Đoán xem là ai nào? 5 ví dụ tại sao xóa tên không phải là một tùy chọn



Đoán xem là ai nào? Mặc dù tôi chắc chắn rằng hầu hết các bạn đều biết trò chơi này từ ngày xưa, nhưng đây là một bản tóm tắt ngắn gọn. Mục tiêu của trò chơi: khám phá tên của nhân vật hoạt hình mà đối thủ của bạn chọn bằng cách hỏi các câu hỏi 'có' và 'không', như 'người đó có đội mũ không?' hay 'người đó có đeo kính không'? Người chơi loại bỏ các ứng cử viên dựa trên phản ứng của đối thủ và tìm hiểu các thuộc tính liên quan đến nhân vật bí ẩn của đối thủ. Người chơi đầu tiên tìm ra nhân vật bí ẩn của người chơi khác sẽ thắng trò chơi.
Bạn đã hiểu. Người ta phải xác định cá nhân trong tập dữ liệu bằng cách chỉ có quyền truy cập vào các thuộc tính tương ứng. Trên thực tế, chúng ta thường xuyên thấy khái niệm Đoán Ai này được áp dụng trong thực tế, nhưng sau đó được sử dụng trên các tập dữ liệu được định dạng với các hàng và cột chứa các thuộc tính của người thật. Sự khác biệt chính khi làm việc với dữ liệu là mọi người có xu hướng đánh giá thấp mức độ dễ dàng mà các cá nhân thực sự có thể bị lộ ra bằng cách chỉ có quyền truy cập vào một số thuộc tính.
Như trò chơi Đoán Ai minh họa, ai đó có thể xác định các cá nhân bằng cách chỉ có quyền truy cập vào một số thuộc tính. Nó phục vụ như một ví dụ đơn giản về lý do tại sao chỉ xóa 'tên' (hoặc các số nhận dạng trực tiếp khác) khỏi tập dữ liệu của bạn không thành công như một kỹ thuật ẩn danh. Trong blog này, chúng tôi đưa ra bốn trường hợp thực tế để thông báo cho bạn về những rủi ro về quyền riêng tư liên quan đến việc xóa các cột như một phương tiện ẩn danh dữ liệu.
Rủi ro về một cuộc tấn công liên kết là lý do quan trọng nhất tại sao chỉ xóa tên không hoạt động (nữa) như một phương pháp ẩn danh. Với cuộc tấn công liên kết, kẻ tấn công kết hợp dữ liệu gốc với các nguồn dữ liệu có thể truy cập khác để xác định duy nhất một cá nhân và tìm hiểu thông tin (thường nhạy cảm) về người này.
Chìa khóa ở đây là sự sẵn có của các tài nguyên dữ liệu khác hiện tại hoặc có thể trở thành hiện tại trong tương lai. Hãy nghĩ về bản thân. Bao nhiêu dữ liệu cá nhân của riêng bạn có thể được tìm thấy trên Facebook, Instagram hoặc LinkedIn có khả năng bị lạm dụng cho một cuộc tấn công liên kết?
