


Dữ liệu tổng hợp do Syntho tạo ra được các chuyên gia dữ liệu của SAS đánh giá, xác thực và phê duyệt từ quan điểm bên ngoài và khách quan.
Mặc dù Syntho tự hào cung cấp cho người dùng báo cáo đảm bảo chất lượng nâng cao, chúng tôi cũng hiểu tầm quan trọng của việc có được đánh giá bên ngoài và khách quan về dữ liệu tổng hợp của chúng tôi từ các nhà lãnh đạo trong ngành. Đó là lý do tại sao chúng tôi cộng tác với SAS, công ty dẫn đầu về phân tích, để đánh giá dữ liệu tổng hợp của chúng tôi.
SAS tiến hành nhiều đánh giá kỹ lưỡng khác nhau về độ chính xác của dữ liệu, bảo vệ quyền riêng tư và khả năng sử dụng dữ liệu tổng hợp do AI tạo của Syntho so với dữ liệu gốc. Kết luận, SAS đã đánh giá và phê duyệt dữ liệu tổng hợp của Syntho là chính xác, an toàn và có thể sử dụng được so với dữ liệu gốc.
Chúng tôi đã sử dụng dữ liệu viễn thông được sử dụng để dự đoán “khuấy” làm dữ liệu mục tiêu. Mục tiêu của việc đánh giá là sử dụng dữ liệu tổng hợp để huấn luyện các mô hình dự đoán tỷ lệ rời bỏ khác nhau và đánh giá hiệu suất của từng mô hình. Vì dự đoán tỷ lệ rời bỏ là một nhiệm vụ phân loại nên SAS đã chọn các mô hình phân loại phổ biến để đưa ra dự đoán, bao gồm:
Trước khi tạo dữ liệu tổng hợp, SAS chia ngẫu nhiên tập dữ liệu viễn thông thành một tập hợp tàu (để huấn luyện các mô hình) và một tập hợp (để cho điểm các mô hình). Việc có một bộ lưu trữ riêng để cho điểm cho phép đánh giá khách quan về mức độ hoạt động của mô hình phân loại khi áp dụng cho dữ liệu mới.
Sử dụng tập hợp tàu làm đầu vào, Syntho sử dụng Công cụ Syntho của mình để tạo tập dữ liệu tổng hợp. Để đo điểm chuẩn, SAS cũng tạo ra một phiên bản ẩn danh của bộ tàu sau khi áp dụng các kỹ thuật ẩn danh khác nhau để đạt đến một ngưỡng nhất định (k-ẩn danh). Các bước trước đây dẫn đến bốn tập dữ liệu:
Bộ dữ liệu 1, 3 và 4 được sử dụng để huấn luyện từng mô hình phân loại, tạo ra 12 mô hình được huấn luyện (3 x 4). SAS sau đó đã sử dụng tập dữ liệu nắm giữ để đo lường độ chính xác của từng mô hình trong dự đoán tỷ lệ rời bỏ khách hàng.
SAS tiến hành nhiều đánh giá kỹ lưỡng khác nhau về độ chính xác của dữ liệu, bảo vệ quyền riêng tư và khả năng sử dụng dữ liệu tổng hợp do AI tạo của Syntho so với dữ liệu gốc. Kết luận, SAS đã đánh giá và phê duyệt dữ liệu tổng hợp của Syntho là chính xác, an toàn và có thể sử dụng được so với dữ liệu gốc.
