เครื่องมือลบข้อมูลระบุตัวตนที่ดีที่สุดสำหรับการปฏิบัติตามการคุ้มครองความเป็นส่วนตัว
องค์กรต่างๆ ใช้เครื่องมือลบข้อมูลระบุตัวตนเพื่อลบออก ข้อมูลส่วนบุคคลที่สามารถระบุตัวตนได้ จากชุดข้อมูลของพวกเขา การไม่ปฏิบัติตามอาจนำไปสู่การถูกปรับจำนวนมากจากหน่วยงานกำกับดูแลและ การละเมิดข้อมูล. ไม่มี ข้อมูลที่ไม่ระบุชื่อคุณจะไม่สามารถใช้หรือแชร์ชุดข้อมูลได้อย่างเต็มที่
หลาย เครื่องมือไม่เปิดเผยตัวตน ไม่สามารถรับประกันการปฏิบัติตามข้อกำหนดทั้งหมดได้ วิธีการรุ่นเก่าอาจทำให้ข้อมูลส่วนบุคคลเสี่ยงต่อการถูกระบุตัวตนโดยผู้ไม่ประสงค์ดี บาง วิธีการลบข้อมูลระบุตัวตนทางสถิติ ลดคุณภาพของชุดข้อมูลลงจนถึงจุดที่ไม่น่าเชื่อถือ การวิเคราะห์ข้อมูล.
ขณะที่ ซินโธ จะแนะนำให้คุณรู้จักกับวิธีการลบข้อมูลระบุตัวตนและความแตกต่างที่สำคัญระหว่างเครื่องมือรุ่นอดีตและรุ่นถัดไป เราจะแจ้งให้คุณทราบเกี่ยวกับเครื่องมือลบข้อมูลระบุตัวตนที่ดีที่สุด และแนะนำข้อควรพิจารณาหลักในการเลือกเครื่องมือเหล่านี้
สารบัญ
- ข้อมูลสังเคราะห์คืออะไร
- ทำงานอย่างไร ?
- เหตุใดองค์กรจึงใช้มัน
- เริ่มต้นอย่างไร

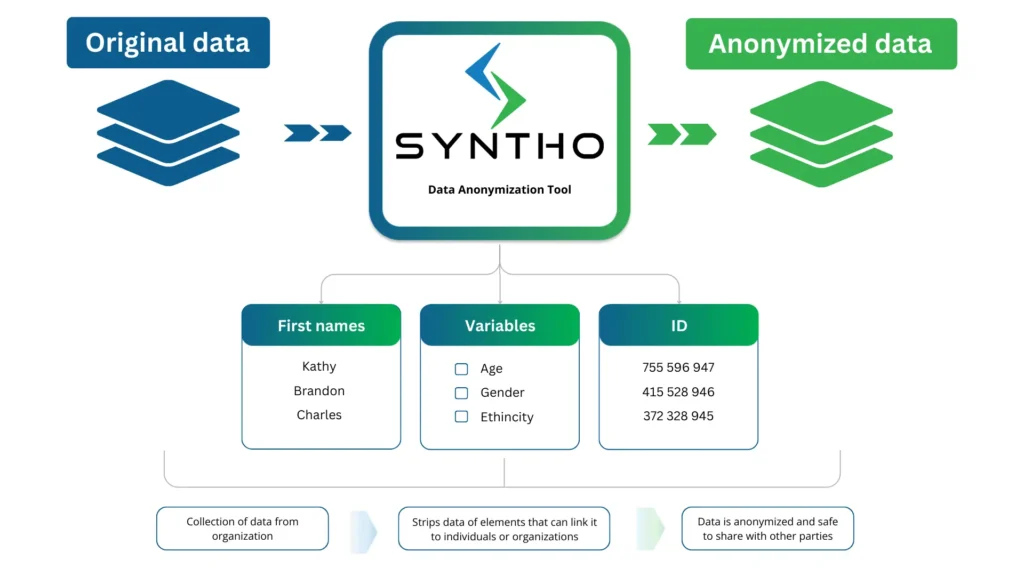
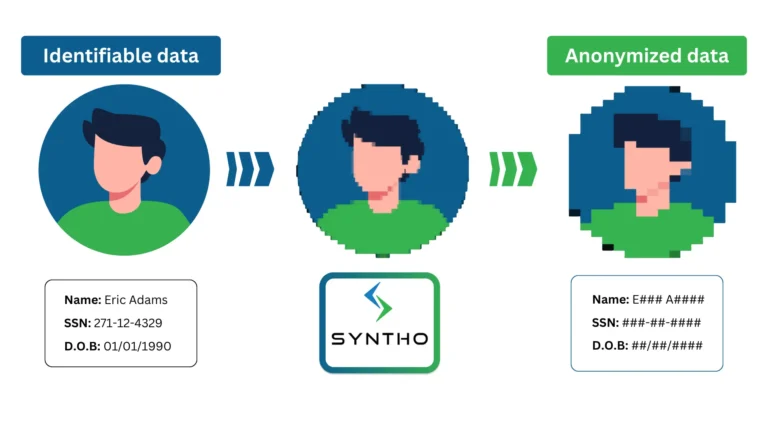
เครื่องมือลบข้อมูลระบุตัวตนคืออะไร?
