داده های تست چیست: اهمیت، کاربردها و چالش ها
فهرست مندرجات
داده های تست در تست نرم افزار چیست؟
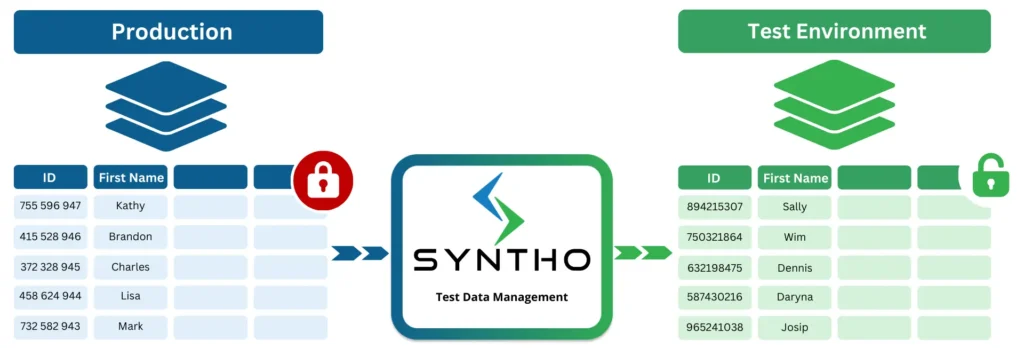
به زبان ساده، تعریف داده های تست این است: داده های تست انتخاب شده است مجموعه داده ها برای یافتن ایرادات و اطمینان از اینکه نرم افزار همانطور که باید کار می کند استفاده می شود.
آزمایش کنندگان و مهندسان به آنها تکیه می کنند مجموعه داده های تستچه به صورت دستی مونتاژ شده باشد و چه به صورت تخصصی تست ابزارهای تولید داده، برای تأیید عملکرد نرم افزار، ارزیابی عملکرد و تقویت امنیت.
با بسط این مفهوم، داده های تست در تست چیست? فراتر از صرف مجموعه داده ها، داده های آزمایشی شامل طیفی از مقادیر ورودی، سناریوها و شرایط است. این عناصر به دقت انتخاب می شوند تا تأیید کنند که آیا محصولات تحویلی معیارهای دقیق کیفیت و عملکرد مورد انتظار از نرم افزار را برآورده می کنند یا خیر.
برای درک بهتر تعریف داده های تست، بیایید انواع مختلف داده های آزمایشی را بررسی کنیم.
انواع داده های تست چیست؟
در حالی که هدف اولیه از آزمایش داده ها این است که اطمینان حاصل شود که نرم افزار همانطور که انتظار می رود رفتار می کند، عوامل موثر بر عملکرد نرم افزار بسیار متفاوت است. این تنوع به این معنی است که آزمایش کنندگان باید از انواع مختلف داده ها برای ارزیابی رفتار سیستم در شرایط مختلف استفاده کنند.
بنابراین، بیایید به این سوال پاسخ دهیم -داده های تست در تست نرم افزار چیست؟—با مثال.
- داده های تست مثبت برای آزمایش نرمافزار در شرایط عملیاتی معمولی استفاده میشود، بهعنوان مثال، برای بررسی اینکه آیا خودرو بدون هیچ مانعی در جادههای هموار بدون هیچ مانعی حرکت میکند یا خیر.
- داده های تست منفی مانند تست عملکرد خودرو با خرابی قطعات یدکی خاص است. این کمک می کند تا تشخیص دهیم که نرم افزار چگونه به آن پاسخ می دهد داده های نامعتبر ورودی ها یا اضافه بار سیستم
- داده های آزمون کلاس هم ارزی به نمایش رفتار یک گروه یا دسته خاص در نرم افزار کمک می کند تا به ویژه نحوه برخورد نرم افزار با انواع مختلف کاربران یا ورودی ها را آزمایش کند.
