


සින්තෝ විසින් ජනනය කරන ලද කෘතිම දත්ත SAS හි දත්ත විශේෂඥයින් විසින් බාහිර හා වෛෂයික දෘෂ්ටි කෝණයකින් තක්සේරු කිරීම, වලංගු කිරීම සහ අනුමත කරනු ලැබේ.
Syntho තම පරිශීලකයින්ට උසස් තත්ත්ව සහතික වාර්තාවක් පිරිනැමීමට ආඩම්බර වන නමුත්, කර්මාන්ත ප්රමුඛයන්ගෙන් අපගේ කෘතිම දත්ත බාහිර හා වෛෂයික ඇගයීමක් කිරීමේ වැදගත්කම ද අපි තේරුම් ගනිමු. අපගේ කෘතිම දත්ත තක්සේරු කිරීමට අපි විශ්ලේෂණවල ප්රමුඛයා වන SAS සමඟ සහයෝගයෙන් කටයුතු කරන්නේ එබැවිනි.
SAS විසින් මුල් දත්ත හා සැසඳීමේ දී Syntho හි AI-ජනනය කරන ලද කෘතිම දත්තවල දත්ත නිරවද්යතාවය, රහස්යතා ආරක්ෂණය සහ භාවිතය පිළිබඳ විවිධ ගැඹුරු ඇගයීම් සිදු කරයි. අවසාන වශයෙන්, SAS විසින් Syntho හි කෘත්රිම දත්ත මුල් දත්තවලට සාපේක්ෂව නිරවද්ය, ආරක්ෂිත සහ භාවිත කළ හැකි ලෙස තක්සේරු කර අනුමත කරන ලදී.
අපි ඉලක්ක දත්ත ලෙස "චන්" අනාවැකි සඳහා භාවිතා කරන ටෙලිකොම් දත්ත භාවිතා කළෙමු. ඇගයීමේ අරමුණ වූයේ විවිධ චූන් පුරෝකථන ආකෘතීන් පුහුණු කිරීම සහ එක් එක් ආකෘතියේ කාර්ය සාධනය තක්සේරු කිරීම සඳහා කෘතිම දත්ත භාවිතා කිරීමයි. චූන් පුරෝකථනය වර්ගීකරණ කාර්යයක් වන බැවින්, SAS විසින් අනාවැකි කිරීමට ජනප්රිය වර්ගීකරණ ආකෘති තෝරා ගත්තේ:
කෘතිම දත්ත උත්පාදනය කිරීමට පෙර, SAS අහඹු ලෙස ටෙලිකොම් දත්ත කට්ටලය දුම්රිය කට්ටලයක් (ආකෘති පුහුණු කිරීම සඳහා) සහ රඳවා තබා ගැනීමේ කට්ටලයක් (ආකෘති ලකුණු කිරීම සඳහා) ලෙස බෙදා ඇත. ලකුණු ලබා ගැනීම සඳහා වෙනම රඳවා තබා ගැනීමක් තිබීම, නව දත්ත සඳහා යොදන විට වර්ගීකරණ ආකෘතිය කෙතරම් හොඳින් කළ හැකිදැයි අපක්ෂපාතී තක්සේරුවක් කිරීමට ඉඩ සලසයි.
දුම්රිය කට්ටලය ආදානය ලෙස භාවිතා කරමින්, සින්තටික් දත්ත කට්ටලයක් ජනනය කිරීමට සින්තෝ එහි සින්තෝ එන්ජිම භාවිතා කළේය. මිණුම් සලකුණු කිරීම සඳහා, SAS විසින් නිශ්චිත සීමාවකට (k-anonymity) ළඟා වීමට විවිධ නිර්නාමික ශිල්පීය ක්රම යෙදීමෙන් පසු දුම්රිය කට්ටලයේ නිර්නාමික අනුවාදයක් ද නිර්මාණය කළේය. පෙර පියවර දත්ත කට්ටල හතරක් බවට පත් විය:
එක් එක් වර්ගීකරණ ආකෘතිය පුහුණු කිරීම සඳහා දත්ත කට්ටල 1, 3 සහ 4 භාවිතා කරන ලද අතර, එහි ප්රතිඵලයක් ලෙස 12 (3 x 4) පුහුණු කළ ආකෘති ඇති විය. SAS විසින් පසුව පාරිභෝගිකයන් කඩාකප්පල් කිරීමේ පුරෝකථනය කිරීමේදී එක් එක් මාදිලියේ නිරවද්යතාවය මැනීමට රඳවා තබා ගැනීමේ දත්ත කට්ටලය භාවිතා කරන ලදී.