การทำให้ข้อมูลไม่ระบุชื่อ เป็นเทคนิคการลบหรือแก้ไขข้อมูลที่เป็นความลับในชุดข้อมูล องค์กรไม่สามารถเข้าถึง แบ่งปัน และใช้ข้อมูลที่มีอยู่ที่สามารถตรวจสอบย้อนกลับถึงตัวบุคคลได้โดยตรงหรือโดยอ้อม
- ระเบียบว่าด้วยการคุ้มครองข้อมูลทั่วไป (GDPR). กฎหมายของสหภาพยุโรป ปกป้องความเป็นส่วนตัวของข้อมูลส่วนบุคคล กำหนดความยินยอมในการประมวลผลข้อมูล และให้สิทธิ์ในการเข้าถึงข้อมูลแก่บุคคล สหราชอาณาจักรมีกฎหมายที่คล้ายกันที่เรียกว่า UK-GDPR
- พระราชบัญญัติความเป็นส่วนตัวของผู้บริโภคแห่งแคลิฟอร์เนีย (CCPA) กฎหมายความเป็นส่วนตัวของรัฐแคลิฟอร์เนีย มุ่งเน้นไปที่สิทธิของผู้บริโภคเกี่ยวกับ การแชร์ข้อมูล.
- พระราชบัญญัติการพกพาและความรับผิดชอบในการประกันสุขภาพ (HIPAA) กฎความเป็นส่วนตัว กำหนดมาตรฐานในการปกป้องข้อมูลด้านสุขภาพของผู้ป่วย
เครื่องมือลบข้อมูลระบุตัวตนทำงานอย่างไร
เครื่องมือลบข้อมูลระบุตัวตนจะสแกนชุดข้อมูลเพื่อหาข้อมูลที่ละเอียดอ่อนและแทนที่ด้วยข้อมูลปลอม ซอฟต์แวร์ค้นหาข้อมูลดังกล่าวในตารางและคอลัมน์ ไฟล์ข้อความ และเอกสารที่สแกน
กระบวนการนี้จะดึงข้อมูลขององค์ประกอบที่สามารถเชื่อมโยงกับบุคคลหรือองค์กรได้ ประเภทของข้อมูลที่ถูกบดบังโดยเครื่องมือเหล่านี้ ได้แก่ :
- ข้อมูลที่สามารถระบุตัวบุคคลได้ (PII): ชื่อ หมายเลขประจำตัว วันเกิด รายละเอียดการเรียกเก็บเงิน หมายเลขโทรศัพท์ และที่อยู่อีเมล
- ข้อมูลสุขภาพที่ได้รับการคุ้มครอง (PHI): ครอบคลุมเวชระเบียน รายละเอียดการประกันสุขภาพ และข้อมูลสุขภาพส่วนบุคคล
- ข้อมูลทางการเงิน: หมายเลขบัตรเครดิต รายละเอียดบัญชีธนาคาร ข้อมูลการลงทุน และอื่นๆ ที่สามารถเชื่อมโยงกับนิติบุคคลได้
ตัวอย่างเช่น องค์กรด้านการดูแลสุขภาพจะไม่ระบุชื่อที่อยู่ของผู้ป่วยและรายละเอียดการติดต่อ เพื่อให้มั่นใจว่าสอดคล้องกับ HIPAA สำหรับการวิจัยโรคมะเร็ง บริษัทการเงินปิดบังวันที่และตำแหน่งของธุรกรรมในชุดข้อมูลของตนเพื่อให้เป็นไปตามกฎหมาย GDPR
แม้ว่าแนวคิดจะเหมือนกัน แต่ก็มีเทคนิคที่แตกต่างกันหลายประการ ข้อมูลที่ไม่ระบุชื่อ.
เทคนิคการทำให้ข้อมูลไม่ระบุชื่อ
การลบข้อมูลระบุตัวตนเกิดขึ้นได้หลายวิธี และไม่ใช่ว่าทุกวิธีจะเชื่อถือได้เท่ากันในด้านการปฏิบัติตามข้อกำหนดและประโยชน์ใช้สอย ในส่วนนี้อธิบายความแตกต่างระหว่างวิธีการประเภทต่างๆ
นามแฝง
การใช้นามแฝงเป็นกระบวนการยกเลิกการระบุตัวตนแบบย้อนกลับได้ โดยตัวระบุส่วนบุคคลจะถูกแทนที่ด้วยนามแฝง โดยจะรักษาการแมประหว่างข้อมูลต้นฉบับกับข้อมูลที่ถูกเปลี่ยนแปลง โดยตารางการแมปจะจัดเก็บแยกกัน
ข้อเสียของการใช้นามแฝงคือสามารถย้อนกลับได้ ด้วยข้อมูลเพิ่มเติม ผู้ประสงค์ร้ายสามารถติดตามกลับไปยังตัวบุคคลได้ ภายใต้กฎของ GDPR ข้อมูลที่ใช้นามแฝงไม่ถือว่าเป็นข้อมูลที่ไม่ระบุชื่อ ยังคงอยู่ภายใต้ข้อบังคับการปกป้องข้อมูล
การกำบังข้อมูล
วิธีการปกปิดข้อมูลจะสร้างข้อมูลที่มีโครงสร้างคล้ายกันแต่เป็นเวอร์ชันปลอมเพื่อปกป้องข้อมูลที่ละเอียดอ่อน เทคนิคนี้จะแทนที่ข้อมูลจริงด้วยอักขระที่เปลี่ยนแปลง โดยคงรูปแบบเดิมไว้สำหรับการใช้งานปกติ ตามทฤษฎี สิ่งนี้จะช่วยรักษาฟังก์ชันการทำงานของชุดข้อมูล
ในทางปฏิบัติ การปกปิดข้อมูล มักจะช่วยลด ยูทิลิตี้ข้อมูล- มันอาจจะล้มเหลวในการอนุรักษ์ ข้อมูลต้นฉบับการกระจายตัวหรือลักษณะเฉพาะของข้อมูลทำให้มีประโยชน์ในการวิเคราะห์น้อยลง ความท้าทายอีกประการหนึ่งคือการตัดสินใจว่าจะปกปิดอะไร หากทำไม่ถูกต้อง ข้อมูลที่มาสก์ยังคงสามารถระบุได้อีกครั้ง
ลักษณะทั่วไป (การรวมกลุ่ม)
ลักษณะทั่วไปทำให้ข้อมูลไม่ระบุชื่อโดยทำให้มีรายละเอียดน้อยลง โดยจะจัดกลุ่มข้อมูลที่คล้ายคลึงกันไว้ด้วยกันและลดคุณภาพลง ทำให้ยากต่อการแยกแยะข้อมูลแต่ละส่วนออกจากกัน วิธีนี้มักจะเกี่ยวข้องกับวิธีการสรุปข้อมูล เช่น การหาค่าเฉลี่ยหรือการรวมข้อมูล เพื่อปกป้องจุดข้อมูลแต่ละจุด
การทำให้เป็นทั่วไปมากเกินไปอาจทำให้ข้อมูลแทบไม่มีประโยชน์ ในขณะที่การทำให้เป็นทั่วไปน้อยเกินไปอาจให้ความเป็นส่วนตัวไม่เพียงพอ นอกจากนี้ยังมีความเสี่ยงต่อการเปิดเผยข้อมูลตกค้าง เนื่องจากชุดข้อมูลที่รวบรวมไว้อาจยังคงให้รายละเอียดการระบุตัวตนที่เพียงพอเมื่อรวมกับชุดข้อมูลอื่นๆ แหล่งข้อมูล.
