


Синтетичните данни, генерирани от Syntho, се оценяват, валидират и одобряват от външна и обективна гледна точка от експертите по данни на SAS.
Въпреки че Syntho се гордее да предложи на своите потребители усъвършенстван доклад за осигуряване на качеството, ние също така разбираме важността на наличието на външна и обективна оценка на нашите синтетични данни от лидери в индустрията. Ето защо ние си сътрудничим със SAS, лидер в анализите, за оценка на нашите синтетични данни.
SAS провежда различни задълбочени оценки на точността на данните, защитата на поверителността и използваемостта на генерираните от AI синтетични данни на Syntho в сравнение с оригиналните данни. Като заключение SAS оцени и одобри синтетичните данни на Syntho като точни, сигурни и използваеми в сравнение с оригиналните данни.
Използвахме данни от телекомуникациите, които се използват за прогнозиране на „отлив“ като целеви данни. Целта на оценката беше да се използват синтетични данни за обучение на различни модели за прогнозиране на отлив и да се оцени ефективността на всеки модел. Тъй като предвиждането на отлив е задача за класификация, SAS избра популярни модели за класификация, за да направи прогнозите, включително:
Преди да генерира синтетичните данни, SAS разделя на случаен принцип телекомуникационния набор от данни на набор от влакове (за обучение на моделите) и набор за задържане (за оценяване на моделите). Наличието на отделен набор за задържане за точкуване позволява безпристрастна оценка на това колко добре може да се справи моделът за класификация, когато се прилага към нови данни.
Използвайки набора от влакове като вход, Syntho използва своя Syntho Engine за генериране на синтетичен набор от данни. За сравнителен анализ SAS също създаде анонимна версия на комплекта влакове, след като приложи различни техники за анонимизиране, за да достигне определен праг (на k-анонимност). Предишните стъпки доведоха до четири набора от данни:
Набори от данни 1, 3 и 4 бяха използвани за обучение на всеки класификационен модел, което доведе до 12 (3 x 4) обучени модела. Впоследствие SAS използва набора от данни за задържане, за да измери точността на всеки модел при прогнозирането на оттока на клиентите.
SAS провежда различни задълбочени оценки на точността на данните, защитата на поверителността и използваемостта на генерираните от AI синтетични данни на Syntho в сравнение с оригиналните данни. Като заключение SAS оцени и одобри синтетичните данни на Syntho като точни, сигурни и използваеми в сравнение с оригиналните данни.
