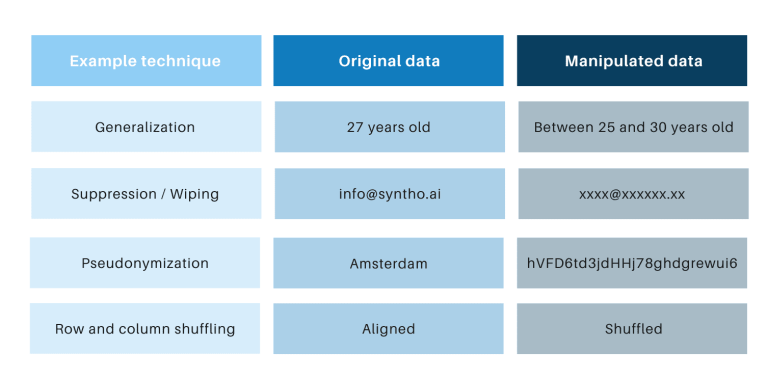
Dy techniken yntrodusearje 3 wichtige útdagings:
- Se wurkje oars per gegevenstype en per dataset, wêrtroch't se dreech te skaaljen binne. Fierder, om't se oars wurkje, sil d'r altyd diskusje wêze oer hokker metoaden moatte wurde tapast en hokker kombinaasje fan techniken nedich binne.
- D'r is altyd in ien-op-ien relaasje mei de oarspronklike gegevens. Dit betsjut dat d'r altyd in privacyrisiko sil wêze, benammen troch alle iepen datasets en beskikbere techniken om dy datasets te keppeljen.
- Se manipulearje gegevens en ferneatigje dêrmei gegevens yn it proses. Dit is benammen ferneatigjend foar AI-taken wêr't "foarsizzende krêft" essensjeel is, om't gegevens fan minne kwaliteit sille resultearje yn minne ynsjoggen fan it AI-model (Garbage-in sil resultearje yn garbage-out).
Dizze punten wurde ek beoardiele fia dizze case study.
In ynlieding ta de case study
Foar de saakstúdzje wie de doelgegevensset in telekom-dataset levere troch SAS mei de gegevens fan 56.600 klanten. De dataset befettet 128 kolommen, wêrûnder ien kolom dy't oanjout oft in klant it bedriuw ferlitten hat (dus 'kromme') of net. It doel fan 'e saakstúdzje wie om de syntetyske gegevens te brûken om guon modellen te trenen om klantferwachting te foarsizzen en de prestaasjes fan dy oplaat modellen te evaluearjen. Om't churnfoarsizzing in klassifikaasjetaak is, selektearre SAS fjouwer populêre klassifikaasjemodellen om de foarsizzingen te meitsjen, ynklusyf:
- Willekeurich bosk
- Gradientfergrutting
- Logistyske regression
- Neuronale netwurk
Foardat de syntetyske gegevens generearje, splitte SAS de telekomdataset willekeurich yn in treinset (foar it oplieden fan de modellen) en in holdout-set (foar it skoaren fan de modellen). It hawwen fan in aparte holdout-set foar skoare makket in ûnbidige beoardieling mooglik foar hoe goed it klassifikaasjemodel kin prestearje as it wurdt tapast op nije gegevens.
Mei de treinset as ynfier brûkte Syntho syn Syntho Engine om in syntetyske dataset te generearjen. Foar benchmarking makke SAS ek in manipulearre ferzje fan 'e treinset nei it tapassen fan ferskate anonymisaasjetechniken om in bepaalde drompel (fan k-anonimiteit) te berikken. De eardere stappen resultearren yn fjouwer datasets:
- In trein dataset (dws de orizjinele dataset minus de holdout dataset)
- In holdout dataset (dat wol sizze in subset fan de oarspronklike dataset)
- In anonymisearre dataset (basearre op de treindataset)
- In syntetyske dataset (basearre op de trein dataset)
Datasets 1, 3 en 4 waarden brûkt om elk klassifikaasjemodel te trenen, wat resultearre yn 12 (3 x 4) trained modellen. SAS brûkte dêrnei de holdout-dataset om de krektens te mjitten wêrmei't elk model de churn fan klanten foarseit. De resultaten wurde hjirûnder presintearre, begjinnend mei wat basisstatistiken.