การรบกวน
การก่อกวนจะแก้ไขชุดข้อมูลดั้งเดิมโดยการปัดเศษค่าและเพิ่มสัญญาณรบกวนแบบสุ่ม จุดข้อมูลมีการเปลี่ยนแปลงอย่างละเอียด ซึ่งขัดขวางสถานะเดิมในขณะที่ยังคงรักษารูปแบบข้อมูลโดยรวมไว้
ข้อเสียของการก่อกวนคือข้อมูลไม่ได้รับการเปิดเผยตัวตนอย่างสมบูรณ์ หากการเปลี่ยนแปลงไม่เพียงพอ อาจมีความเสี่ยงที่ลักษณะดั้งเดิมจะถูกระบุอีกครั้ง
การสลับข้อมูล
การสลับเป็นเทคนิคที่ค่าแอตทริบิวต์ในชุดข้อมูลถูกจัดเรียงใหม่ วิธีนี้ใช้งานง่ายเป็นพิเศษ ชุดข้อมูลสุดท้ายไม่สอดคล้องกับบันทึกต้นฉบับ และไม่สามารถติดตามไปยังแหล่งที่มาดั้งเดิมได้โดยตรง
อย่างไรก็ตาม ชุดข้อมูลยังคงสามารถย้อนกลับได้โดยทางอ้อม ข้อมูลที่สลับเสี่ยงต่อการเปิดเผยแม้จะมีแหล่งข้อมูลรองที่จำกัดก็ตาม นอกจากนี้ เป็นการยากที่จะรักษาความสมบูรณ์ทางความหมายของข้อมูลที่ถูกสลับบางส่วน ตัวอย่างเช่น เมื่อเปลี่ยนชื่อในฐานข้อมูล ระบบอาจไม่สามารถแยกแยะระหว่างชื่อชายและหญิงได้
tokenization
Tokenization จะแทนที่องค์ประกอบข้อมูลที่ละเอียดอ่อนด้วยโทเค็น ซึ่งเทียบเท่ากับข้อมูลที่ไม่ละเอียดอ่อนโดยไม่มีค่าที่สามารถหาประโยชน์ได้ ข้อมูลโทเค็นมักจะเป็นสตริงตัวเลขและอักขระแบบสุ่ม เทคนิคนี้มักใช้เพื่อปกป้องข้อมูลทางการเงินในขณะที่ยังคงรักษาคุณสมบัติเชิงหน้าที่ไว้
ซอฟต์แวร์บางตัวทำให้การจัดการและปรับขนาดคลังโทเค็นทำได้ยากขึ้น ระบบนี้ยังทำให้เกิดความเสี่ยงด้านความปลอดภัย: ข้อมูลที่ละเอียดอ่อนอาจมีความเสี่ยงหากผู้โจมตีเข้าถึงห้องนิรภัยการเข้ารหัส
การสุ่มตัวอย่าง
การสุ่มจะเปลี่ยนแปลงค่าด้วยการสุ่มและข้อมูลจำลอง เป็นแนวทางที่ตรงไปตรงมาซึ่งช่วยรักษาความลับของการป้อนข้อมูลแต่ละรายการ
เทคนิคนี้ใช้ไม่ได้ถ้าคุณต้องการรักษาการกระจายตัวทางสถิติให้แน่นอน รับประกันว่าจะประนีประนอมข้อมูลที่ใช้สำหรับชุดข้อมูลที่ซับซ้อน เช่น ข้อมูลเชิงพื้นที่หรือข้อมูลชั่วคราว วิธีการสุ่มตัวอย่างที่ไม่เพียงพอหรือไม่เหมาะสมก็ไม่สามารถรับประกันการคุ้มครองความเป็นส่วนตัวได้เช่นกัน
การแก้ไขข้อมูล
การแก้ไขข้อมูลคือกระบวนการลบข้อมูลออกจากชุดข้อมูลทั้งหมด เช่น การปกปิด การเว้นว่าง หรือการลบข้อความและรูปภาพ สิ่งนี้จะป้องกันการเข้าถึงข้อมูลที่ละเอียดอ่อน ข้อมูลการผลิต และเป็นแนวทางปฏิบัติทั่วไปในเอกสารทางกฎหมายและราชการ เห็นได้ชัดว่าข้อมูลดังกล่าวทำให้ข้อมูลไม่เหมาะสำหรับการวิเคราะห์ทางสถิติ การเรียนรู้แบบจำลอง และการวิจัยทางคลินิกที่แม่นยำ
เห็นได้ชัดว่าเทคนิคเหล่านี้มีข้อบกพร่องที่ทำให้เกิดช่องโหว่ที่ผู้กระทำผิดสามารถนำไปใช้ในทางที่ผิดได้ พวกเขามักจะลบองค์ประกอบสำคัญออกจากชุดข้อมูล ซึ่งจำกัดการใช้งาน นี่ไม่ใช่กรณีของเทคนิครุ่นสุดท้าย
เครื่องมือลบข้อมูลระบุตัวตนยุคใหม่