- داده های تست تصادفی بدون هیچ الگوی خاصی تولید می شود. این کمک می کند تا اطمینان حاصل شود که نرم افزار می تواند سناریوهای غیرمنتظره را به راحتی مدیریت کند.
- داده های آزمون مبتنی بر قانون بر اساس قوانین یا معیارهای از پیش تعریف شده تولید می شود. در یک برنامه بانکی، میتوان دادههای تراکنش را تولید کرد تا اطمینان حاصل شود که همه تراکنشها الزامات قانونی خاصی را برآورده میکنند یا مانده حساب در محدودههای مشخص باقی میماند.
- داده های تست مرزی بررسی می کند که نرم افزار چگونه مقادیر را در انتهای محدوده های قابل قبول مدیریت می کند. این شبیه به فشار دادن برخی از تجهیزات به حد مطلق است.
- داده های آزمون رگرسیون برای بررسی اینکه آیا تغییرات اخیر در نرم افزار باعث ایجاد نقص یا مشکلات جدید شده است استفاده می شود.
با استفاده از این متفاوت انواع داده های تست، متخصصان QA می توانند به طور موثر ارزیابی کنند که آیا نرم افزار طبق برنامه عمل می کند یا خیر، نقاط ضعف یا اشکال را مشخص کرده و در نهایت عملکرد سیستم را افزایش دهند.
اما تیم های نرم افزاری از کجا می توانند این داده ها را به دست آورند؟ بیایید در ادامه در مورد آن بحث کنیم.
داده های تست چگونه ایجاد می شوند؟
شما سه گزینه زیر را دارید ایجاد داده های آزمایشی برای پروژه شما:
- داده ها را از پایگاه داده موجود انتخاب کنید و اطلاعات مشتری مانند اطلاعات شناسایی شخصی (PII) را پنهان کنید.
- به صورت دستی ایجاد کنید داده های آزمون واقعی با برنامه های داده مبتنی بر قانون.
- داده های مصنوعی تولید کنید.
بسیاری از تیم های مهندسی داده تنها بر یکی از رویکردها تکیه می کنند و اغلب وقت گیرترین و پر زحمت ترین روش را انتخاب می کنند. تولید داده های آزمایشی. به عنوان مثال، هنگام چیدن داده های نمونه از پایگاههای داده موجود، تیمهای مهندسی ابتدا باید آن را از منابع متعدد استخراج کنند، سپس آن را قالببندی، پاکسازی و ماسک کنند تا برای محیطهای توسعه یا آزمایش مناسب شوند.
چالش دیگر این است که اطمینان حاصل شود که داده ها با معیارهای آزمایشی خاص مطابقت دارند: دقت، تنوع، ویژگی یک راه حل خاص، کیفیت بالا و انطباق با مقررات حفاظت از داده های شخصی. با این حال، این چالش ها به طور موثر توسط مدرن مورد توجه قرار می گیرند test data management رویکردهایی مانند تولید خودکار داده های آزمایشی.
پلت فرم Syntho طیف وسیعی از قابلیت ها را برای مقابله با این چالش ها ارائه می دهد، از جمله:
- شناسایی هوشمند زمانی که یک ابزار به طور خودکار همه PII را شناسایی می کند و در زمان و تلاش کارشناسان صرفه جویی می کند.
- کار بر روی اطلاعات حساس با جایگزینی PII و سایر شناسهها با مصنوعی داده های ساختگی که با منطق و الگوهای تجاری هماهنگ است.
- حفظ یکپارچگی ارجاعی با نگاشت ثابت داده ها در پایگاه داده ها و سیستم ها.
ما این قابلیت ها را با جزئیات بیشتری بررسی خواهیم کرد. اما ابتدا اجازه دهید به موضوعات مرتبط با آن بپردازیم ایجاد داده های آزمایشی بنابراین شما از آنها آگاه هستید و می دانید چگونه به آنها رسیدگی کنید.
