ข้อมูลสังเคราะห์ที่สร้างโดย AI เข้าถึงข้อมูลคุณภาพสูงได้ง่ายและรวดเร็ว?
AI สร้างข้อมูลสังเคราะห์ในทางปฏิบัติ
Syntho ผู้เชี่ยวชาญด้านข้อมูลสังเคราะห์ที่สร้างโดย AI ตั้งเป้าที่จะเปลี่ยน privacy by design ได้เปรียบในการแข่งขันด้วยข้อมูลสังเคราะห์ที่สร้างโดย AI ช่วยให้องค์กรต่างๆ สร้างรากฐานข้อมูลที่แข็งแกร่งด้วยการเข้าถึงข้อมูลคุณภาพสูงได้ง่ายและรวดเร็ว และเพิ่งได้รับรางวัลนวัตกรรมจากฟิลิปส์
อย่างไรก็ตาม การสร้างข้อมูลสังเคราะห์ด้วย AI เป็นโซลูชันที่ค่อนข้างใหม่ซึ่งมักจะแนะนำคำถามที่พบบ่อย เพื่อตอบคำถามเหล่านี้ Syntho ได้เริ่มกรณีศึกษาร่วมกับ SAS ซึ่งเป็นผู้นำตลาดในซอฟต์แวร์ Advanced Analytics และ AI
ด้วยความร่วมมือกับ Dutch AI Coalition (NL AIC) พวกเขาตรวจสอบคุณค่าของข้อมูลสังเคราะห์โดยการเปรียบเทียบข้อมูลสังเคราะห์ที่สร้างโดย AI ที่สร้างโดย Syntho Engine กับข้อมูลดั้งเดิมผ่านการประเมินคุณภาพข้อมูล ความถูกต้องตามกฎหมาย และความสามารถในการใช้งานต่างๆ
การเปิดเผยข้อมูลไม่ใช่วิธีแก้ปัญหาหรือไม่?
เทคนิคการปกปิดชื่อแบบคลาสสิกมีเหมือนกันที่พวกเขาจัดการข้อมูลต้นฉบับเพื่อขัดขวางการติดตามบุคคล ตัวอย่าง ได้แก่ การวางนัยทั่วไป การระงับ การล้างข้อมูล การระบุนามแฝง การปกปิดข้อมูล และการสลับแถวและคอลัมน์ คุณสามารถดูตัวอย่างได้ในตารางด้านล่าง
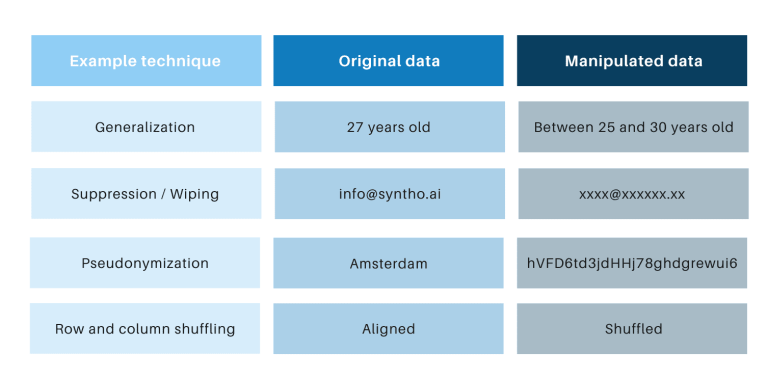
เทคนิคเหล่านี้นำเสนอความท้าทายหลัก 3 ประการ:
- พวกเขาทำงานแตกต่างกันไปตามประเภทข้อมูลและต่อชุดข้อมูล ทำให้ยากต่อการปรับขยาย นอกจากนี้ เนื่องจากทำงานแตกต่างกัน จึงมักมีการถกเถียงกันว่าจะใช้วิธีการใดและต้องใช้เทคนิคใดบ้างร่วมกัน
- มีความสัมพันธ์แบบหนึ่งต่อหนึ่งกับข้อมูลดั้งเดิมอยู่เสมอ ซึ่งหมายความว่าจะมีความเสี่ยงด้านความเป็นส่วนตัวอยู่เสมอ โดยเฉพาะอย่างยิ่งเนื่องจากชุดข้อมูลที่เปิดอยู่ทั้งหมดและเทคนิคที่มีในการเชื่อมโยงชุดข้อมูลเหล่านั้น
- พวกเขาจัดการข้อมูลและด้วยเหตุนี้จึงทำลายข้อมูลในกระบวนการ สิ่งนี้ทำลายล้างโดยเฉพาะอย่างยิ่งสำหรับงาน AI ที่ "พลังการทำนาย" เป็นสิ่งจำเป็น เนื่องจากข้อมูลที่มีคุณภาพไม่ดีจะส่งผลให้เกิดข้อมูลเชิงลึกที่ไม่ดีจากแบบจำลอง AI (ขยะเข้าจะทำให้ขยะออก)