ซอฟต์แวร์การลบข้อมูลระบุตัวตนสมัยใหม่ใช้เทคนิคที่ซับซ้อนเพื่อลดความเสี่ยงในการระบุตัวตนอีกครั้ง พวกเขานำเสนอวิธีการปฏิบัติตามกฎระเบียบด้านความเป็นส่วนตัวทั้งหมดในขณะที่ยังคงรักษาคุณภาพเชิงโครงสร้างของข้อมูล
การสร้างข้อมูลสังเคราะห์
การสร้างข้อมูลสังเคราะห์นำเสนอแนวทางที่ชาญฉลาดยิ่งขึ้นในการไม่เปิดเผยข้อมูลในขณะที่ยังคงรักษายูทิลิตี้ข้อมูลไว้ เทคนิคนี้ใช้อัลกอริธึมเพื่อสร้างชุดข้อมูลใหม่ที่สะท้อนโครงสร้างและคุณสมบัติของข้อมูลจริง
ข้อมูลสังเคราะห์จะแทนที่ PII และ PHI ด้วยข้อมูลจำลองที่ไม่สามารถติดตามถึงตัวบุคคลได้ สิ่งนี้ทำให้มั่นใจได้ถึงการปฏิบัติตามกฎหมายความเป็นส่วนตัวของข้อมูล เช่น GDPR และ HIPAA การใช้เครื่องมือสร้างข้อมูลสังเคราะห์ช่วยให้องค์กรต่างๆ มั่นใจในความเป็นส่วนตัวของข้อมูล ลดความเสี่ยงของการละเมิดข้อมูล และเร่งการพัฒนาแอปพลิเคชันที่ขับเคลื่อนด้วยข้อมูล
การเข้ารหัสแบบโฮโมมอร์ฟิค
การเข้ารหัสแบบ Homomorphic (แปลว่า "โครงสร้างเดียวกัน") แปลงข้อมูล ลงในไซเฟอร์เท็กซ์ ชุดข้อมูลที่เข้ารหัสจะคงโครงสร้างเดียวกันกับข้อมูลต้นฉบับ ส่งผลให้การทดสอบมีความแม่นยำเป็นเลิศ
วิธีการนี้ช่วยให้สามารถคำนวณที่ซับซ้อนได้โดยตรงบน ข้อมูลที่เข้ารหัส โดยไม่จำเป็นต้องถอดรหัสก่อน องค์กรสามารถจัดเก็บไฟล์ที่เข้ารหัสอย่างปลอดภัยในระบบคลาวด์สาธารณะและการประมวลผลข้อมูลภายนอกให้กับบุคคลที่สามโดยไม่กระทบต่อความปลอดภัย ข้อมูลนี้ยังเป็นไปตามข้อกำหนด เนื่องจากกฎความเป็นส่วนตัวไม่มีผลกับข้อมูลที่เข้ารหัส
อย่างไรก็ตาม อัลกอริธึมที่ซับซ้อนจำเป็นต้องอาศัยความเชี่ยวชาญเพื่อการใช้งานที่ถูกต้อง นอกจากนี้ การเข้ารหัสโฮโมมอร์ฟิกยังช้ากว่าการดำเนินการกับข้อมูลที่ไม่ได้เข้ารหัส อาจไม่ใช่โซลูชันที่ดีที่สุดสำหรับทีม DevOps และ Quality Assurance (QA) ที่ต้องการการเข้าถึงข้อมูลอย่างรวดเร็วเพื่อการทดสอบ
การประมวลผลแบบหลายฝ่ายที่ปลอดภัย
การคำนวณหลายฝ่ายที่ปลอดภัย (SMPC) เป็นวิธีการเข้ารหัสในการสร้างชุดข้อมูลด้วยความพยายามร่วมกันของสมาชิกหลายคน แต่ละฝ่ายเข้ารหัสอินพุตของตน คำนวณ และรับข้อมูลที่ประมวลผล ด้วยวิธีนี้ สมาชิกทุกคนจะได้รับผลลัพธ์ที่ต้องการในขณะที่ยังคงรักษาความลับข้อมูลของตนเองไว้
วิธีการนี้ต้องใช้หลายฝ่ายในการถอดรหัสชุดข้อมูลที่สร้างขึ้น ซึ่งทำให้เป็นความลับเป็นพิเศษ อย่างไรก็ตาม SMPC ต้องใช้เวลาอย่างมากในการสร้างผลลัพธ์
| เทคนิคการลบข้อมูลระบุตัวตนของข้อมูลรุ่นก่อนหน้า | เครื่องมือลบข้อมูลระบุตัวตนยุคใหม่ | ||||
|---|---|---|---|---|---|