تست چالش های داده در تست نرم افزار
سپارش داده های آزمون معتبر سنگ بنای آزمایش موثر است. با این حال، تیم های مهندسی در راه رسیدن به نرم افزار قابل اعتماد با چالش های زیادی روبرو هستند.
منابع داده پراکنده
دادهها، بهویژه دادههای سازمانی، در منابع بیشماری از جمله رایانههای اصلی قدیمی، SAP، پایگاههای داده رابطهای، NoSQL و محیطهای ابری متنوع قرار دارند. این پراکندگی، همراه با طیف گسترده ای از فرمت ها، پیچیده است دسترسی به داده های تولید برای تیم های نرم افزاری همچنین روند دریافت داده های مناسب برای آزمایش و نتایج را کند می کند داده های تست نامعتبر.
زیرمجموعه برای تمرکز
تیم های مهندسی اغلب با تقسیم مجموعه داده های آزمایشی بزرگ و متنوع به زیرمجموعه های کوچکتر و هدفمند مشکل دارند. اما این یک کار ضروری است زیرا این جدایی به آنها کمک می کند تا روی موارد خاصی تمرکز کنند موارد آزمون، تولید مجدد و رفع مشکلات را آسان تر می کند و در عین حال حجم داده های آزمایشی و هزینه های مربوطه را پایین نگه می دارد.
به حداکثر رساندن پوشش تست
مهندسان همچنین مسئول اطمینان از اینکه داده های تست به اندازه کافی جامع هستند تا به طور کامل تعریف شده باشند، مسئول هستند موارد آزمون، تراکم نقص را به حداقل می رساند و قابلیت اطمینان نرم افزار را تقویت می کند. با این حال، آنها در این تلاش به دلیل عوامل مختلفی مانند پیچیدگی سیستم، منابع محدود، تغییرات در نرم افزار، حفظ حریم خصوصی و امنیت داده ها و مسائل مقیاس پذیری با چالش هایی روبرو هستند.
واقع گرایی در داده های آزمون
جستوجوی واقعگرایی در دادههای آزمایشی نشان میدهد که آینهسازی اصلی چقدر مهم است مقادیر داده با نهایت وفاداری داده های تست باید شباهت زیادی به محیط تولید داشته باشند تا از مثبت یا منفی کاذب جلوگیری شود. اگر این واقع گرایی محقق نشود، می تواند به کیفیت و قابلیت اطمینان نرم افزار آسیب برساند. با توجه به آن، متخصصان باید به جزئیات توجه زیادی داشته باشند داده های تست را آماده کنید
تازه سازی و نگهداری داده ها
داده های تست باید به طور مرتب به روز شوند تا تغییرات در محیط تولید و الزامات برنامه را منعکس کنند. با این حال، این وظیفه با چالش های قابل توجهی همراه است، به ویژه در محیط هایی که دسترسی به داده ها به دلیل رعایت مقررات محدود است. هماهنگ کردن چرخههای بهروزرسانی دادهها و اطمینان از سازگاری دادهها در محیطهای آزمایشی به تلاشهای پیچیدهای تبدیل میشوند که هماهنگی دقیق و اقدامات انطباق دقیق را میطلبد.
چالش ها با داده های آزمون واقعی
طبق نظرسنجی Syntho در لینکدین، 50 درصد از شرکت ها از داده های تولید استفاده می کنندو 22 درصد از داده های پوشانده شده برای آزمایش نرم افزار خود استفاده می کنند. آنها انتخاب می کنند داده های واقعی همانطور که به نظر می رسد یک تصمیم آسان است: کپی کنید داده های موجود از محیط تولید، آن را در محیط تست چسبانده و در صورت نیاز از آن استفاده کنید.
با این حال، با استفاده از واقعی داده ها برای آزمایش چالش های متعددی از جمله:
- از پوشاندن داده ها برای مطابقت با مقررات حفظ حریم خصوصی داده ها اجتناب کنید امنیت داده ها نقض می کند و به قوانین منع استفاده از داده های واقعی برای اهداف آزمایشی پایبند است.