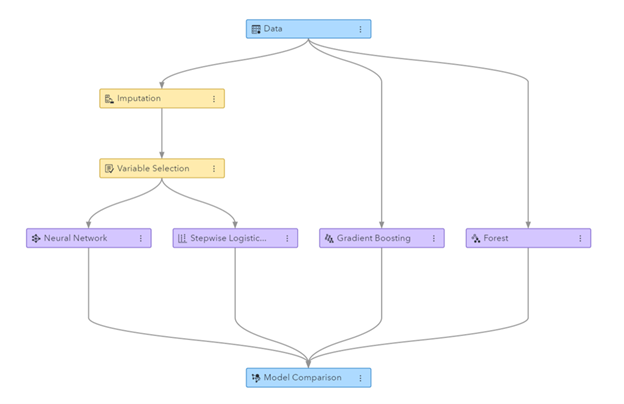
Ofbylding: Machine Learning pipeline generearre yn SAS Visual Data Mining en Machine Learning
Basisstatistiken by it fergelykjen fan anonymisearre gegevens mei orizjinele gegevens
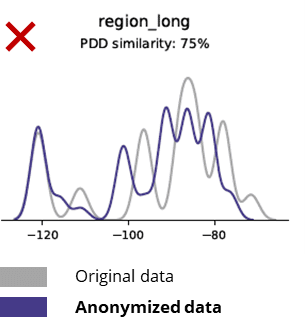
Anonymisaasjetechniken ferneatigje sels basispatroanen, saaklike logika, relaasjes en statistiken (lykas yn it foarbyld hjirûnder). It brûken fan anonymisearre gegevens foar basisanalytyk produseart sa ûnbetroubere resultaten. Yn feite makke de minne kwaliteit fan 'e anonymisearre gegevens it hast ûnmooglik om it te brûken foar avansearre analytyske taken (bygelyks AI / ML-modellering en dashboarding).
Basisstatistiken by it fergelykjen fan syntetyske gegevens mei orizjinele gegevens
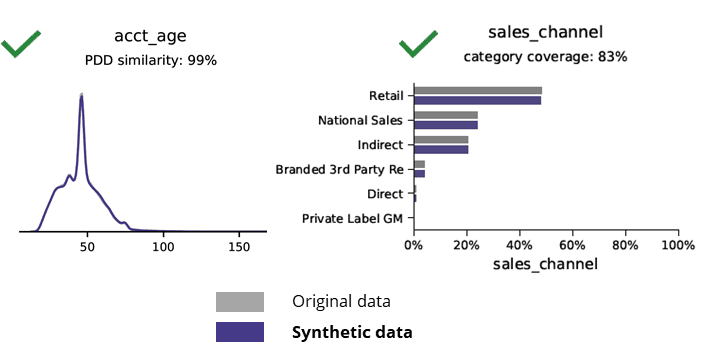
Syntetyske gegevensgeneraasje mei AI behâldt basispatroanen, saaklike logika, relaasjes en statistiken (lykas yn it foarbyld hjirûnder). It brûken fan syntetyske gegevens foar basisanalytyk produseart sa betroubere resultaten. Key fraach, hâldt syntetyske gegevens foar avansearre analytyske taken (bygelyks AI / ML modellering en dashboarding)?
AI-generearre syntetyske gegevens en avansearre analytics
Syntetyske gegevens jilde net allinich foar basispatroanen (lykas werjûn yn 'e eardere plots), it fange ek djippe 'ferburgen' statistyske patroanen dy't nedich binne foar avansearre analytyske taken. Dat lêste wurdt oantoand yn it staafdiagram hjirûnder, wat oanjout dat de krektens fan modellen oplaat op syntetyske gegevens fersus modellen oplaat op orizjinele gegevens ferlykber binne. Fierder, mei in gebiet ûnder de kromme (AUC*) tichtby 0.5, prestearje de modellen oplaat op anonymisearre gegevens fierwei it minste. It folsleine rapport mei alle avansearre analytyske beoardielingen oer syntetyske gegevens yn ferliking mei de orizjinele gegevens is op oanfraach beskikber.
*AUC: it gebiet ûnder de kromme is in maatregel foar de krektens fan avansearre analytyske modellen, rekken hâldend mei wiere positive, falske positive, falske negativen en wiere negativen. 0,5 betsjut dat in model willekeurich foarsizze en gjin foarsizzende krêft hat en 1 betsjut dat it model altyd korrekt is en folsleine foarsizzende krêft hat.
Derneist kinne dizze syntetyske gegevens wurde brûkt om gegevenseigenskippen en haadfariabelen te begripen dy't nedich binne foar werklike training fan 'e modellen. De yngongen selekteare troch de algoritmen op syntetyske gegevens yn ferliking mei orizjinele gegevens wiene heul ferlykber. Hjirtroch kin it modellearingsproses wurde dien op dizze syntetyske ferzje, wat it risiko op gegevensbrekken ferminderet. By it konkludearjen fan yndividuele records (bgl. telco-klant) wurdt lykwols retraining op orizjinele gegevens oanrikkemandearre foar ferklearring, ferhege akseptaasje of gewoan fanwege regeljouwing.