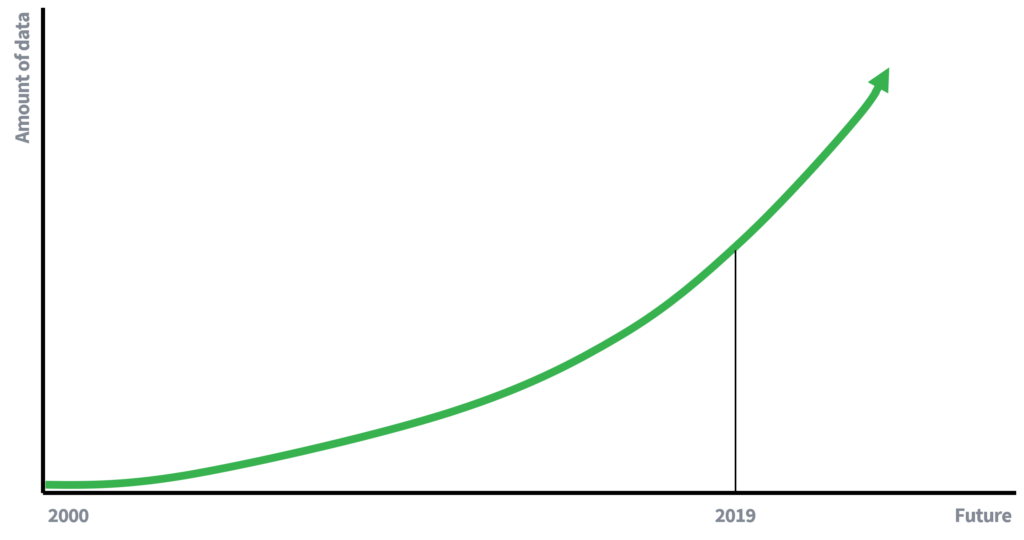
Trong những ngày trước đó, tính sẵn có của dữ liệu bị hạn chế hơn nhiều, điều này phần nào giải thích tại sao việc xóa tên là đủ để bảo vệ quyền riêng tư của các cá nhân. Dữ liệu có sẵn ít hơn có nghĩa là ít cơ hội hơn để liên kết dữ liệu. Tuy nhiên, chúng tôi hiện đang (tích cực) tham gia vào nền kinh tế dựa trên dữ liệu, nơi lượng dữ liệu đang tăng với tốc độ cấp số nhân. Nhiều dữ liệu hơn và cải tiến công nghệ thu thập dữ liệu sẽ dẫn đến tăng khả năng xảy ra các cuộc tấn công liên kết. Người ta sẽ viết gì trong 10 năm về rủi ro của một cuộc tấn công liên kết?
Minh họa 1
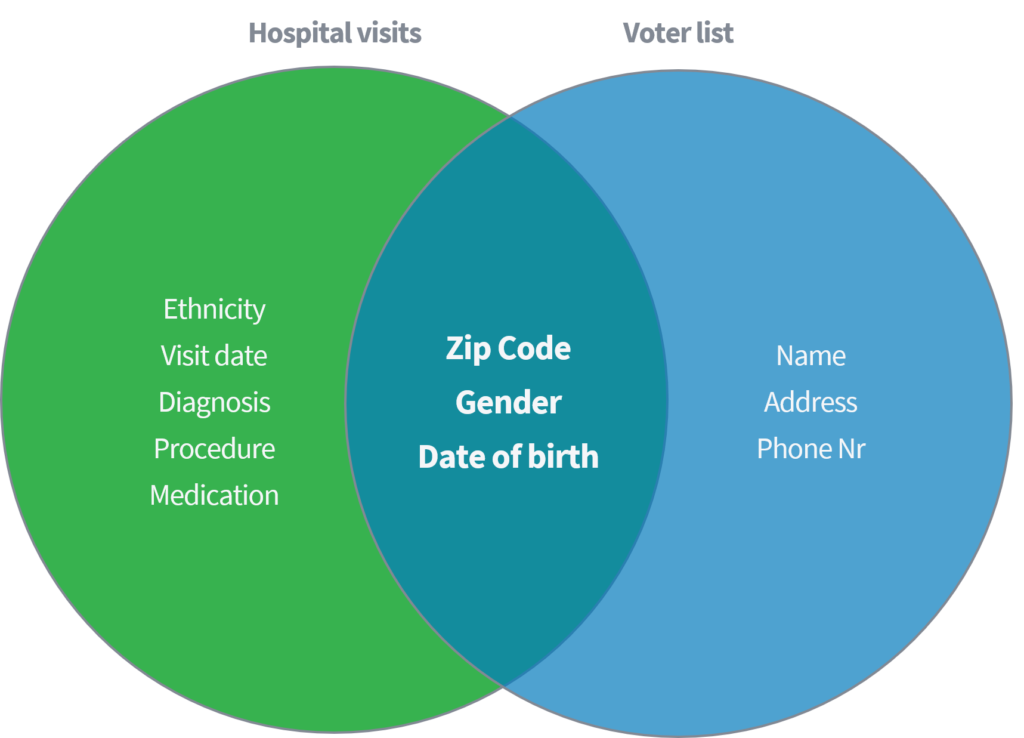
Sweeney (2002) đã chứng minh trong một bài báo học thuật về cách cô có thể xác định và truy xuất dữ liệu y tế nhạy cảm từ các cá nhân dựa trên việc liên kết một tập dữ liệu có sẵn công khai về 'lượt thăm bệnh viện' với cơ quan đăng ký bỏ phiếu công khai ở Hoa Kỳ. Cả hai tập dữ liệu được cho là được ẩn danh thích hợp thông qua việc xóa tên và các số nhận dạng trực tiếp khác.
