Të dhëna sintetike të krijuara nga AI, akses i lehtë dhe i shpejtë në të dhëna me cilësi të lartë?
AI gjeneroi të dhëna sintetike në praktikë
Syntho, një ekspert në të dhënat sintetike të krijuara nga AI, synon të kthehet privacy by design në një avantazh konkurrues me të dhënat sintetike të krijuara nga AI. Ato ndihmojnë organizatat të ndërtojnë një bazë të fortë të dhënash me qasje të lehtë dhe të shpejtë në të dhëna me cilësi të lartë dhe së fundmi fituan Çmimin e Inovacionit Philips.
Sidoqoftë, gjenerimi i të dhënave sintetike me AI është një zgjidhje relativisht e re që zakonisht prezanton pyetjet e bëra shpesh. Për t'iu përgjigjur këtyre, Syntho filloi një studim rasti së bashku me SAS, lider në treg në softuerin e Advanced Analytics dhe AI.
Në bashkëpunim me Koalicionin Hollandez të AI (NL AIC), ata hetuan vlerën e të dhënave sintetike duke krahasuar të dhënat sintetike të gjeneruara nga AI të krijuara nga Syntho Engine me të dhënat origjinale nëpërmjet vlerësimeve të ndryshme mbi cilësinë e të dhënave, vlefshmërinë ligjore dhe përdorshmërinë.
A nuk është zgjidhje anonimizimi i të dhënave?
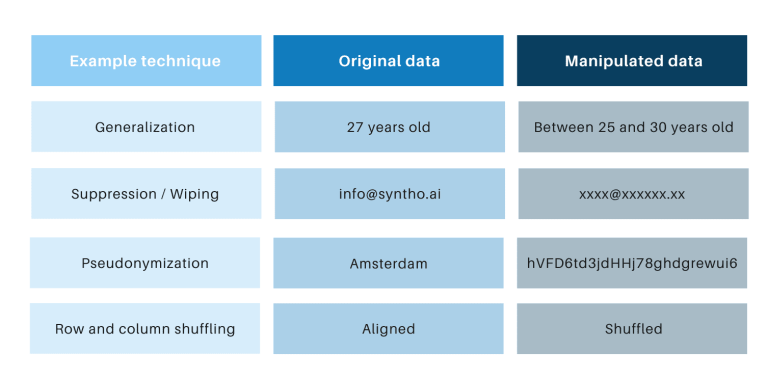
Teknikat klasike të anonimizimit kanë të përbashkët se ato manipulojnë të dhënat origjinale në mënyrë që të pengojnë gjurmimin e individëve. Shembuj janë përgjithësimi, shtypja, fshirja, pseudonimizimi, maskimi i të dhënave dhe përzierja e rreshtave dhe kolonave. Shembujt mund t'i gjeni në tabelën e mëposhtme.
Këto teknika paraqesin 3 sfida kryesore:
- Ato funksionojnë ndryshe për llojin e të dhënave dhe për grupin e të dhënave, duke i bërë ato të vështira për t'u shkallëzuar. Për më tepër, duke qenë se ato funksionojnë ndryshe, gjithmonë do të ketë debat se cilat metoda të aplikohen dhe çfarë kombinimi teknikash nevojiten.
- Ekziston gjithmonë një marrëdhënie një-për-një me të dhënat origjinale. Kjo do të thotë që gjithmonë do të ketë një rrezik privatësie, veçanërisht për shkak të të gjitha grupeve të të dhënave të hapura dhe teknikave të disponueshme për të lidhur ato grupe të dhënash.
- Ata manipulojnë të dhënat dhe në këtë mënyrë shkatërrojnë të dhënat në proces. Kjo është veçanërisht shkatërruese për detyrat e AI ku "fuqia parashikuese" është thelbësore, sepse të dhënat me cilësi të keqe do të rezultojnë në njohuri të këqija nga modeli i AI (Garbage-in do të rezultojë në mbeturina jashtë).
Këto pika vlerësohen gjithashtu përmes këtij rasti studimor.