จุดเหล่านี้ได้รับการประเมินผ่านกรณีศึกษานี้ด้วย
บทนำสู่กรณีศึกษา
สำหรับกรณีศึกษา ชุดข้อมูลเป้าหมายเป็นชุดข้อมูลโทรคมนาคมที่ SAS จัดหาให้ซึ่งมีข้อมูลของลูกค้า 56.600 ราย ชุดข้อมูลประกอบด้วย 128 คอลัมน์ รวมถึงหนึ่งคอลัมน์ที่ระบุว่าลูกค้าออกจากบริษัทไปแล้ว (เช่น 'เลิกใช้งาน') หรือไม่ เป้าหมายของกรณีศึกษาคือการใช้ข้อมูลสังเคราะห์เพื่อฝึกแบบจำลองบางตัวเพื่อทำนายการเลิกราของลูกค้าและเพื่อประเมินประสิทธิภาพของแบบจำลองที่ได้รับการฝึกอบรมเหล่านั้น เนื่องจากการคาดคะเนการปั่นเป็นงานการจัดหมวดหมู่ SAS ได้เลือกแบบจำลองการจัดหมวดหมู่ยอดนิยมสี่แบบเพื่อทำการทำนาย ได้แก่:
- ป่าสุ่ม
- ไล่โทนสี
- การถดถอยโลจิสติก
- เครือข่ายประสาทเทียม
ก่อนสร้างข้อมูลสังเคราะห์ SAS สุ่มแบ่งชุดข้อมูลโทรคมนาคมเป็นชุดรถไฟ (สำหรับฝึกโมเดล) และชุดพักสาย (สำหรับการให้คะแนนโมเดล) การมีการแบ่งแยกที่กำหนดไว้สำหรับการให้คะแนนช่วยให้สามารถประเมินอย่างเป็นกลางว่าแบบจำลองการจัดประเภทอาจทำงานได้ดีเพียงใดเมื่อใช้กับข้อมูลใหม่
การใช้ชุดรถไฟเป็นอินพุต Syntho ใช้ Syntho Engine เพื่อสร้างชุดข้อมูลสังเคราะห์ สำหรับการเปรียบเทียบ SAS ยังได้สร้างเวอร์ชันดัดแปลงของชุดรถไฟหลังจากใช้เทคนิคการลบข้อมูลระบุตัวตนต่างๆ เพื่อให้ถึงเกณฑ์ที่กำหนด (ของ k-anonimity) ขั้นตอนก่อนหน้านี้ส่งผลให้เกิดชุดข้อมูลสี่ชุด:
- ชุดข้อมูลรถไฟ (เช่น ชุดข้อมูลดั้งเดิมลบชุดข้อมูลการระงับ)
- ชุดข้อมูล holdout (เช่น ชุดย่อยของชุดข้อมูลเดิม)
- ชุดข้อมูลที่ไม่ระบุชื่อ (ตามชุดข้อมูลรถไฟ)
- ชุดข้อมูลสังเคราะห์ (ตามชุดข้อมูลรถไฟ)
ชุดข้อมูล 1, 3 และ 4 ถูกใช้เพื่อฝึกโมเดลการจำแนกแต่ละแบบ ส่งผลให้มีโมเดลที่ผ่านการฝึกอบรม 12 แบบ (3 x 4) ต่อมา SAS ใช้ชุดข้อมูลการระงับเพื่อวัดความถูกต้องซึ่งแต่ละรุ่นคาดการณ์การเลิกราของลูกค้า ผลลัพธ์แสดงไว้ด้านล่าง โดยเริ่มจากสถิติพื้นฐานบางส่วน
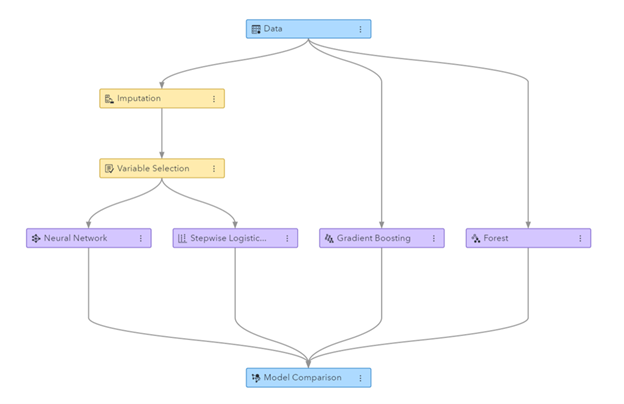
รูป: ไปป์ไลน์ Machine Learning ที่สร้างขึ้นใน SAS Visual Data Mining และ Machine Learning