| นามแฝง | แทนที่ตัวระบุส่วนบุคคลด้วยนามแฝงในขณะที่ยังคงรักษาตารางการแมปแยกต่างหาก | - การจัดการข้อมูลทรัพยากรบุคคล - การโต้ตอบการสนับสนุนลูกค้า - แบบสำรวจวิจัย | การสร้างข้อมูลสังเคราะห์ | ใช้อัลกอริทึมเพื่อสร้างชุดข้อมูลใหม่ที่สะท้อนโครงสร้างของข้อมูลจริง ในขณะเดียวกันก็รับประกันความเป็นส่วนตัวและการปฏิบัติตามข้อกำหนด | - การพัฒนาแอพพลิเคชั่นที่ขับเคลื่อนด้วยข้อมูล - การวิจัยทางคลินิก - การสร้างแบบจำลองขั้นสูง - การตลาดลูกค้า |
| การกำบังข้อมูล | เปลี่ยนแปลงข้อมูลจริงด้วยตัวอักษรปลอม โดยคงรูปแบบเดิม | - การรายงานทางการเงิน - สภาพแวดล้อมการฝึกอบรมผู้ใช้ | การเข้ารหัสแบบโฮโมมอร์ฟิค | แปลงข้อมูลเป็นไซเฟอร์เท็กซ์โดยยังคงรักษาโครงสร้างดั้งเดิม ทำให้สามารถคำนวณข้อมูลที่เข้ารหัสโดยไม่ต้องถอดรหัส | - การประมวลผลข้อมูลที่ปลอดภัย - การเอาท์ซอร์สการคำนวณข้อมูล - การวิเคราะห์ข้อมูลขั้นสูง |
| ลักษณะทั่วไป (การรวมกลุ่ม) | ลดรายละเอียดข้อมูล จัดกลุ่มข้อมูลที่คล้ายคลึงกัน | - การศึกษาประชากรศาสตร์ - การศึกษาตลาด | การประมวลผลแบบหลายฝ่ายที่ปลอดภัย | วิธีการเข้ารหัสที่หลายฝ่ายเข้ารหัสอินพุต ทำการคำนวณ และบรรลุผลลัพธ์ร่วมกัน | - การวิเคราะห์ข้อมูลร่วมกัน - การรวมข้อมูลที่เป็นความลับ |
| การรบกวน | แก้ไขชุดข้อมูลโดยการปัดเศษค่าและเพิ่มสัญญาณรบกวนแบบสุ่ม | - การวิเคราะห์ข้อมูลทางเศรษฐกิจ - การวิจัยรูปแบบการจราจร - การวิเคราะห์ข้อมูลการขาย | |||
| การสลับข้อมูล | จัดเรียงค่าแอตทริบิวต์ชุดข้อมูลใหม่เพื่อป้องกันการติดตามโดยตรง | - การศึกษาด้านการขนส่ง - การวิเคราะห์ข้อมูลทางการศึกษา | |||
| tokenization | แทนที่ข้อมูลที่ละเอียดอ่อนด้วยโทเค็นที่ไม่ละเอียดอ่อน | - การประมวลผลการชำระเงิน - การวิจัยความสัมพันธ์กับลูกค้า | |||
| การสุ่มตัวอย่าง | เพิ่มข้อมูลสุ่มหรือจำลองเพื่อแก้ไขค่า | - การวิเคราะห์ข้อมูลเชิงพื้นที่ - การศึกษาพฤติกรรม | |||
| การแก้ไขข้อมูล | ลบข้อมูลออกจากชุดข้อมูล | - การประมวลผลเอกสารทางกฎหมาย - การจัดการบันทึก | |||
ตารางที่ 1. การเปรียบเทียบระหว่างเทคนิคการลบข้อมูลระบุตัวตนรุ่นก่อนหน้าและรุ่นถัดไป
การลบการระบุตัวตนข้อมูลอัจฉริยะเป็นแนวทางใหม่ในการไม่เปิดเผยข้อมูล
การระบุตัวตนอัจฉริยะ ไม่ระบุชื่อข้อมูลโดยใช้ AI ที่สร้างขึ้น ข้อมูลจำลองสังเคราะห์- แพลตฟอร์มที่มีคุณสมบัติจะเปลี่ยนข้อมูลที่ละเอียดอ่อนให้เป็นข้อมูลที่ไม่สามารถระบุตัวตนได้ด้วยวิธีต่อไปนี้:
- ซอฟต์แวร์ลบการระบุตัวตนจะวิเคราะห์ชุดข้อมูลที่มีอยู่และระบุ PII และ PHI
- องค์กรสามารถเลือกข้อมูลที่ละเอียดอ่อนที่จะแทนที่ด้วยข้อมูลปลอมได้
- เครื่องมือนี้จะสร้างชุดข้อมูลใหม่ที่มีข้อมูลที่เป็นไปตามข้อกำหนด
เทคโนโลยีนี้มีประโยชน์เมื่อองค์กรจำเป็นต้องทำงานร่วมกันและแลกเปลี่ยนข้อมูลอันมีค่าอย่างปลอดภัย นอกจากนี้ยังมีประโยชน์เมื่อจำเป็นต้องทำให้ข้อมูลเป็นไปตามข้อกำหนดหลายประการ ฐานข้อมูลเชิงสัมพันธ์.