Një hyrje në studimin e rastit
Për studimin e rastit, grupi i të dhënave të synuara ishte një grup i të dhënave të telekomit të ofruar nga SAS që përmban të dhënat e 56.600 klientëve. Kompleti i të dhënave përmban 128 kolona, duke përfshirë një kolonë që tregon nëse një klient është larguar nga kompania (d.m.th. 'i kapur') apo jo. Qëllimi i studimit të rastit ishte përdorimi i të dhënave sintetike për të trajnuar disa modele për të parashikuar largimin e klientëve dhe për të vlerësuar performancën e atyre modeleve të trajnuara. Duke qenë se parashikimi i përmbysjes është një detyrë klasifikimi, SAS zgjodhi katër modele të njohura klasifikimi për të bërë parashikimet, duke përfshirë:
- Pyll i rastësishëm
- Rritja e gradientit
- Regresioni logjistik
- Rrjeti nervor
Përpara se të gjeneronte të dhënat sintetike, SAS ndau në mënyrë të rastësishme të dhënat e telekomit në një grup treni (për trajnimin e modeleve) dhe një grup mbajtës (për vlerësimin e modeleve). Pasja e një grupi të veçantë rezervë për pikëzimin lejon një vlerësim të paanshëm se sa mirë mund të performojë modeli i klasifikimit kur zbatohet për të dhëna të reja.
Duke përdorur grupin e trenit si hyrje, Syntho përdori Motorin e tij Syntho për të gjeneruar një grup të dhënash sintetike. Për krahasim, SAS krijoi gjithashtu një version të manipuluar të grupit të trenave pas aplikimit të teknikave të ndryshme anonimizimi për të arritur një prag të caktuar (të k-anonimitetit). Hapat e mëparshëm rezultuan në katër grupe të dhënash:
- Një grup të dhënash treni (dmth. grupi i të dhënave origjinale minus grupin e të dhënave të mbetura)
- Një grup të dhënash mbajtëse (dmth. një nëngrup i të dhënave origjinale)
- Një grup të dhënash anonimizuar (bazuar në grupin e të dhënave të trenit)
- Një grup të dhënash sintetike (bazuar në grupin e të dhënave të trenit)
Të dhënat 1, 3 dhe 4 u përdorën për të trajnuar çdo model klasifikimi, duke rezultuar në 12 (3 x 4) modele të trajnuara. SAS më pas përdori grupin e të dhënave mbajtëse për të matur saktësinë me të cilën secili model parashikon shpërbërjen e klientit. Rezultatet janë paraqitur më poshtë, duke filluar me disa statistika bazë.
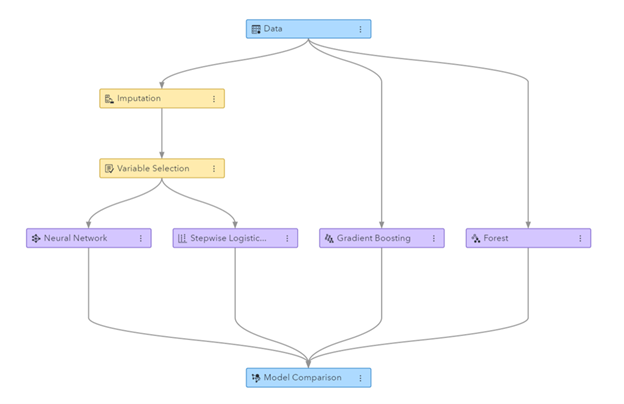
Figura: Linja e mësimit të makinerisë e krijuar në SAS Visual Data Mining dhe Machine Learning
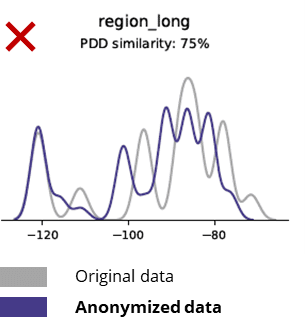
Statistikat bazë kur krahasoni të dhënat anonime me të dhënat origjinale
Teknikat e anonimizimit shkatërrojnë edhe modelet bazë, logjikën e biznesit, marrëdhëniet dhe statistikat (si në shembullin më poshtë). Përdorimi i të dhënave anonime për analitikën bazë prodhon kështu rezultate jo të besueshme. Në fakt, cilësia e dobët e të dhënave të anonimizuara e bëri pothuajse të pamundur përdorimin e tyre për detyra të avancuara analitike (p.sh. modelimi i AI/ML dhe paneli i kontrollit).