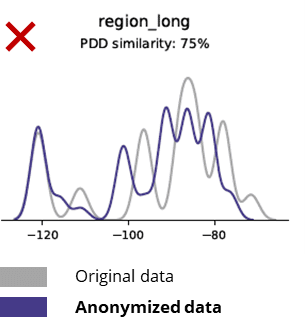
สถิติพื้นฐานเมื่อเปรียบเทียบข้อมูลที่ไม่ระบุตัวตนกับข้อมูลเดิม
เทคนิคการลบข้อมูลระบุตัวตนจะทำลายแม้กระทั่งรูปแบบพื้นฐาน ตรรกะทางธุรกิจ ความสัมพันธ์ และสถิติ (ดังในตัวอย่างด้านล่าง) การใช้ข้อมูลที่ไม่ระบุชื่อสำหรับการวิเคราะห์ขั้นพื้นฐานจึงทำให้เกิดผลลัพธ์ที่ไม่น่าเชื่อถือ อันที่จริง ข้อมูลที่ไม่ระบุตัวตนคุณภาพต่ำทำให้แทบจะเป็นไปไม่ได้เลยที่จะใช้ข้อมูลนี้สำหรับงานวิเคราะห์ขั้นสูง (เช่น การสร้างแบบจำลอง AI/ML และแดชบอร์ด)
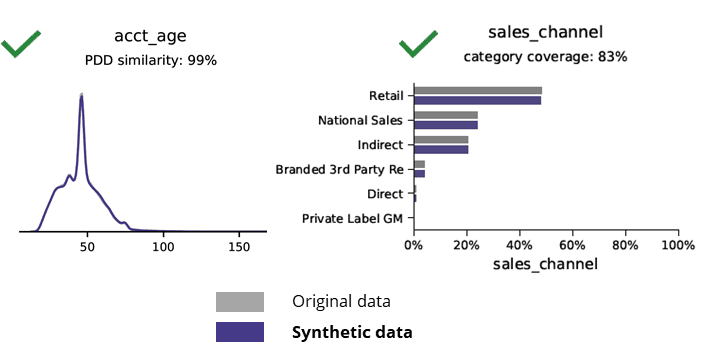
สถิติพื้นฐานเมื่อเปรียบเทียบข้อมูลสังเคราะห์กับข้อมูลเดิม
การสร้างข้อมูลสังเคราะห์ด้วย AI จะรักษารูปแบบพื้นฐาน ตรรกะทางธุรกิจ ความสัมพันธ์ และสถิติ (ดังในตัวอย่างด้านล่าง) การใช้ข้อมูลสังเคราะห์สำหรับการวิเคราะห์ขั้นพื้นฐานจึงให้ผลลัพธ์ที่เชื่อถือได้ คำถามสำคัญ ข้อมูลสังเคราะห์มีไว้สำหรับงานวิเคราะห์ขั้นสูงหรือไม่ (เช่น การสร้างแบบจำลอง AI/ML และแดชบอร์ด)
ข้อมูลสังเคราะห์ที่สร้างโดย AI และการวิเคราะห์ขั้นสูง
ข้อมูลสังเคราะห์ไม่ได้มีไว้สำหรับรูปแบบพื้นฐานเท่านั้น (ดังที่แสดงในแผนภาพก่อนหน้า) แต่ยังจับรูปแบบทางสถิติที่ 'ซ่อน' ไว้อย่างลึกซึ่งจำเป็นสำหรับงานวิเคราะห์ขั้นสูง ส่วนหลังแสดงให้เห็นในแผนภูมิแท่งด้านล่าง ซึ่งบ่งชี้ว่าความแม่นยำของแบบจำลองที่ฝึกด้วยข้อมูลสังเคราะห์กับแบบจำลองที่ฝึกด้วยข้อมูลดั้งเดิมนั้นใกล้เคียงกัน นอกจากนี้ ด้วยพื้นที่ใต้เส้นโค้ง (AUC*) ที่ใกล้กับ 0.5 แบบจำลองที่ได้รับการฝึกจากข้อมูลที่ไม่ระบุตัวตนจะมีประสิทธิภาพแย่ที่สุด รายงานฉบับสมบูรณ์พร้อมการประเมินการวิเคราะห์ขั้นสูงทั้งหมดเกี่ยวกับข้อมูลสังเคราะห์เมื่อเปรียบเทียบกับข้อมูลเดิมสามารถขอได้
*AUC: พื้นที่ใต้เส้นโค้งเป็นการวัดความถูกต้องของแบบจำลองการวิเคราะห์ขั้นสูง โดยพิจารณาถึงผลบวกจริง ผลบวกลวง ผลลบลวง และผลลบจริง 0,5 หมายความว่าแบบจำลองทำนายแบบสุ่มและไม่มีกำลังการทำนาย และ 1 หมายความว่าแบบจำลองนั้นถูกต้องเสมอและมีพลังการทำนายเต็มรูปแบบ