AUC troch Algoritme groepearre troch Metoade
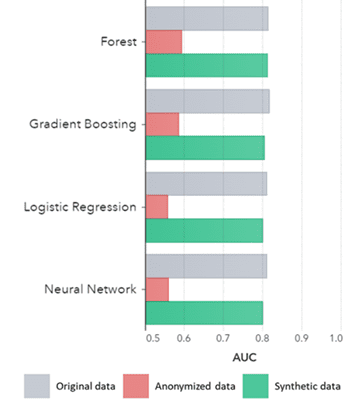
Konklúzjes:
- Modellen oplaat op syntetyske gegevens yn ferliking mei de modellen oplaat op orizjinele gegevens litte heul ferlykbere prestaasjes sjen
- Modellen oplaat op anonymisearre gegevens mei 'klassike anonimisearringstechniken' litte mindere prestaasjes sjen yn ferliking mei modellen oplaat op 'e orizjinele gegevens as syntetyske gegevens
- Syntetyske gegevensgeneraasje is maklik en fluch, om't de technyk krekt itselde wurket per dataset en per gegevenstype.
Gefallen foar gebrûk fan syntetyske gegevens dy't wearde tafoegje
Gebrûk 1: Syntetyske gegevens foar modelûntwikkeling en avansearre analytyk
In sterke gegevensbasis hawwe mei maklike en rappe tagong ta brûkbere gegevens fan hege kwaliteit is essensjeel foar it ûntwikkeljen fan modellen (bgl. dashboards [BI] en avansearre analytyk [AI & ML]). In protte organisaasjes lije lykwols oan in suboptimale gegevensstifting, wat resulteart yn 3 wichtige útdagings:
- Tagong krije ta gegevens duorret leeftiden fanwegen (privacy) regeljouwing, ynterne prosessen of datasilo's
- Klassike anonimisearringstechniken ferneatigje gegevens, wêrtroch't de gegevens net langer geskikt binne foar analyse en avansearre analytyk (garbage in = garbage out)
- Besteande oplossingen binne net skalberber, om't se oars wurkje per dataset en per gegevenstype en kinne gjin grutte multi-tabel databases behannelje
Syntetyske gegevensoanpak: modellen ûntwikkelje mei syntetyske gegevens sa goed as wirklik om:
- Minimalisearje it gebrûk fan orizjinele gegevens, sûnder jo ûntwikkelders te hinderjen
- Untskoattelje persoanlike gegevens en hawwe tagong ta mear gegevens dy't earder waarden beheind (bygelyks fanwegen privacy)
- Maklik en fluch tagong ta gegevens ta relevante gegevens
- Skaalbere oplossing dy't itselde wurket foar elke dataset, datatype en foar massive databases
Hjirmei kin organisaasje in sterke gegevensbasis bouwe mei maklike en rappe tagong ta brûkbere gegevens fan hege kwaliteit om gegevens te ûntsluten en gegevensmooglikheden te benutten.
Gebrûk 2: tûke syntetyske testgegevens foar softwaretesten, ûntwikkeling en levering
Testen en ûntwikkeling mei testgegevens fan hege kwaliteit is essensjeel foar it leverjen fan state-of-the-art softwareoplossingen. It brûken fan orizjinele produksjegegevens liket fanselssprekkend, mar is net tastien fanwegen (privacy)regels. Alternatyf Test Data Management (TDM) ark yntrodusearje "legacy-by-design" om de testgegevens goed te krijen:
- Net wjerspegelje produksjegegevens en saaklike logika en referinsjele yntegriteit wurde net bewarre
- Wurk stadich en tiidslinend
- Hânwurk is ferplicht
Syntetyske data-oanpak: Test en ûntwikkelje mei AI-genereare syntetyske testgegevens om moderne softwareoplossingen smart te leverjen mei:
- Produksje-like gegevens mei bewarre saaklike logika en referinsjele yntegriteit
- Maklike en rappe gegevensgeneraasje mei state-of-the-art AI
- Privacy-by-ûntwerp
- Maklik, fluch en agile
Dit makket it mooglik organisaasje te testen en ûntwikkeljen mei folgjende-nivo test gegevens te leverjen state-of-the-art software oplossings!
Mear ynformaasje
Ynteressearre? Sjoch foar mear ynformaasje oer syntetyske gegevens op de webside fan Syntho of nim kontakt op mei Wim Kees Janssen. Foar mear ynformaasje oer SAS, besykje www.sas.com of nim kontakt op mei kees@syntho.ai.
Yn dit gefal wurkje Syntho, SAS en de NL AIC gear om de beëage resultaten te berikken. Syntho is in ekspert yn AI-generearre syntetyske gegevens en SAS is in merklieder yn analytyk en biedt software foar it ferkennen, analysearjen en fisualisearjen fan gegevens.
* Foarsizze 2021 - Gegevens- en analysestrategyen om digitaal bedriuw te bestjoeren, skaaljen en transformearjen, Gartner, 2020.

Bewarje jo gids foar syntetyske gegevens no!
- Wat binne syntetyske gegevens?
- Wêrom brûke organisaasjes it?
- Wearde tafoeging syntetyske gegevens client gefallen
- Hoe te begjinnen