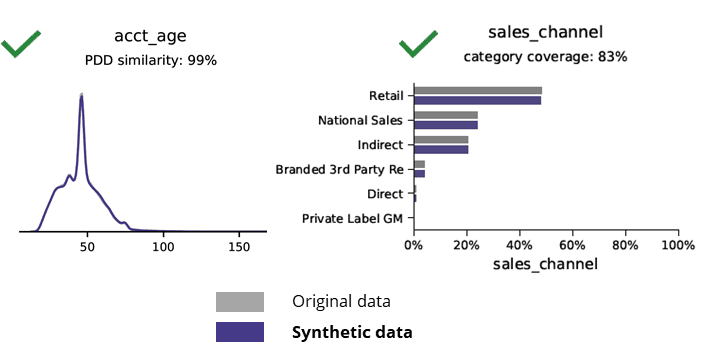
Statistikat bazë kur krahasohen të dhënat sintetike me të dhënat origjinale
Gjenerimi i të dhënave sintetike me AI ruan modelet bazë, logjikën e biznesit, marrëdhëniet dhe statistikat (si në shembullin më poshtë). Përdorimi i të dhënave sintetike për analitikën bazë prodhon kështu rezultate të besueshme. Pyetja kryesore, a kanë të dhënat sintetike për detyrat e avancuara të analitikës (p.sh. modelimi i AI/ML dhe paneli i kontrollit)?
Të dhëna sintetike të krijuara nga AI dhe analitikë të avancuar
Të dhënat sintetike nuk mbahen vetëm për modelet bazë (siç tregohet në grafikët e mëparshëm), ato kapin gjithashtu modele statistikore të "fshehura" të thella të kërkuara për detyra të avancuara analitike. Kjo e fundit është demonstruar në grafikun me shtylla më poshtë, duke treguar se saktësia e modeleve të trajnuara në të dhëna sintetike kundrejt modeleve të trajnuara me të dhëna origjinale janë të ngjashme. Për më tepër, me një zonë nën kurbë (AUC*) afër 0.5, modelet e trajnuara mbi të dhëna anonime performojnë shumë më të keqen. Raporti i plotë me të gjitha vlerësimet analitike të avancuara mbi të dhënat sintetike në krahasim me të dhënat origjinale është i disponueshëm sipas kërkesës.
*AUC: zona nën kurbë është një masë për saktësinë e modeleve të avancuara analitike, duke marrë parasysh pozitivet e vërteta, pozitive të rreme, negative të rreme dhe negative të vërteta. 0,5 do të thotë që një model parashikon rastësisht dhe nuk ka fuqi parashikuese dhe 1 do të thotë që modeli është gjithmonë i saktë dhe ka fuqi të plotë parashikuese.
Për më tepër, këto të dhëna sintetike mund të përdoren për të kuptuar karakteristikat e të dhënave dhe variablat kryesore të nevojshme për trajnimin aktual të modeleve. Inputet e përzgjedhura nga algoritmet për të dhënat sintetike në krahasim me të dhënat origjinale ishin shumë të ngjashme. Prandaj, procesi i modelimit mund të bëhet në këtë version sintetik, i cili redukton rrezikun e shkeljeve të të dhënave. Megjithatë, kur nxirren konkluzionet e të dhënave individuale (p.sh. klienti i telekomunikacionit), rekomandohet ritrajnimi në të dhënat origjinale për arsye shpjegueshmërie, rritje të pranimit ose thjesht për shkak të rregullimit.
AUC nga Algoritmi i grupuar sipas Metodës
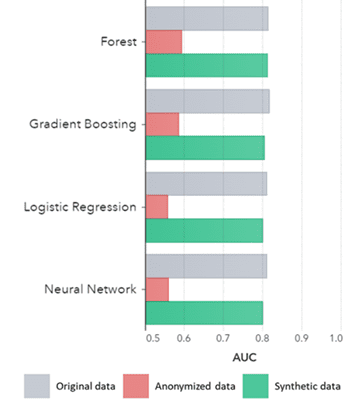
Konkluzione:
- Modelet e trajnuara me të dhëna sintetike në krahasim me modelet e trajnuara me të dhëna origjinale tregojnë performancë shumë të ngjashme
- Modelet e trajnuara mbi të dhënat e anonimizuara me "teknika klasike të anonimizimit" tregojnë performancë inferiore në krahasim me modelet e trajnuara mbi të dhënat origjinale ose të dhënat sintetike
- Gjenerimi i të dhënave sintetike është i lehtë dhe i shpejtë sepse teknika funksionon saktësisht e njëjtë për grupin e të dhënave dhe për llojin e të dhënave.