นอกจากนี้ ข้อมูลสังเคราะห์นี้ยังสามารถใช้เพื่อทำความเข้าใจคุณลักษณะของข้อมูลและตัวแปรหลักที่จำเป็นสำหรับการฝึกโมเดลจริง อินพุตที่เลือกโดยอัลกอริธึมในข้อมูลสังเคราะห์เมื่อเทียบกับข้อมูลดั้งเดิมนั้นใกล้เคียงกันมาก ดังนั้น กระบวนการสร้างแบบจำลองสามารถทำได้ในเวอร์ชันสังเคราะห์นี้ ซึ่งช่วยลดความเสี่ยงของการละเมิดข้อมูล อย่างไรก็ตาม เมื่อทำการอนุมานบันทึกแต่ละรายการ (เช่น ลูกค้าของ telco) แนะนำให้ฝึกอบรมซ้ำกับข้อมูลเดิมเพื่อให้สามารถอธิบายได้ การยอมรับเพิ่มขึ้น หรือเพียงเพราะข้อบังคับ
AUC โดยอัลกอริทึมจัดกลุ่มตามวิธี
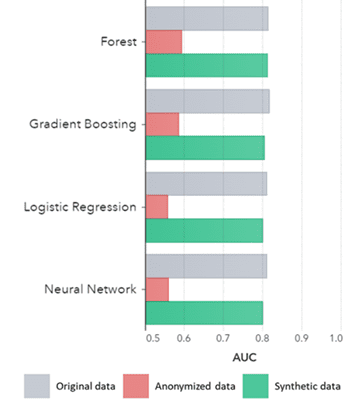
สรุป:
- โมเดลที่ฝึกด้วยข้อมูลสังเคราะห์เมื่อเทียบกับรุ่นที่ฝึกด้วยข้อมูลดั้งเดิมนั้นมีประสิทธิภาพที่ใกล้เคียงกันมาก
- โมเดลที่ได้รับการฝึกฝนเกี่ยวกับข้อมูลที่ไม่ระบุตัวตนด้วย 'เทคนิคการลบข้อมูลระบุตัวตนแบบคลาสสิก' นั้นมีประสิทธิภาพที่ด้อยกว่าเมื่อเทียบกับแบบจำลองที่ฝึกฝนโดยใช้ข้อมูลดั้งเดิมหรือข้อมูลสังเคราะห์
- การสร้างข้อมูลสังเคราะห์ทำได้ง่ายและรวดเร็ว เนื่องจากเทคนิคนี้ทำงานเหมือนกันทุกประการต่อชุดข้อมูลและต่อประเภทข้อมูล
กรณีการใช้ข้อมูลสังเคราะห์เพิ่มมูลค่า
ใช้กรณีที่ 1: ข้อมูลสังเคราะห์สำหรับการพัฒนาแบบจำลองและการวิเคราะห์ขั้นสูง
การมีพื้นฐานข้อมูลที่แข็งแกร่งพร้อมการเข้าถึงข้อมูลคุณภาพสูงที่ใช้งานง่ายและรวดเร็วเป็นสิ่งสำคัญในการพัฒนาแบบจำลอง (เช่น แดชบอร์ด [BI] และการวิเคราะห์ขั้นสูง [AI & ML]) อย่างไรก็ตาม หลายองค์กรประสบปัญหาจากรากฐานของข้อมูลที่ไม่ดีซึ่งส่งผลให้เกิดความท้าทายหลัก 3 ประการ:
- การเข้าถึงข้อมูลใช้เวลานานเนื่องจากกฎระเบียบ (ความเป็นส่วนตัว) กระบวนการภายใน หรือคลังข้อมูล
- เทคนิคการปกปิดชื่อแบบคลาสสิกทำลายข้อมูล ทำให้ข้อมูลไม่เหมาะสำหรับการวิเคราะห์และการวิเคราะห์ขั้นสูงอีกต่อไป (ขยะเข้า = ขยะออก)
- โซลูชันที่มีอยู่ไม่สามารถปรับขนาดได้เนื่องจากทำงานแตกต่างกันตามชุดข้อมูลและต่อประเภทข้อมูล และไม่สามารถจัดการฐานข้อมูลขนาดใหญ่ที่มีหลายตารางได้
แนวทางข้อมูลสังเคราะห์: พัฒนาแบบจำลองด้วยข้อมูลสังเคราะห์ที่ดีเท่าของจริงเพื่อ:
- ลดการใช้ข้อมูลต้นฉบับให้น้อยที่สุดโดยไม่ขัดขวางนักพัฒนาของคุณ
