


ข้อมูลสังเคราะห์ที่สร้างโดย Syntho ได้รับการประเมิน ตรวจสอบ และอนุมัติจากมุมมองภายนอกและวัตถุประสงค์โดยผู้เชี่ยวชาญด้านข้อมูลของ SAS
แม้ว่า Syntho มีความภูมิใจที่จะเสนอรายงานการรับประกันคุณภาพขั้นสูงแก่ผู้ใช้ แต่เราก็เข้าใจถึงความสำคัญของการประเมินข้อมูลสังเคราะห์ของเราจากผู้นำในอุตสาหกรรมภายนอกและตามวัตถุประสงค์ นั่นเป็นเหตุผลที่เราร่วมมือกับ SAS ผู้นำด้านการวิเคราะห์เพื่อประเมินข้อมูลสังเคราะห์ของเรา
SAS ดำเนินการประเมินอย่างละเอียดเกี่ยวกับความถูกต้องของข้อมูล การปกป้องความเป็นส่วนตัว และการใช้งานข้อมูลสังเคราะห์ที่สร้างโดย AI ของ Syntho เมื่อเปรียบเทียบกับข้อมูลต้นฉบับ โดยสรุป SAS ได้ประเมินและอนุมัติข้อมูลสังเคราะห์ของ Syntho ว่ามีความถูกต้อง ปลอดภัย และใช้งานได้เมื่อเปรียบเทียบกับข้อมูลต้นฉบับ
เราใช้ข้อมูลโทรคมนาคมที่ใช้สำหรับการคาดการณ์ "ปั่น" เป็นข้อมูลเป้าหมาย เป้าหมายของการประเมินคือการใช้ข้อมูลสังเคราะห์เพื่อฝึกโมเดลการทำนายการเปลี่ยนใจต่างๆ และเพื่อประเมินประสิทธิภาพของแต่ละโมเดล เนื่องจากการทำนายการเปลี่ยนใจเป็นงานการจัดหมวดหมู่ SAS จึงเลือกแบบจำลองการจัดหมวดหมู่ยอดนิยมเพื่อทำการคาดการณ์ ซึ่งรวมถึง:
ก่อนสร้างข้อมูลสังเคราะห์ SAS สุ่มแบ่งชุดข้อมูลโทรคมนาคมเป็นชุดรถไฟ (สำหรับฝึกโมเดล) และชุดพักสาย (สำหรับการให้คะแนนโมเดล) การมีการแบ่งแยกที่กำหนดไว้สำหรับการให้คะแนนช่วยให้สามารถประเมินอย่างเป็นกลางว่าแบบจำลองการจัดประเภทสามารถทำได้ดีเพียงใดเมื่อใช้กับข้อมูลใหม่