- برازش داده ها در محیط آزمایش که معمولاً با محیط تولید متفاوت است.
- به روز رسانی منظم پایگاه های داده به اندازه کافی
علاوه بر این چالش ها، شرکت ها در هنگام انتخاب با سه موضوع مهم دست و پنجه نرم می کنند داده های واقعی برای آزمایش.
در دسترس بودن محدود
زمانی که توسعه دهندگان داده های تولید را در نظر می گیرند، داده های محدود، کمیاب یا از دست رفته رایج است داده های آزمون مناسب. دسترسی به داده های تست با کیفیت بالا، به ویژه برای سیستم ها یا سناریوهای پیچیده، به طور فزاینده ای دشوار می شود. این کمبود داده، فرآیندهای آزمایش و اعتبارسنجی جامع را مختل میکند و تلاشهای تست نرمافزار را کمتر مؤثر میکند.
مشکلات مربوط به انطباق
قوانین سختگیرانه حفظ حریم خصوصی داده ها مانند CPRA و GDPR نیاز به محافظت از PII در محیط های آزمایشی دارد و استانداردهای انطباق دقیقی را برای پاکسازی داده ها تحمیل می کند. در این زمینه، نام های واقعی، آدرس ها، شماره تلفن ها و SSN های موجود در داده های تولید در نظر گرفته می شوند فرمت های داده غیرقانونی.
نگرانی های حریم خصوصی
چالش انطباق واضح است: استفاده از داده های شخصی اصلی به عنوان داده های آزمایشی ممنوع است. برای رسیدگی به این موضوع و اطمینان از اینکه هیچ PII برای ساخت استفاده نشده است موارد آزمون، آزمایش کننده ها باید آن را دوباره بررسی کنند اطلاعات حساس قبل از استفاده از آن در محیط های آزمایشی، ضدعفونی یا ناشناس می شود. در حالی که برای امنیت داده ها، این کار وقت گیر می شود و لایه دیگری از پیچیدگی را برای تیم های آزمایش اضافه می کند.
اهمیت داده های تست کیفیت
داده های تست خوب به عنوان ستون فقرات کل فرآیند QA عمل می کند. این تضمین می کند که نرم افزار همانطور که باید عمل می کند، در شرایط مختلف به خوبی عمل می کند و از نفوذ اطلاعات و حملات مخرب در امان می ماند. با این حال، یک مزیت مهم دیگر نیز وجود دارد.
آیا با تست Shift-left آشنایی دارید؟ این رویکرد آزمایش را به سمت مراحل اولیه چرخه عمر توسعه سوق می دهد تا سرعت آن را کاهش ندهد agile روند. تست Shift-left زمان و هزینه های مربوط به آزمایش و اشکال زدایی را در مراحل بعدی با شناسایی و رفع مشکلات در مراحل اولیه کاهش می دهد.
برای اینکه تست شیفت چپ به خوبی کار کند، مجموعه دادههای تست منطبق لازم است. اینها به تیم های توسعه و QA کمک می کنند تا سناریوهای خاص را به طور کامل آزمایش کنند. اتوماسیون و ساده سازی فرآیندهای دستی در اینجا کلیدی است. شما می توانید با استفاده از آزمون مناسب، تدارک را سرعت بخشیده و با اکثر چالش هایی که در مورد آنها صحبت کردیم، مقابله کنید ابزارهای تولید داده با داده های مصنوعی
داده های مصنوعی به عنوان یک راه حل
مبتنی بر داده های مصنوعی test data management روش یک استراتژی نسبتا جدید اما کارآمد برای حفظ کیفیت در حین مقابله با چالش ها است. شرکت ها می توانند برای ایجاد سریع داده های آزمایشی با کیفیت بالا به تولید داده های مصنوعی تکیه کنند.