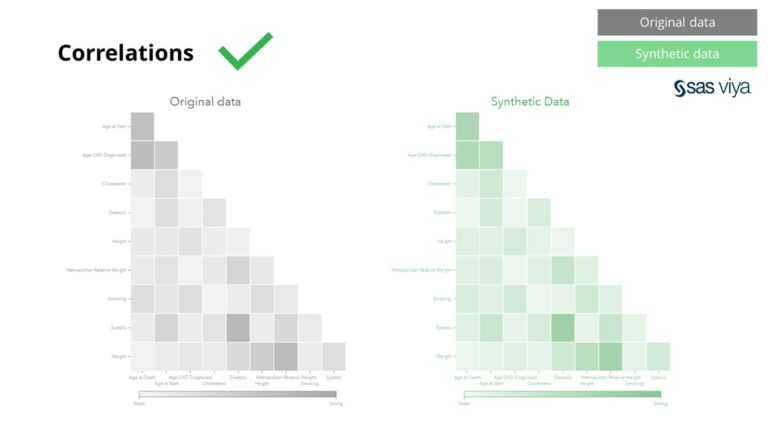
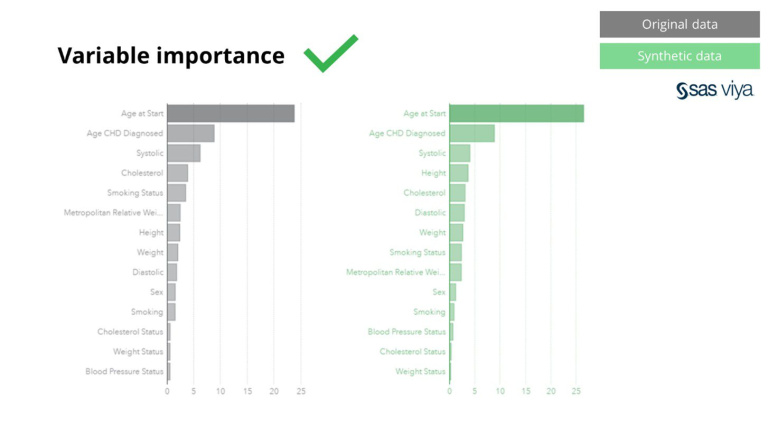
Dữ liệu tổng hợp từ Syntho không chỉ nắm giữ các mẫu cơ bản mà còn nắm bắt các mẫu thống kê 'ẩn' sâu cần thiết cho các tác vụ phân tích nâng cao. Điều thứ hai được thể hiện trong biểu đồ thanh, chỉ ra rằng độ chính xác của các mô hình được đào tạo trên dữ liệu tổng hợp so với các mô hình được đào tạo trên dữ liệu gốc là tương tự nhau. Do đó, dữ liệu tổng hợp có thể được sử dụng để huấn luyện mô hình thực tế. Đầu vào và tầm quan trọng của biến được lựa chọn bởi các thuật toán trên dữ liệu tổng hợp so với dữ liệu gốc rất giống nhau. Do đó, người ta kết luận rằng quy trình lập mô hình có thể được thực hiện trên dữ liệu tổng hợp, như một giải pháp thay thế cho việc sử dụng dữ liệu thực tế nhạy cảm.
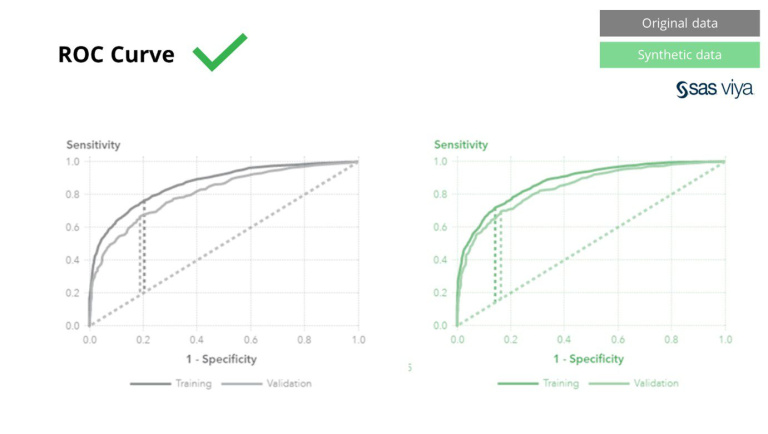
Các kỹ thuật ẩn danh cổ điển có điểm chung là chúng thao túng dữ liệu gốc để cản trở việc truy tìm các cá nhân. Họ thao túng dữ liệu và do đó phá hủy dữ liệu trong quá trình này. Bạn càng ẩn danh, dữ liệu của bạn càng được bảo vệ tốt hơn nhưng dữ liệu của bạn cũng bị phá hủy nhiều hơn. Điều này đặc biệt tàn phá đối với AI và các nhiệm vụ lập mô hình trong đó “sức mạnh dự đoán” là cần thiết, bởi vì dữ liệu chất lượng kém sẽ dẫn đến những hiểu biết sâu sắc về mô hình AI. SAS đã chứng minh điều này, với diện tích dưới đường cong (AUC*) gần bằng 0.5, chứng tỏ rằng các mô hình được đào tạo trên dữ liệu ẩn danh hoạt động kém nhất cho đến nay.
Các mối tương quan và mối quan hệ giữa các biến được bảo toàn chính xác trong dữ liệu tổng hợp.
Diện tích dưới đường cong (AUC), một thước đo để đo lường hiệu suất của mô hình, vẫn nhất quán.
Hơn nữa, tầm quan trọng của biến, biểu thị sức mạnh dự đoán của các biến trong một mô hình, vẫn còn nguyên vẹn khi so sánh dữ liệu tổng hợp với tập dữ liệu gốc.
Dựa trên những quan sát này của SAS và bằng cách sử dụng SAS Viya, chúng tôi có thể tự tin kết luận rằng dữ liệu tổng hợp do Syntho Engine tạo ra thực sự ngang bằng với dữ liệu thực về mặt chất lượng. Điều này xác nhận việc sử dụng dữ liệu tổng hợp để phát triển mô hình, mở đường cho các phân tích nâng cao với dữ liệu tổng hợp.