การใช้ชุดรถไฟเป็นอินพุต Syntho ใช้ Syntho Engine เพื่อสร้างชุดข้อมูลสังเคราะห์ สำหรับการเปรียบเทียบ SAS ยังสร้างชุดรถไฟเวอร์ชันที่ไม่เปิดเผยตัวตนหลังจากใช้เทคนิคการไม่เปิดเผยตัวตนต่างๆ เพื่อให้ถึงเกณฑ์ที่กำหนด (ของการไม่เปิดเผยตัวตนแบบ k) ขั้นตอนก่อนหน้านี้ส่งผลให้มีชุดข้อมูลสี่ชุด:
ชุดข้อมูลที่ 1, 3 และ 4 ถูกนำมาใช้ในการฝึกโมเดลการจำแนกแต่ละโมเดล ส่งผลให้ได้โมเดลที่ได้รับการฝึก 12 (3 x 4) ต่อมา SAS ใช้ชุดข้อมูลการระงับเพื่อวัดความแม่นยำของแต่ละรุ่นในการทำนายการเลิกใช้งานของลูกค้า
SAS ดำเนินการประเมินอย่างละเอียดเกี่ยวกับความถูกต้องของข้อมูล การปกป้องความเป็นส่วนตัว และการใช้งานข้อมูลสังเคราะห์ที่สร้างโดย AI ของ Syntho เมื่อเปรียบเทียบกับข้อมูลต้นฉบับ โดยสรุป SAS ได้ประเมินและอนุมัติข้อมูลสังเคราะห์ของ Syntho ว่ามีความถูกต้อง ปลอดภัย และใช้งานได้เมื่อเปรียบเทียบกับข้อมูลต้นฉบับ
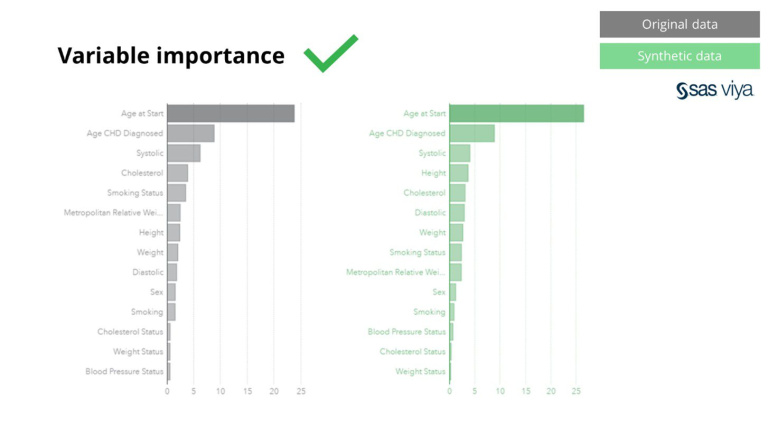
ข้อมูลสังเคราะห์จาก Syntho ไม่เพียงเก็บไว้สำหรับรูปแบบพื้นฐานเท่านั้น แต่ยังรวบรวมรูปแบบทางสถิติที่ 'ซ่อน' เชิงลึกที่จำเป็นสำหรับงานการวิเคราะห์ขั้นสูงอีกด้วย อย่างหลังแสดงให้เห็นในแผนภูมิแท่ง ซึ่งบ่งชี้ว่าความแม่นยำของแบบจำลองที่ได้รับการฝึกกับข้อมูลสังเคราะห์กับแบบจำลองที่ได้รับการฝึกด้วยข้อมูลต้นฉบับมีความคล้ายคลึงกัน ดังนั้นข้อมูลสังเคราะห์จึงสามารถนำไปใช้ในการฝึกโมเดลจริงได้ ข้อมูลนำเข้าและความสำคัญของตัวแปรที่เลือกโดยอัลกอริธึมเกี่ยวกับข้อมูลสังเคราะห์เมื่อเปรียบเทียบกับข้อมูลต้นฉบับมีความคล้ายคลึงกันมาก ดังนั้นจึงสรุปได้ว่ากระบวนการสร้างแบบจำลองสามารถทำได้กับข้อมูลสังเคราะห์ เป็นทางเลือกในการใช้ข้อมูลที่ละเอียดอ่อนจริง