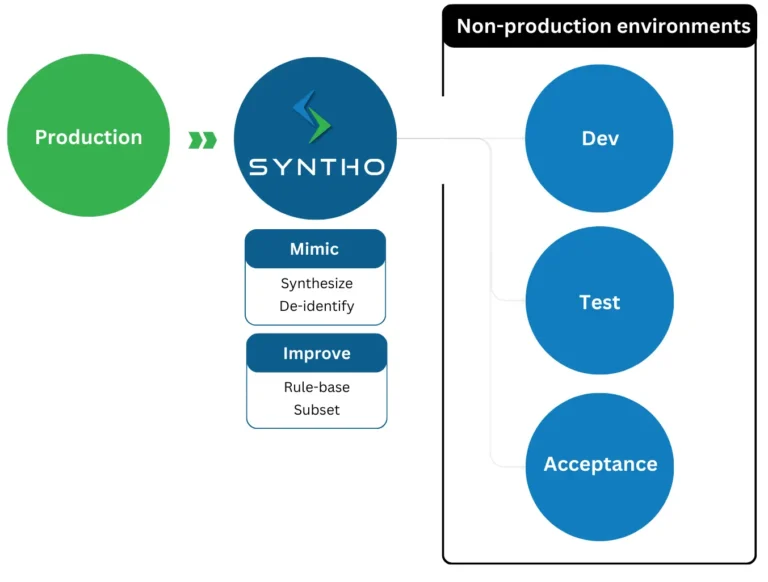
تعریف و خصوصیات
دادههای آزمایش مصنوعی دادههای تولید شده مصنوعی هستند که برای شبیهسازی محیطهای آزمایش داده برای توسعه نرمافزار طراحی شدهاند. با جایگزینی PII با داده های ساختگی بدون هیچ گونه اطلاعات حساس، داده های مصنوعی ایجاد می کند test data management سریعتر و آسان تر
داده های آزمایش مصنوعی خطرات حفظ حریم خصوصی را کاهش می دهد و همچنین به توسعه دهندگان اجازه می دهد عملکرد، امنیت و عملکرد برنامه را در طیف وسیعی از سناریوهای بالقوه بدون تأثیر بر سیستم واقعی ارزیابی دقیق کنند. اکنون، بیایید بررسی کنیم که ابزارهای داده مصنوعی چه کارهای دیگری می توانند انجام دهند.
به چالش های رعایت و حفظ حریم خصوصی رسیدگی کنید
بیایید راه حل Syntho را به عنوان مثال در نظر بگیریم. برای مقابله با چالشهای مربوط به رعایت و حفظ حریم خصوصی، ما از ابزارهای پیچیده استفاده میکنیم پوشش داده ها تکنیک ها همراه با پیشرفته ترین فناوری اسکن PII. اسکنر PII با هوش مصنوعی Syntho به طور خودکار هر ستونی را در پایگاه داده های کاربر حاوی PII های مستقیم شناسایی و پرچم گذاری می کند. این کار دستی را کاهش می دهد و تشخیص دقیق داده های حساس را تضمین می کند، خطر نقض داده ها و عدم رعایت مقررات حفظ حریم خصوصی را کاهش می دهد.
هنگامی که ستونهای دارای PII شناسایی میشوند، پلتفرم Syntho دادههای ساختگی را به عنوان بهترین روش شناساییزدایی در این مورد ارائه میدهد. این ویژگی با جایگزین کردن آن با دادههای ساختگی نماینده که هنوز یکپارچگی ارجاعی را برای اهداف آزمایش در پایگاههای داده و سیستمها حفظ میکنند، از PII اصلی حساس محافظت میکند. این از طریق به دست می آید قابلیت نقشه برداری سازگار، که تضمین می کند که داده های جایگزین با منطق و الگوهای تجاری مطابقت دارند و در عین حال با مقرراتی مانند GDPR و HIPAA مطابقت دارند.
ارائه تطبیق پذیری در تست
داده های آزمایشی همه کاره می تواند به شرکت ها کمک کند تا بر چالش دسترسی محدود داده ها غلبه کنند و پوشش آزمایشی را به حداکثر برسانند. پلتفرم Syntho از تطبیق پذیری با خود پشتیبانی می کند تولید داده های مصنوعی مبتنی بر قانون.