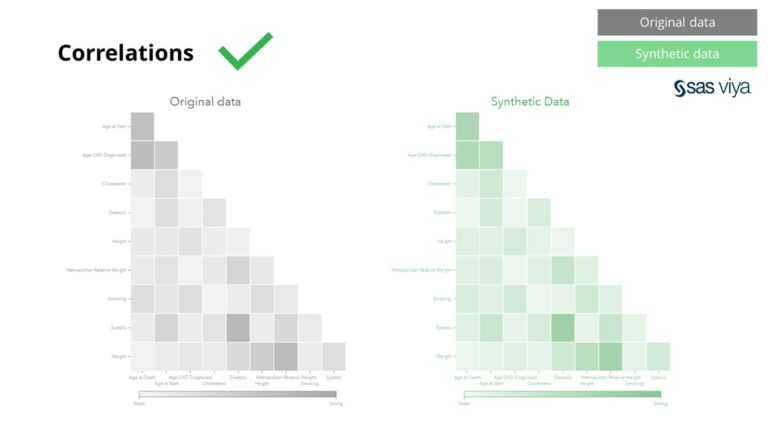
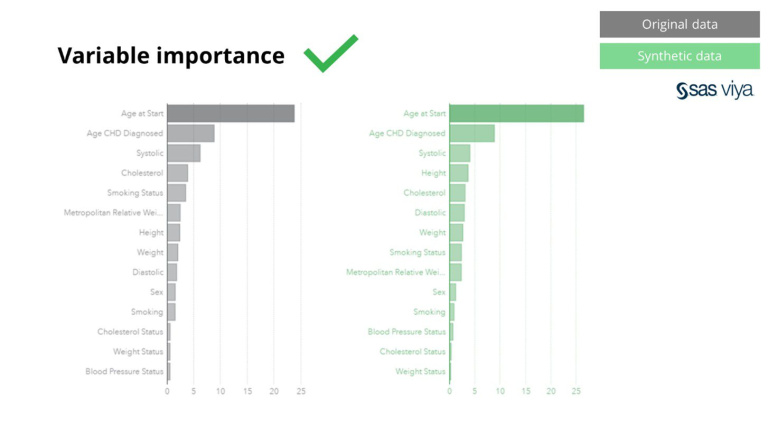
Синтетичните данни от Syntho съдържат не само основни модели, но също така улавят дълбоки „скрити“ статистически модели, необходими за задачи за разширен анализ. Последното е демонстрирано в лентовата диаграма, което показва, че точността на моделите, обучени на синтетични данни спрямо моделите, обучени на оригинални данни, е сходна. Следователно синтетичните данни могат да се използват за действително обучение на моделите. Входящите данни и променливата важност, избрани от алгоритмите за синтетични данни в сравнение с оригиналните данни, бяха много сходни. Следователно се заключава, че процесът на моделиране може да се извърши върху синтетични данни, като алтернатива за използване на реални чувствителни данни.
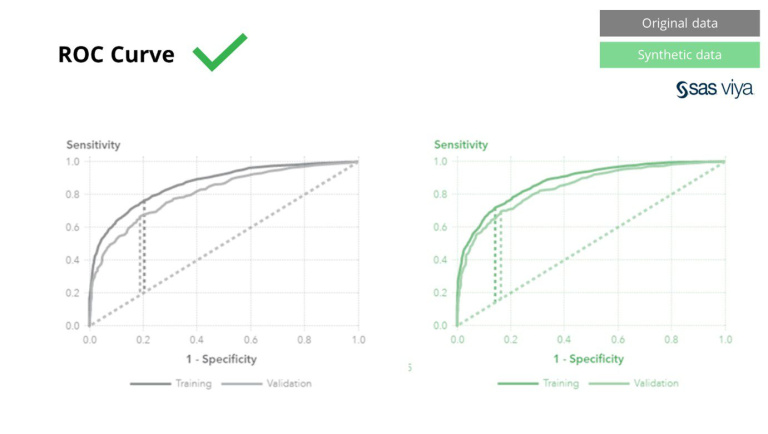
Класическите техники за анонимизиране имат общото, че манипулират оригиналните данни, за да възпрепятстват проследяването на лица. Те манипулират данни и по този начин унищожават данните в процеса. Колкото повече анонимизирате, толкова по-добре са защитени вашите данни, но и толкова повече данните ви се унищожават. Това е особено пагубно за AI и задачи за моделиране, където „силата на прогнозиране“ е от съществено значение, тъй като данните с лошо качество ще доведат до лоши прозрения от AI модела. SAS демонстрира това с площ под кривата (AUC*) близо до 0.5, демонстрирайки, че моделите, обучени на анонимизирани данни, се представят най-лошо.
Корелациите и връзките между променливите бяха точно запазени в синтетичните данни.
Площта под кривата (AUC), метрика за измерване на ефективността на модела, остана последователна.
Освен това важността на променливата, която показва предсказващата сила на променливите в модела, остава непокътната при сравняване на синтетични данни с оригиналния набор от данни.
Въз основа на тези наблюдения от SAS и чрез използването на SAS Viya, можем уверено да заключим, че синтетичните данни, генерирани от Syntho Engine, наистина са наравно с реалните данни по отношение на качеството. Това потвърждава използването на синтетични данни за разработване на модели, проправяйки пътя за усъвършенствани анализи със синтетични данни.