Minh họa 2
Chỉ dựa trên ba tham số (1) Mã Zip, (2) Giới tính và (3) Ngày sinh, cô ấy đã chỉ ra rằng 87% toàn bộ dân số Hoa Kỳ có thể được xác định lại bằng cách đối sánh các thuộc tính nói trên từ cả hai tập dữ liệu. Sau đó, Sweeney lặp lại công việc của mình với việc sử dụng 'country' để thay thế cho 'Zip Code'. Ngoài ra, cô ấy chứng minh rằng 18% toàn bộ dân số Hoa Kỳ chỉ có thể được xác định bằng cách truy cập vào tập dữ liệu chứa thông tin về (1) quê hương, (2) giới tính và (3) ngày sinh. Hãy nghĩ về các nguồn công khai nói trên, như Facebook, LinkedIn hoặc Instagram. Quốc gia, giới tính và ngày sinh của bạn có hiển thị hay những người dùng khác có thể khấu trừ nó không?
Minh họa 3
| Chuẩn định danh | % dân số Hoa Kỳ được xác định duy nhất (248 triệu) |
| ZIP 5 chữ số, giới tính, ngày sinh | 87% |
| nơi, giới tính, ngày sinh | 53% |
| đất nước, giới tính, ngày sinh | 18% |
Ví dụ này chứng minh rằng việc xóa ẩn danh các cá nhân trong dữ liệu dường như ẩn danh có thể dễ dàng một cách đáng kể. Đầu tiên, nghiên cứu này chỉ ra mức độ rủi ro rất lớn, như Có thể dễ dàng xác định 87% dân số Hoa Kỳ bằng cách sử dụng vài đặc điểm. Thứ hai, dữ liệu y tế được tiết lộ trong nghiên cứu này rất nhạy cảm. Ví dụ về dữ liệu của các cá nhân bị phơi nhiễm từ tập dữ liệu về lượt khám bệnh tại bệnh viện bao gồm sắc tộc, chẩn đoán và thuốc. Ví dụ, các thuộc tính mà người ta có thể giữ bí mật từ các công ty bảo hiểm.
Một rủi ro khác khi chỉ loại bỏ các định danh trực tiếp, chẳng hạn như tên, phát sinh khi các cá nhân được thông báo có kiến thức hoặc thông tin vượt trội về các đặc điểm hoặc hành vi của các cá nhân cụ thể trong tập dữ liệu. Dựa trên kiến thức của họ, kẻ tấn công sau đó có thể liên kết các bản ghi dữ liệu cụ thể với những người thực tế.