این مفهوم شامل ایجاد داده های آزمایشی با پیروی از قوانین و محدودیت های از پیش تعریف شده برای تقلید از داده های دنیای واقعی یا شبیه سازی سناریوهای خاص. تولید داده های مصنوعی مبتنی بر قانون، تطبیق پذیری را در آزمایش از طریق استراتژی های مختلف ارائه می دهد:
- تولید داده از ابتدا: دادههای مصنوعی مبتنی بر قانون، تولید دادهها را در زمانی که دادههای واقعی محدود یا بدون در دسترس هستند، ممکن میسازد. این تسترها و توسعه دهندگان را با داده های لازم مجهز می کند.
- غنی سازی داده ها: با افزودن ردیف ها و ستون های بیشتر، داده ها را غنی می کند و ایجاد مجموعه داده های بزرگتر را آسان تر می کند.
- انعطاف پذیری و سفارشی سازی: با رویکرد مبتنی بر قانون، میتوانیم انعطافپذیر بمانیم و با قالبها و ساختارهای دادههای مختلف سازگار شویم و دادههای مصنوعی متناسب با نیازها و سناریوهای خاص تولید کنیم.
- پاک کردن داده: این شامل پیروی از قوانین از پیش تعریف شده هنگام تولید داده ها برای اصلاح ناسازگاری ها، پر کردن مقادیر از دست رفته و حذف است. داده های تست خراب شده. تضمین می کند کیفیت داده و یکپارچگی، به ویژه زمانی که مجموعه داده اصلی حاوی نادرستی است که می تواند بر نتایج آزمایش تأثیر بگذارد، مهم است.
هنگام انتخاب صحیح ابزار تولید داده، ضروری است که عوامل خاصی را در نظر بگیرید تا مطمئن شوید که آنها واقعاً بار کاری را برای تیم شما کاهش می دهند.
ملاحظات هنگام انتخاب ابزارهای داده مصنوعی
انتخاب ابزارهای داده مصنوعی به نیازهای تجاری، قابلیت های یکپارچه سازی و الزامات حفظ حریم خصوصی داده ها بستگی دارد. در حالی که هر سازمان منحصر به فرد است، ما معیارهای کلیدی را برای انتخاب مصنوعی بیان کرده ایم ابزارهای تولید داده.
واقع گرایی داده ها
مطمئن شوید که ابزاری که در نظر گرفته اید داده های تست را تولید می کند بسیار شبیه به داده های دنیای واقعی است. تنها در این صورت است که به طور موثر سناریوهای مختلف آزمایش را شبیه سازی می کند و مشکلات احتمالی را تشخیص می دهد. این ابزار همچنین باید گزینه های سفارشی سازی را برای تقلید از توزیع های مختلف داده، الگوها و ناهنجاری ها در محیط های تولید ارائه دهد.
تنوع داده ها
به دنبال ابزارهایی باشید که می توانند تولید کنند داده های نمونه طیف وسیعی از موارد استفاده، از جمله انواع دادهها، فرمتها و ساختارهای مرتبط با نرمافزار مورد آزمایش را پوشش میدهد. این تنوع به تأیید اینکه آیا سیستم قوی است یا خیر کمک می کند و پوشش آزمایشی جامع را تضمین می کند.
مقیاس پذیری و عملکرد
بررسی کنید که ابزار چقدر می تواند حجم زیادی از داده های مصنوعی تولید کند، به ویژه برای آزمایش سیستم های پیچیده یا با حجم بالا. شما ابزاری میخواهید که بتواند نیازهای دادهای برنامههای کاربردی در مقیاس سازمانی را بدون به خطر انداختن عملکرد یا قابلیت اطمینان، افزایش دهد.