การลบการระบุตัวตนอัจฉริยะช่วยรักษาความสัมพันธ์ภายในข้อมูลให้คงเดิมผ่านการแมปที่สอดคล้องกัน บริษัทต่างๆ สามารถใช้ข้อมูลที่สร้างขึ้นสำหรับการวิเคราะห์ธุรกิจเชิงลึก การฝึกอบรมการเรียนรู้ของเครื่อง และการทดสอบทางคลินิก
ด้วยวิธีการต่างๆ มากมาย คุณต้องมีวิธีในการพิจารณาว่าเครื่องมือลบข้อมูลระบุตัวตนเหมาะกับคุณหรือไม่
วิธีเลือกเครื่องมือลบข้อมูลระบุตัวตนที่เหมาะสม
- ความสามารถในการขยายการดำเนินงาน เลือกเครื่องมือที่สามารถขยายขนาดขึ้นและลงได้ตามความต้องการในการปฏิบัติงานของคุณ ใช้เวลาทดสอบประสิทธิภาพการดำเนินงานภายใต้ภาระงานที่เพิ่มขึ้น
- บูรณาการ เครื่องมือลบข้อมูลระบุตัวตนควรผสานรวมกับระบบและซอฟต์แวร์การวิเคราะห์ที่มีอยู่ของคุณได้อย่างราบรื่น รวมถึงไปป์ไลน์การผสานรวมอย่างต่อเนื่องและการปรับใช้อย่างต่อเนื่อง (CI/CD) ความเข้ากันได้กับแพลตฟอร์มการจัดเก็บข้อมูล การเข้ารหัส และการประมวลผลของคุณเป็นสิ่งสำคัญสำหรับการดำเนินงานที่ราบรื่น
- การทำแผนที่ข้อมูลที่สอดคล้องกัน ตรวจสอบให้แน่ใจว่าผู้เก็บรักษาข้อมูลที่ไม่เปิดเผยตัวตนมีความสมบูรณ์และความแม่นยำทางสถิติที่เหมาะสมกับความต้องการของคุณ เทคนิคการลบข้อมูลระบุตัวตนรุ่นก่อนจะลบองค์ประกอบอันมีค่าออกจากชุดข้อมูล- อย่างไรก็ตาม เครื่องมือสมัยใหม่จะรักษาความสมบูรณ์ของการอ้างอิง ทำให้ข้อมูลมีความแม่นยำเพียงพอสำหรับกรณีการใช้งานขั้นสูง
- กลไกการรักษาความปลอดภัย จัดลำดับความสำคัญของเครื่องมือที่ปกป้องชุดข้อมูลจริงและผลลัพธ์ที่ไม่ระบุตัวตนจากภัยคุกคามภายในและภายนอก ซอฟต์แวร์จะต้องได้รับการปรับใช้ในโครงสร้างพื้นฐานของลูกค้าที่ปลอดภัย การควบคุมการเข้าถึงตามบทบาท และ API การตรวจสอบสิทธิ์แบบสองปัจจัย
- โครงสร้างพื้นฐานที่ได้มาตรฐาน ตรวจสอบให้แน่ใจว่าเครื่องมือจัดเก็บชุดข้อมูลในพื้นที่จัดเก็บข้อมูลที่ปลอดภัยซึ่งสอดคล้องกับกฎระเบียบ GDPR, HIPAA และ CCPA นอกจากนี้ควรสนับสนุนเครื่องมือสำรองและกู้คืนข้อมูลเพื่อหลีกเลี่ยงโอกาสที่ระบบจะหยุดทำงานเนื่องจากข้อผิดพลาดที่ไม่คาดคิด
- รูปแบบการชำระเงิน. พิจารณาต้นทุนทันทีและระยะยาวเพื่อทำความเข้าใจว่าเครื่องมือนี้สอดคล้องกับงบประมาณของคุณหรือไม่ เครื่องมือบางอย่างได้รับการออกแบบมาสำหรับองค์กรขนาดใหญ่และธุรกิจขนาดกลาง ในขณะที่เครื่องมืออื่นๆ มีโมเดลที่ยืดหยุ่นและแผนตามการใช้งาน
- การสนับสนุนทางเทคนิค. ประเมินคุณภาพและความพร้อมของลูกค้าและการสนับสนุนทางเทคนิค ผู้ให้บริการอาจช่วยคุณผสานรวมเครื่องมือลบข้อมูลระบุตัวตน ฝึกอบรมพนักงาน และแก้ไขปัญหาทางเทคนิค
เครื่องมือลบข้อมูลระบุตัวตนที่ดีที่สุด 7 อันดับ
ตอนนี้คุณรู้แล้วว่าจะต้องมองหาอะไร มาดูสิ่งที่เราเชื่อว่าเป็นเครื่องมือที่น่าเชื่อถือที่สุดกันดีกว่า ปิดบังข้อมูลที่ละเอียดอ่อน.