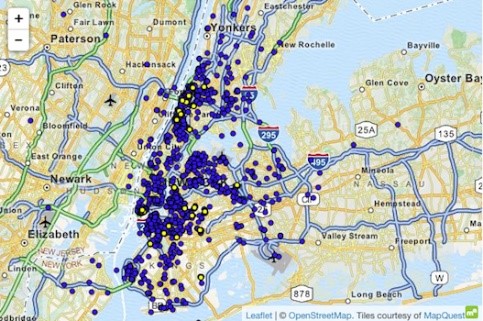
Một ví dụ về một cuộc tấn công vào tập dữ liệu sử dụng kiến thức vượt trội là trường hợp taxi ở New York, nơi Atockar (2014) đã có thể vạch mặt những cá nhân cụ thể. Tập dữ liệu được sử dụng chứa tất cả các hành trình taxi ở New York, được bổ sung thêm các thuộc tính cơ bản như tọa độ bắt đầu, tọa độ cuối, giá và tiền boa của chuyến đi.
Một cá nhân được thông báo biết New York đã có thể bắt các chuyến taxi đến câu lạc bộ dành cho người lớn 'Hustler'. Bằng cách lọc 'vị trí kết thúc', anh ấy đã suy ra các địa chỉ bắt đầu chính xác và do đó xác định được nhiều khách truy cập thường xuyên khác nhau. Tương tự, người ta có thể suy ra các chuyến taxi khi địa chỉ nhà của cá nhân được biết. Thời gian và vị trí của một số ngôi sao điện ảnh nổi tiếng đã được phát hiện trên các trang web tin đồn. Sau khi liên kết thông tin này với dữ liệu taxi ở NYC, thật dễ dàng để biết được các chuyến đi taxi của họ, số tiền họ đã trả và liệu họ có được boa hay không.
Minh họa 4
tọa độ thả xuống Hustler
Bradley Cooper
Jessica Alba
Một luồng lập luận phổ biến là "dữ liệu này là vô giá trị" hoặc "không ai có thể làm bất cứ điều gì với dữ liệu này". Đây thường là một quan niệm sai lầm. Ngay cả những dữ liệu vô tội nhất cũng có thể tạo thành một 'dấu vân tay' duy nhất và được sử dụng để xác định lại các cá nhân. Đó là rủi ro bắt nguồn từ việc tin rằng bản thân dữ liệu là vô giá trị, trong khi thực tế thì không.
Rủi ro nhận dạng sẽ tăng lên cùng với sự gia tăng của dữ liệu, AI cũng như các công cụ và thuật toán khác cho phép phát hiện ra các mối quan hệ phức tạp trong dữ liệu. Do đó, ngay cả khi tập dữ liệu của bạn không thể được khám phá ngay bây giờ và có lẽ là vô dụng đối với những người không được phép ngày hôm nay, nó có thể không phải là ngày mai.
Một ví dụ tuyệt vời là trường hợp Netflix dự định thu hút sự chú ý của bộ phận R&D bằng cách giới thiệu một cuộc thi mở rộng của Netflix để cải thiện hệ thống đề xuất phim của họ. 'Công cụ cải tiến thuật toán lọc cộng tác để dự đoán xếp hạng của người dùng cho phim giành được giải thưởng 1,000,000 đô la Mỹ'. Để hỗ trợ đám đông, Netflix đã xuất bản tập dữ liệu chỉ chứa các thuộc tính cơ bản sau: userID, phim, ngày học và điểm (vì vậy không có thêm thông tin về người dùng hoặc bản thân phim).
Minh họa 5
| ID người dùng | Bộ phim | Ngày cấp lớp | Lớp |
| 123456789 | Nhiệm vụ bất khả | 10-12-2008 | 4 |
Trong sự cô lập, dữ liệu dường như vô ích. Khi đặt câu hỏi 'Có bất kỳ thông tin khách hàng nào trong tập dữ liệu cần được giữ kín không?', Câu trả lời là:
'Không, tất cả thông tin nhận dạng khách hàng đã bị xóa; tất cả những gì còn lại là xếp hạng và ngày tháng. Điều này tuân theo chính sách bảo mật của chúng tôi… '
Tuy nhiên, Narayanan (2008) từ Đại học Texas tại Austin đã chứng minh điều ngược lại. Sự kết hợp giữa điểm, ngày cấp và phim của một cá nhân tạo thành một dấu vân tay phim duy nhất. Suy nghĩ về hành vi Netflix của riêng bạn. Bạn nghĩ có bao nhiêu người đã xem cùng một bộ phim? Có bao nhiêu người đã xem cùng một bộ phim cùng một lúc?
