

Докладът за осигуряване на качеството на Syntho оценява генерираните синтетични данни и демонстрира точността, поверителността и скоростта на синтетичните данни в сравнение с оригиналните данни.
В Syntho разбираме важността на надеждните и точни синтетични данни. Ето защо ние предоставяме изчерпателен отчет за осигуряване на качеството за всяко изпълнение на синтетични данни. Нашият отчет за качеството включва различни показатели като разпределения, корелации, многовариантни разпределения, показатели за поверителност и др. По този начин можете лесно да прецените, че синтетичните данни, които предоставяме, са с най-високо качество и могат да се използват със същото ниво на точност и надеждност като вашите оригинални данни.
Улавяне на бърз поглед: този раздел илюстрира акценти от нашия синтетичен отчет за качеството на данните. Нашите оценки разглеждат синтетичните данни в сравнение с реалните данни в различни измерения.
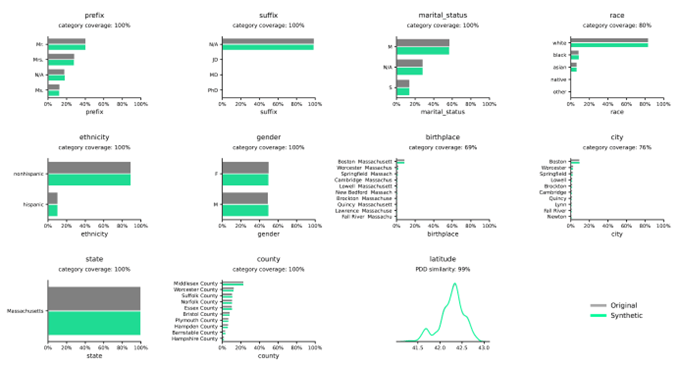
Разпределения на синтетични данни в сравнение с реални данни
Разпределенията илюстрират честотата на променливите в дадени категории или стойности и се улавят точно от Syntho Engine.
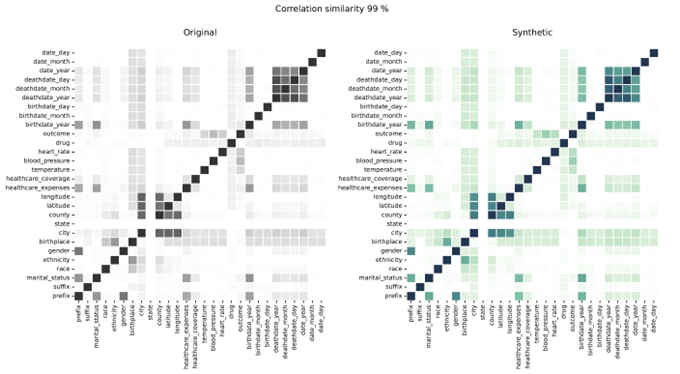
Корелации на синтетични данни в сравнение с реални данни
Корелациите показват връзката между променливите, илюстрирайки степента, в която променливите са свързани. Syntho Engine точно улавя тези взаимоотношения.
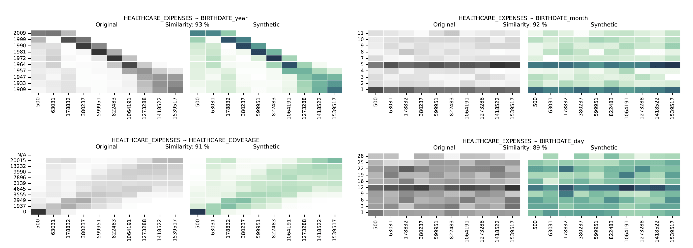
Многовариантни разпределения на синтетични данни в сравнение с реални данни
Многовариантните разпределения и многовариантните корелации ни отвеждат отвъд единичните измерения, предоставяйки цялостен поглед върху това как са свързани множество променливи. Syntho Engine улавя тези отношения.
Генерирането на синтетични данни е сложно и клопки съществуват и трябва да бъдат контролирани. При AI алгоритмите пренастройването е риск и това важи и за генерирането на синтетични данни с AI. Следователно трябва да се контролира рискът от пренастройване при генериране на синтетични данни. Рискът от пренастройване се контролира в Syntho Engine. На всичкото отгоре отчетът за осигуряване на качеството на Syntho (QA) позволява на организациите да демонстрират, че синтетичните данни не превишават оригиналните данни. Ние също така оценяваме по-скоро свързани с поверителността аспекти, които често се използват от вътрешните одитори.
Тествайте „Точни съвпадения“ с коефициента на идентично съвпадение (IMR)
Демонстрация, че съотношението на записите със синтетични данни, които съвпадат с реален запис от оригиналните данни, не е значително по-голямо от съотношението, което може да се очаква при анализиране на данните за влака.
Тествайте върху „Подобни съвпадения“ с разстоянието до най-близкия запис (DCR)
Демонстрация, че нормализираното разстояние за записи на синтетични данни до техния най-близък действителен запис в рамките на оригиналните данни не е значително по-близо от разстоянието, което може да се очаква при анализиране на данните за влака.
Тествайте върху „Изключителни“ с Съотношение на най-близкия съсед (NNDR)
Демонстрация, че съотношението на разстоянието между най-близкия и втория най-близък синтетичен запис до техния най-близък запис в оригиналните данни не е значително по-близко от съотношението, което трябва да се очаква за данните за влака.
Това е само моментна снимка, която обобщава същността на нашето изследване на качеството на синтетичните данни и доклад за осигуряване на качеството. Той предлага нюансирано разбиране на разпределенията, корелациите и многовариантните разпределения като част от синтетичните данни, уловени от разширените възможности на Syntho Engine. Повече подробности за нашия доклад за осигуряване на качеството са достъпни при поискване.