SAS විසින් මුල් දත්ත හා සැසඳීමේ දී Syntho හි AI-ජනනය කරන ලද කෘතිම දත්තවල දත්ත නිරවද්යතාවය, රහස්යතා ආරක්ෂණය සහ භාවිතය පිළිබඳ විවිධ ගැඹුරු ඇගයීම් සිදු කරයි. අවසාන වශයෙන්, SAS විසින් Syntho හි කෘත්රිම දත්ත මුල් දත්තවලට සාපේක්ෂව නිරවද්ය, ආරක්ෂිත සහ භාවිත කළ හැකි ලෙස තක්සේරු කර අනුමත කරන ලදී.
සින්තෝ වෙතින් සින්තටික් දත්ත මූලික රටා සඳහා පමණක් නොව, උසස් විශ්ලේෂණ කාර්යයන් සඳහා අවශ්ය ගැඹුරු 'සැඟවුණු' සංඛ්යාන රටා ද ග්රහණය කරයි. දෙවැන්න තීරු ප්රස්ථාරයෙන් පෙන්නුම් කර ඇති අතර, කෘත්රිම දත්ත මත පුහුණු කරන ලද ආකෘතිවල නිරවද්යතාවය සහ මුල් දත්ත මත පුහුණු කරන ලද ආකෘති සමාන බව පෙන්නුම් කරයි. එබැවින්, ආකෘතිවල සැබෑ පුහුණුව සඳහා කෘතිම දත්ත භාවිතා කළ හැක. මුල් දත්ත හා සසඳන විට කෘතිම දත්ත මත ඇල්ගොරිතම මගින් තෝරාගත් යෙදවුම් සහ විචල්ය වැදගත්කම ඉතා සමාන විය. එබැවින්, සැබෑ සංවේදී දත්ත භාවිතා කිරීම සඳහා විකල්පයක් ලෙස, කෘතිම දත්ත මත ආකෘති සැකසීමේ ක්රියාවලිය සිදු කළ හැකි බව නිගමනය කර ඇත.
සම්භාව්ය නිර්නාමිකකරණ ශිල්පීය ක්රමවලට පොදුවේ ඇත්තේ ඔවුන් පුද්ගලයන් සොයා ගැනීමට බාධා කිරීම සඳහා මුල් දත්ත හැසිරවීමයි. ඔවුන් දත්ත හසුරුවන අතර එමගින් ක්රියාවලිය තුළ දත්ත විනාශ කරයි. ඔබ නිර්නාමික කරන තරමට, ඔබේ දත්ත වඩා හොඳින් ආරක්ෂා වේ, නමුත් ඔබේ දත්ත විනාශ වේ. "අනාවැකි බලය" අත්යවශ්ය වන AI සහ ආකෘති නිර්මාණ කාර්යයන් සඳහා මෙය විශේෂයෙන් විනාශකාරී වේ, මන්ද නරක ගුණාත්මක දත්ත AI ආකෘතියෙන් නරක අවබෝධයක් ඇති කරයි. 0.5 ට ආසන්න වක්රය යටතේ (AUC*) ප්රදේශයක් සහිතව SAS විසින් මෙය නිරූපනය කරන ලදී, නිර්නාමික දත්ත මත පුහුණු කරන ලද ආකෘති වඩාත් නරකම ලෙස ක්රියා කරන බව පෙන්නුම් කරයි.