Câu hỏi chính, làm thế nào để khớp với dấu vân tay này? Nó khá đơn giản. Dựa trên thông tin từ trang web xếp hạng phim nổi tiếng IMDb (Cơ sở dữ liệu phim trên Internet), một dấu vân tay tương tự có thể được hình thành. Do đó, các cá nhân có thể được xác định lại.
Mặc dù hành vi xem phim có thể không được coi là thông tin nhạy cảm, nhưng hãy suy nghĩ về hành vi của chính bạn - bạn có phiền nếu nó được công khai không? Các ví dụ mà Narayanan cung cấp trong bài báo của mình là sở thích chính trị (xếp hạng về "Chúa Giêsu thành Nazareth" và "Phúc âm của John") và sở thích tình dục (xếp hạng về "Bent" và "Queer là dân gian") có thể dễ dàng được chắt lọc.
GDPR có thể không quá thú vị, cũng không phải là viên đạn bạc giữa các chủ đề blog. Tuy nhiên, sẽ rất hữu ích nếu bạn hiểu rõ các định nghĩa khi xử lý dữ liệu cá nhân. Vì blog này nói về quan niệm sai lầm phổ biến là xóa cột như một cách để ẩn danh dữ liệu và để hướng dẫn bạn với tư cách là người xử lý dữ liệu, chúng ta hãy bắt đầu với việc khám phá định nghĩa ẩn danh theo GDPR.
Theo thuật lại 26 từ GDPR, thông tin ẩn danh được định nghĩa là:
'thông tin không liên quan đến thể nhân hoặc dữ liệu cá nhân được xác định hoặc nhận dạng được ẩn danh theo cách mà chủ thể dữ liệu không hoặc không còn nhận dạng được nữa.'
Vì một người xử lý dữ liệu cá nhân liên quan đến thể nhân, nên chỉ có phần 2 của định nghĩa là có liên quan. Để tuân thủ định nghĩa, người ta phải đảm bảo rằng chủ thể dữ liệu (cá nhân) không hoặc không còn nhận dạng được nữa. Tuy nhiên, như đã chỉ ra trong blog này, việc xác định các cá nhân dựa trên một vài thuộc tính rất đơn giản. Vì vậy, việc xóa tên khỏi tập dữ liệu không tuân theo định nghĩa của GDPR về ẩn danh.
Chúng tôi đã thách thức một phương pháp thường được coi là được coi là và không may là vẫn thường xuyên áp dụng phương pháp ẩn danh dữ liệu: xóa tên. Trong trò chơi Đoán Ai và bốn ví dụ khác về:
cho thấy rằng việc xóa tên không thành công dưới dạng ẩn danh. Mặc dù các ví dụ là những trường hợp nổi bật, nhưng mỗi ví dụ đều cho thấy sự đơn giản của việc xác định lại và tác động tiêu cực có thể xảy ra đối với quyền riêng tư của các cá nhân.
Kết luận, việc xóa tên khỏi tập dữ liệu của bạn không dẫn đến dữ liệu ẩn danh. Do đó, tốt hơn chúng ta nên tránh sử dụng cả hai thuật ngữ thay thế cho nhau. Tôi chân thành hy vọng bạn sẽ không áp dụng phương pháp này để ẩn danh. Và, nếu bạn vẫn làm vậy, hãy đảm bảo rằng bạn và nhóm của bạn hiểu đầy đủ các rủi ro về quyền riêng tư và được phép chấp nhận những rủi ro đó thay mặt cho các cá nhân bị ảnh hưởng.
Liên hệ với Syntho và một trong những chuyên gia của chúng tôi sẽ liên hệ với bạn với tốc độ ánh sáng để khám phá giá trị của dữ liệu tổng hợp!