1. ซินโท
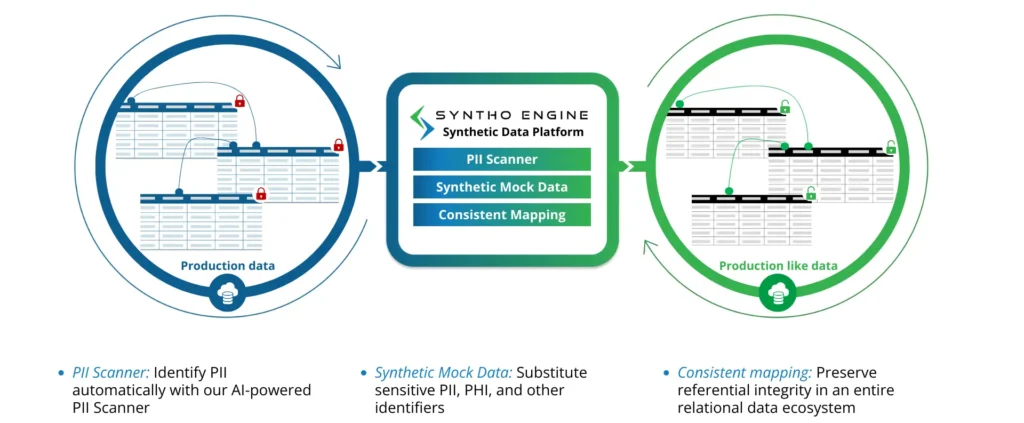
Syntho ขับเคลื่อนโดยซอฟต์แวร์สร้างข้อมูลสังเคราะห์ ที่ให้โอกาสในการกำจัดการระบุตัวตนอย่างชาญฉลาด- การสร้างข้อมูลตามกฎของแพลตฟอร์มนำมาซึ่งความคล่องตัว ช่วยให้องค์กรต่างๆ สามารถสร้างข้อมูลได้ตามความต้องการ
เครื่องสแกนที่ขับเคลื่อนด้วย AI ระบุ PII และ PHI ทั้งหมดในชุดข้อมูล ระบบ และแพลตฟอร์ม องค์กรสามารถเลือกข้อมูลที่จะลบหรือจำลองเพื่อให้เป็นไปตามมาตรฐานด้านกฎระเบียบ ในขณะเดียวกัน คุณลักษณะการตั้งค่าย่อยจะช่วยสร้างชุดข้อมูลขนาดเล็กสำหรับการทดสอบ ซึ่งช่วยลดภาระในการจัดเก็บและประมวลผลทรัพยากร
แพลตฟอร์มดังกล่าวมีประโยชน์ในภาคส่วนต่างๆ รวมถึงการดูแลสุขภาพ การจัดการห่วงโซ่อุปทาน และการเงิน องค์กรต่างๆ ใช้แพลตฟอร์ม Syntho เพื่อสร้างแบบไม่ใช้งานจริงและพัฒนาสถานการณ์การทดสอบแบบกำหนดเอง
คุณสามารถเรียนรู้เพิ่มเติมเกี่ยวกับความสามารถของ Syntho ได้จาก กำหนดการสาธิต.
2. K2view
3. บรอดคอม
4. ส่วนใหญ่เป็น AI
5. ส.ส
6. ความจำเสื่อม
7. โทนิค.ไอ
กรณีการใช้งานเครื่องมือลบข้อมูลระบุตัวตน
บริษัทต่างๆ ในด้านการเงิน การดูแลสุขภาพ การโฆษณา และบริการสาธารณะ ใช้เครื่องมือในการไม่เปิดเผยตัวตนเพื่อให้สอดคล้องกับกฎหมายความเป็นส่วนตัวของข้อมูล ชุดข้อมูลที่ไม่ระบุตัวตนจะถูกใช้สำหรับสถานการณ์ต่างๆ
การพัฒนาและทดสอบซอฟต์แวร์
เครื่องมือลบข้อมูลระบุตัวตนช่วยให้วิศวกรซอฟต์แวร์ ผู้ทดสอบ และผู้เชี่ยวชาญด้าน QA ทำงานกับชุดข้อมูลที่สมจริงได้โดยไม่เปิดเผย PII เครื่องมือขั้นสูงช่วยให้ทีมจัดเตรียมข้อมูลที่จำเป็นด้วยตนเองซึ่งเลียนแบบเงื่อนไขการทดสอบในโลกแห่งความเป็นจริงโดยไม่มีปัญหาด้านการปฏิบัติตามข้อกำหนด สิ่งนี้ช่วยให้องค์กรปรับปรุงประสิทธิภาพการพัฒนาซอฟต์แวร์และคุณภาพซอฟต์แวร์
กรณีจริง:
- ซอฟต์แวร์ของ Syntho สร้างข้อมูลการทดสอบที่ไม่ระบุชื่อ ที่รักษาค่าทางสถิติของข้อมูลจริง ช่วยให้นักพัฒนาสามารถลองใช้สถานการณ์ที่แตกต่างกันได้อย่างรวดเร็วยิ่งขึ้น
- คลังสินค้า BigQuery ของ Google นำเสนอฟีเจอร์การลบข้อมูลระบุตัวบุคคลของชุดข้อมูล เพื่อช่วยให้องค์กรแบ่งปันข้อมูลกับซัพพลายเออร์โดยไม่ละเมิดกฎความเป็นส่วนตัว
การวิจัยทางคลินิก
นักวิจัยทางการแพทย์ โดยเฉพาะอย่างยิ่งในอุตสาหกรรมยา ปกปิดข้อมูลเพื่อรักษาความเป็นส่วนตัวสำหรับการศึกษาของตน นักวิจัยสามารถวิเคราะห์แนวโน้ม ข้อมูลประชากรของผู้ป่วย และผลการรักษา ซึ่งมีส่วนทำให้เกิดความก้าวหน้าทางการแพทย์โดยไม่ต้องเสี่ยงต่อการรักษาความลับของผู้ป่วย
กรณีจริง:
- Erasmus Medical Center ใช้เครื่องมือสร้าง AI ที่ไม่เปิดเผยตัวตนของ Syntho เพื่อสร้างและแบ่งปันชุดข้อมูลคุณภาพสูงสำหรับการวิจัยทางการแพทย์
การป้องกันการฉ้อโกง
ในการป้องกันการฉ้อโกง เครื่องมือไม่เปิดเผยตัวตนช่วยให้วิเคราะห์ข้อมูลธุรกรรมได้อย่างปลอดภัย โดยระบุรูปแบบที่เป็นอันตราย เครื่องมือลบการระบุตัวตนยังช่วยให้สามารถฝึกอบรมซอฟต์แวร์ AI เกี่ยวกับข้อมูลจริงเพื่อปรับปรุงการตรวจจับการฉ้อโกงและความเสี่ยง
กรณีจริง:
- Brighterion ได้รับการฝึกอบรมเกี่ยวกับข้อมูลธุรกรรมที่ไม่ระบุตัวตนของ Mastercard เพื่อปรับปรุงโมเดล AI โดยปรับปรุงอัตราการตรวจจับการฉ้อโกงในขณะที่ลดผลบวกลวง