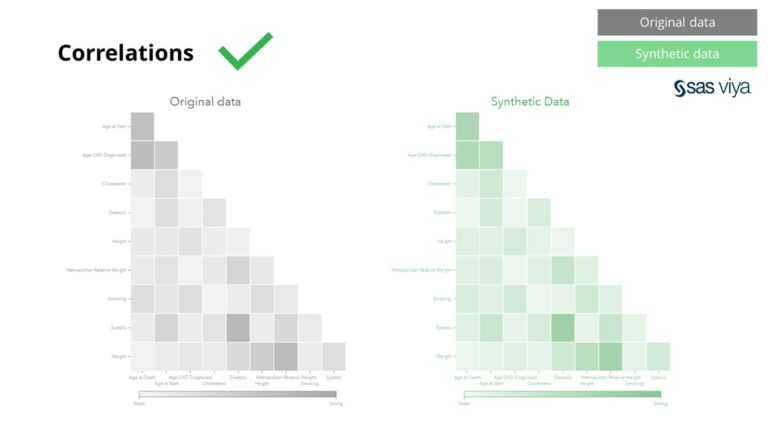
විචල්යයන් අතර සහසම්බන්ධතා සහ සම්බන්ධතා කෘත්රිම දත්තවල නිවැරදිව සංරක්ෂණය කර ඇත.
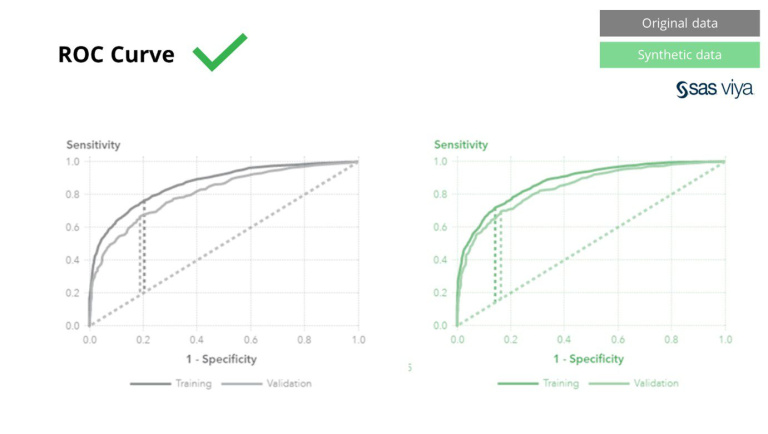
වක්රය යට ප්රදේශය (AUC), ආදර්ශ කාර්ය සාධනය මැනීමේ මෙට්රික් එක ස්ථාවරව පැවතුනි.
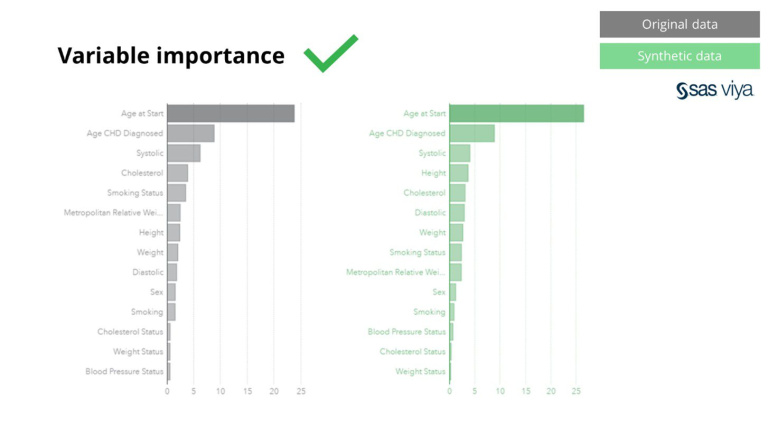
තවද, ආකෘතියක විචල්යවල පුරෝකථන බලය පෙන්නුම් කරන විචල්ය වැදගත්කම, කෘතිම දත්ත මුල් දත්ත කට්ටලයට සංසන්දනය කිරීමේදී නොවෙනස්ව පැවතුනි.
SAS විසින් කරන ලද මෙම නිරීක්ෂණ මත පදනම්ව සහ SAS Viya භාවිතා කිරීමෙන්, Syntho Engine මගින් ජනනය කරන ලද කෘත්රිම දත්ත, ගුණාත්මක භාවයෙන් සත්ය දත්ත හා සමාන බව අපට විශ්වාසයෙන් යුතුව නිගමනය කළ හැක. මෙය ආකෘති සංවර්ධනය සඳහා කෘතිම දත්ත භාවිතය වලංගු කරයි, කෘතිම දත්ත සමඟ උසස් විශ්ලේෂණ සඳහා මග පාදයි.