เทคนิคการลบข้อมูลระบุตัวตนแบบคลาสสิกมีเหมือนกันคือจัดการข้อมูลต้นฉบับเพื่อขัดขวางการติดตามตัวบุคคล พวกเขาจัดการข้อมูลและทำลายข้อมูลในกระบวนการ ยิ่งคุณไม่เปิดเผยตัวตนมากเท่าไร ข้อมูลของคุณก็จะยิ่งได้รับการปกป้องดีขึ้นเท่านั้น แต่ข้อมูลของคุณก็จะยิ่งถูกทำลายมากขึ้นด้วย นี่เป็นความเสียหายอย่างยิ่งสำหรับ AI และงานการสร้างแบบจำลองที่ "พลังในการคาดการณ์" เป็นสิ่งจำเป็น เนื่องจากข้อมูลที่มีคุณภาพไม่ดีจะส่งผลให้ได้รับข้อมูลเชิงลึกที่ไม่ดีจากแบบจำลอง AI SAS แสดงให้เห็นสิ่งนี้ โดยมีพื้นที่ใต้เส้นโค้ง (AUC*) ใกล้ถึง 0.5 ซึ่งแสดงให้เห็นว่าแบบจำลองที่ได้รับการฝึกอบรมเกี่ยวกับข้อมูลที่ไม่เปิดเผยตัวตนนั้นทำงานได้แย่ที่สุด
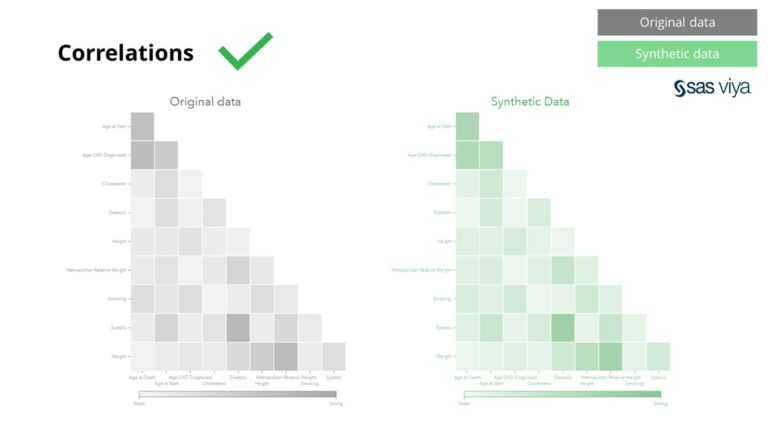
ความสัมพันธ์และความสัมพันธ์ระหว่างตัวแปรถูกรักษาไว้อย่างถูกต้องในข้อมูลสังเคราะห์
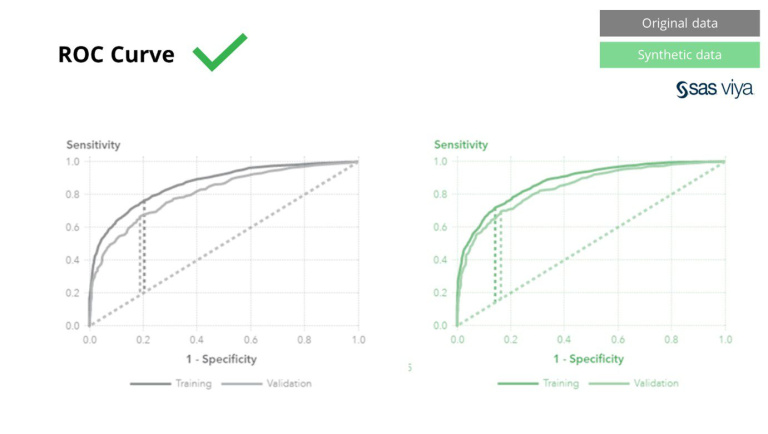
พื้นที่ใต้เส้นโค้ง (AUC) ซึ่งเป็นเมตริกสำหรับการวัดประสิทธิภาพของแบบจำลองยังคงสอดคล้องกัน
นอกจากนี้ ความสำคัญของตัวแปร ซึ่งบ่งชี้ถึงพลังการทำนายของตัวแปรในแบบจำลอง ยังคงไม่เปลี่ยนแปลงเมื่อเปรียบเทียบข้อมูลสังเคราะห์กับชุดข้อมูลดั้งเดิม
จากการสังเกตเหล่านี้โดย SAS และโดยการใช้ SAS Viya เราสามารถสรุปได้อย่างมั่นใจว่าข้อมูลสังเคราะห์ที่สร้างโดย Syntho Engine นั้นเทียบเท่ากับข้อมูลจริงในแง่ของคุณภาพอย่างแน่นอน สิ่งนี้จะตรวจสอบการใช้ข้อมูลสังเคราะห์เพื่อการพัฒนาแบบจำลอง ซึ่งปูทางไปสู่การวิเคราะห์ขั้นสูงด้วยข้อมูลสังเคราะห์