Rastet e përdorimit të të dhënave sintetike me vlerë të shtuar
Përdorimi i rastit 1: Të dhëna sintetike për zhvillimin e modelit dhe analitikën e avancuar
Të kesh një bazë të fortë të dhënash me qasje të lehtë dhe të shpejtë në të dhëna të përdorshme dhe me cilësi të lartë është thelbësore për zhvillimin e modeleve (p.sh. tabelat e kontrollit [BI] dhe analitikë të avancuar [AI & ML]). Megjithatë, shumë organizata vuajnë nga një bazë jooptimale e të dhënave që rezulton në 3 sfida kryesore:
- Marrja e aksesit në të dhënat kërkon mosha për shkak të rregullave (të privatësisë), proceseve të brendshme ose kapanoneve të të dhënave
- Teknikat klasike të anonimizimit shkatërrojnë të dhënat, duke i bërë të dhënat të mos jenë më të përshtatshme për analiza dhe analiza të avancuara (mbeturinat hyjnë = mbeturinat jashtë)
- Zgjidhjet ekzistuese nuk janë të shkallëzueshme sepse ato funksionojnë ndryshe për grupin e të dhënave dhe për llojin e të dhënave dhe nuk mund të trajtojnë bazat e të dhënave të mëdha me shumë tabela
Qasja e të dhënave sintetike: zhvilloni modele me të dhëna sintetike aq të mira sa reale për:
- Minimizoni përdorimin e të dhënave origjinale, pa penguar zhvilluesit tuaj
- Zhbllokoni të dhënat personale dhe keni qasje në më shumë të dhëna që ishin kufizuar më parë (p.sh. për shkak të privatësisë)
- Qasje e lehtë dhe e shpejtë e të dhënave në të dhënat përkatëse
- Zgjidhje e shkallëzuar që funksionon njësoj për secilën grup të dhënash, të dhëna dhe për bazat e të dhënave masive
Kjo i lejon organizatës të ndërtojë një bazë të fortë të dhënash me qasje të lehtë dhe të shpejtë në të dhëna të përdorshme dhe me cilësi të lartë për të zhbllokuar të dhënat dhe për të shfrytëzuar mundësitë e të dhënave.
Përdorimi i rastit 2: të dhënat inteligjente të provës sintetike për testimin, zhvillimin dhe shpërndarjen e softuerit
Testimi dhe zhvillimi me të dhëna testimi me cilësi të lartë është thelbësor për të ofruar zgjidhje softuerike moderne. Përdorimi i të dhënave origjinale të prodhimit duket i qartë, por nuk lejohet për shkak të rregulloreve (privatësisë). Alternativa Test Data Management (TDM) mjetet prezantojnë "legacy-by-design” në marrjen e saktë të të dhënave të testit:
- Mos pasqyroni të dhënat e prodhimit dhe logjika e biznesit dhe integriteti referues nuk ruhen
- Punoni ngadalë dhe kërkon kohë
- Kërkohet punë manuale
Qasja e të dhënave sintetike: Testoni dhe zhvilloni me të dhënat e provës sintetike të krijuara nga AI për të ofruar zgjidhje softuerike më të fundit të zgjuara me:
- Të dhëna të ngjashme me prodhimin me logjikë të ruajtur biznesi dhe integritet referues
- Gjenerim i lehtë dhe i shpejtë i të dhënave me UA-në më të avancuar
- Privatësia sipas dizajnit
- Lehtë, e shpejtë dhe agile
Kjo i lejon organizatës të testojë dhe të zhvillojë me të dhënat e testit të nivelit tjetër për të ofruar zgjidhje softuerike më të fundit!
Më shumë informacion
Të interesuar? Për më shumë informacion rreth të dhënave sintetike, vizitoni faqen e internetit të Syntho ose kontaktoni Wim Kees Janssen. Për më shumë informacion rreth SAS, vizitoni www.sas.com ose kontaktoni kees@syntho.ai.
Në këtë rast përdorimi, Syntho, SAS dhe NL AIC punojnë së bashku për të arritur rezultatet e synuara. Syntho është një ekspert në të dhënat sintetike të krijuara nga AI dhe SAS është lider në treg në analitikë dhe ofron softuer për eksplorimin, analizimin dhe vizualizimin e të dhënave.
* Parashikon 2021 – Strategjitë e të dhënave dhe analitikës për të qeverisur, shkallëzuar dhe transformuar biznesin dixhital, Gartner, 2020.

Ruani udhëzuesin tuaj të të dhënave sintetike tani!
- Çfarë janë të dhënat sintetike?
- Pse e përdorin organizatat?
- Rastet e klientit të të dhënave sintetike me vlerë të shtuar
- Si të filloni