حریم خصوصی و امنیت داده ها
برای محافظت از اطلاعات حساس یا محرمانه هنگام تولید داده، ابزارهایی با ویژگی های داخلی را اولویت بندی کنید. به دنبال ویژگیهایی مانند ناشناسسازی دادهها و رعایت مقررات حفاظت از دادهها برای به حداقل رساندن خطرات حفظ حریم خصوصی و مطابقت با قانون باشید.
یکپارچگی و سازگاری
نرم افزاری را انتخاب کنید که به طور یکپارچه با تنظیمات آزمایشی موجود شما مطابقت داشته باشد تا پذیرش و ادغام آسان در گردش کار توسعه نرم افزار را تسهیل کند. ابزاری که با سیستمهای ذخیرهسازی دادههای مختلف، پایگاههای داده و پلتفرمهای آزمایشی سازگار باشد، همه کارهتر و استفاده آسانتر خواهد بود.
به عنوان مثال، Syntho پشتیبانی می کند بیش از 20 رابط پایگاه داده و 5+ اتصال دهنده سیستم فایل، از جمله گزینه های محبوب مانند Microsoft SQL Server، Amazon S3 و Oracle، که ایمنی داده ها و تولید آسان داده را تضمین می کند.
سفارشی سازی و انعطاف پذیری
به دنبال ابزارهایی باشید که گزینههای سفارشیسازی انعطافپذیر را برای تطبیق تولید دادههای مصنوعی با شرایط و سناریوهای آزمایشی خاص ارائه میدهند. پارامترهای قابل تنظیم، مانند قوانین، روابط و محدودیتهای تولید داده، به شما امکان میدهند دادههای تولید شده را برای مطابقت با معیارها و اهداف آزمایش تنظیم کنید.
به طور خلاصه
La معنی داده های آزمون در توسعه نرم افزار نمی توان اغراق کرد - این چیزی است که به ما کمک می کند نقص های عملکرد نرم افزار را شناسایی و اصلاح کنیم. اما مدیریت داده های تست فقط یک موضوع راحت نیست. برای رعایت مقررات و قوانین حفظ حریم خصوصی بسیار مهم است. انجام درست آن میتواند بار کاری را برای تیمهای توسعهتان کاهش دهد، در هزینهها صرفهجویی کند و محصولات را سریعتر به بازار عرضه کند.
اینجاست که داده های مصنوعی به کار می آیند. این دادههای واقعی و همهکاره را بدون کار زمانبر زیاد ارائه میکند و شرکتها را سازگار و ایمن نگه میدارد. با ابزارهای تولید داده مصنوعی، مدیریت داده های تست سریعتر و کارآمدتر می شود.
بهترین بخش این است که داده های آزمایش مصنوعی با کیفیت در دسترس هر شرکتی است، صرف نظر از اهداف آن. تنها کاری که باید انجام دهید این است که یک ارائه دهنده قابل اعتماد ابزارهای تولید داده مصنوعی پیدا کنید. امروز با Syntho تماس بگیرید و یک نسخه آزمایشی رایگان رزرو کنید ببینید که چگونه داده های مصنوعی می توانند برای تست نرم افزار شما مفید باشند.
درباره نویسندگان

مدیر ارشد محصول و یکی از بنیانگذاران
Marijn دارای پیشینه آکادمیک در علوم محاسبات، مهندسی صنایع و امور مالی است و از آن زمان تاکنون در نقشهای توسعه محصول نرمافزاری، تجزیه و تحلیل دادهها و امنیت سایبری موفق بوده است. Marijn اکنون به عنوان بنیانگذار و مدیر ارشد محصول (CPO) در Syntho عمل می کند و نوآوری و چشم انداز استراتژیک را در خط مقدم فناوری هدایت می کند.

اکنون راهنمای داده های مصنوعی خود را ذخیره کنید!
- داده های مصنوعی چیست؟
- چرا سازمان ها از آن استفاده می کنند؟
- موارد ارزش افزوده مشتری داده مصنوعی
- چگونه شروع کنیم