การตลาดลูกค้า
เทคนิคการลบข้อมูลระบุตัวตนช่วยประเมินความต้องการของลูกค้า องค์กรต่างๆ แบ่งปันชุดข้อมูลพฤติกรรมที่ไม่ระบุตัวตนกับพันธมิตรทางธุรกิจเพื่อปรับแต่งกลยุทธ์การตลาดแบบกำหนดเป้าหมายและปรับแต่งประสบการณ์ผู้ใช้ให้เป็นแบบส่วนตัว
กรณีจริง:
- แพลตฟอร์มการลบข้อมูลระบุตัวตนของ Syntho คาดการณ์การเปลี่ยนใจของลูกค้าได้อย่างแม่นยำโดยใช้ข้อมูลสังเคราะห์ สร้างขึ้นจากชุดข้อมูลของลูกค้ามากกว่า 56,000 ราย โดยมี 128 คอลัมน์
การเผยแพร่ข้อมูลสาธารณะ
หน่วยงานและหน่วยงานภาครัฐใช้การลบข้อมูลระบุตัวตนเพื่อแบ่งปันและประมวลผลข้อมูลสาธารณะอย่างโปร่งใสสำหรับโครงการสาธารณะต่างๆ ซึ่งรวมถึงการคาดการณ์อาชญากรรมตามข้อมูลจากเครือข่ายโซเชียลและประวัติอาชญากรรม การวางผังเมืองตามข้อมูลประชากรและเส้นทางการขนส่งสาธารณะ หรือความต้องการด้านการดูแลสุขภาพในภูมิภาคตามรูปแบบโรค
กรณีจริง:
- มหาวิทยาลัยอินเดียนาใช้ข้อมูลสมาร์ทโฟนที่ไม่ระบุชื่อจากเจ้าหน้าที่ตำรวจประมาณ 10,000 คน ใน 21 เมืองของสหรัฐอเมริกาเพื่อเปิดเผยความคลาดเคลื่อนของการลาดตระเวนในบริเวณใกล้เคียงโดยพิจารณาจากปัจจัยทางเศรษฐกิจและสังคม
นี่เป็นเพียงตัวอย่างบางส่วนที่เราเลือก ที่ ซอฟต์แวร์ไม่ระบุชื่อ ถูกใช้ในทุกอุตสาหกรรมเพื่อเป็นช่องทางในการใช้ประโยชน์สูงสุดจากข้อมูลที่มีอยู่
เลือกเครื่องมือลบข้อมูลระบุตัวตนที่ดีที่สุด
ทุกบริษัทใช้ ซอฟต์แวร์ลบข้อมูลฐานข้อมูล เพื่อให้สอดคล้องกับกฎระเบียบด้านความเป็นส่วนตัว เมื่อแยกออกจากข้อมูลส่วนบุคคล ชุดข้อมูลจะสามารถนำมาใช้และแบ่งปันได้โดยไม่ต้องเสี่ยงต่อการถูกปรับหรือกระบวนการราชการ
วิธีการลบข้อมูลระบุตัวตนแบบเก่า เช่น การสลับข้อมูล การมาสก์ และการเขียนทับไม่ปลอดภัยเพียงพอ การลบข้อมูลระบุตัวตน ยังคงมีความเป็นไปได้ซึ่งทำให้ไม่เป็นไปตามข้อกำหนดหรือมีความเสี่ยง นอกจากนี้ อดีตเจน ซอฟต์แวร์ไม่ระบุชื่อ มักจะทำให้คุณภาพของข้อมูลลดลง โดยเฉพาะใน ชุดข้อมูลขนาดใหญ่- องค์กรต่างๆ ไม่สามารถพึ่งพาข้อมูลดังกล่าวสำหรับการวิเคราะห์ขั้นสูงได้
คุณควรเลือกใช้ การไม่เปิดเผยข้อมูลที่ดีที่สุด ซอฟต์แวร์. ธุรกิจจำนวนมากเลือกแพลตฟอร์ม Syntho สำหรับความสามารถในการระบุ PII การมาสก์ และการสร้างข้อมูลสังเคราะห์ระดับสูง
คุณสนใจที่จะเรียนรู้เพิ่มเติมหรือไม่? อย่าลังเลที่จะสำรวจเอกสารประกอบผลิตภัณฑ์ของเราหรือ ติดต่อเราสำหรับการสาธิต.
เกี่ยวกับผู้เขียน

ผู้จัดการฝ่ายพัฒนาธุรกิจ
อูเลียนา คราอินสกาเป็นผู้บริหารฝ่ายพัฒนาธุรกิจที่ Syntho ซึ่งมีประสบการณ์ระดับนานาชาติในด้านการพัฒนาซอฟต์แวร์และอุตสาหกรรม SaaS สำเร็จการศึกษาระดับปริญญาโทด้านธุรกิจดิจิทัลและนวัตกรรมจาก VU Amsterdam
ในช่วงห้าปีที่ผ่านมา Uliana ได้แสดงให้เห็นถึงความมุ่งมั่นอย่างแน่วแน่ในการสำรวจความสามารถของ AI และให้คำปรึกษาทางธุรกิจเชิงกลยุทธ์สำหรับการดำเนินโครงการ AI

บันทึกคู่มือข้อมูลสังเคราะห์ของคุณตอนนี้!
- ข้อมูลสังเคราะห์คืออะไร?
- ทำไมองค์กรถึงใช้มัน?
- การเพิ่มมูลค่ากรณีไคลเอ็นต์ข้อมูลสังเคราะห์
- วิธีการเริ่มต้น