- ปลดล็อกข้อมูลส่วนบุคคลและเข้าถึงข้อมูลเพิ่มเติมที่ถูกจำกัดก่อนหน้านี้ (เช่น เนื่องจากความเป็นส่วนตัว)
- เข้าถึงข้อมูลที่เกี่ยวข้องได้ง่ายและรวดเร็ว
- โซลูชันที่ปรับขนาดได้ซึ่งทำงานเหมือนกันสำหรับแต่ละชุดข้อมูล ประเภทข้อมูล และสำหรับฐานข้อมูลขนาดใหญ่
ซึ่งช่วยให้องค์กรสามารถสร้างรากฐานข้อมูลที่แข็งแกร่งด้วยการเข้าถึงข้อมูลคุณภาพสูงที่ใช้งานได้ง่ายและรวดเร็ว เพื่อปลดล็อกข้อมูลและใช้ประโยชน์จากโอกาสด้านข้อมูล
กรณีการใช้งาน 2: ข้อมูลการทดสอบสังเคราะห์อัจฉริยะสำหรับการทดสอบ การพัฒนา และการส่งมอบซอฟต์แวร์
การทดสอบและการพัฒนาด้วยข้อมูลการทดสอบคุณภาพสูงเป็นสิ่งสำคัญในการนำเสนอโซลูชั่นซอฟต์แวร์ที่ล้ำสมัย การใช้ข้อมูลการผลิตดั้งเดิมนั้นชัดเจน แต่ไม่อนุญาตเนื่องจากกฎระเบียบ (ความเป็นส่วนตัว) ทางเลือก Test Data Management (TDM) เครื่องมือแนะนำ “legacy-by-design” ในการรับข้อมูลการทดสอบที่ถูกต้อง:
- ไม่แสดงข้อมูลการผลิตและตรรกะทางธุรกิจและความสมบูรณ์ของการอ้างอิงจะไม่ถูกรักษาไว้
- ทำงานช้าและใช้เวลานาน
- ต้องใช้มือทำงาน
แนวทางข้อมูลสังเคราะห์: ทดสอบและพัฒนาด้วยข้อมูลการทดสอบสังเคราะห์ที่สร้างโดย AI เพื่อนำเสนอโซลูชันซอฟต์แวร์ที่ล้ำสมัยอย่างชาญฉลาดด้วย:
- ข้อมูลที่เหมือนการผลิตพร้อมตรรกะทางธุรกิจที่เก็บรักษาไว้และความสมบูรณ์ของการอ้างอิง
- สร้างข้อมูลได้ง่ายและรวดเร็วด้วย AI . ที่ล้ำสมัย
- ความเป็นส่วนตัวโดยการออกแบบ
- ง่าย รวดเร็ว และ agile
ซึ่งช่วยให้องค์กรสามารถทดสอบและพัฒนาด้วยข้อมูลการทดสอบระดับถัดไปเพื่อนำเสนอโซลูชั่นซอฟต์แวร์ที่ล้ำสมัย!
ข้อมูลเพิ่มเติม
สนใจ? สำหรับข้อมูลเพิ่มเติมเกี่ยวกับข้อมูลสังเคราะห์ เยี่ยมชมเว็บไซต์ Syntho หรือติดต่อ Wim Kees Janssen ดูข้อมูลเพิ่มเติมเกี่ยวกับ SAS ได้ที่ www.sas.com หรือติดต่อ kees@syntho.ai
ในกรณีการใช้งานนี้ Syntho, SAS และ NL AIC จะทำงานร่วมกันเพื่อให้ได้ผลลัพธ์ตามที่ต้องการ Syntho เป็นผู้เชี่ยวชาญในข้อมูลสังเคราะห์ที่สร้างโดย AI และ SAS เป็นผู้นำตลาดในด้านการวิเคราะห์และนำเสนอซอฟต์แวร์สำหรับการสำรวจ วิเคราะห์ และแสดงข้อมูลเป็นภาพ
* คาดการณ์ปี 2021 – กลยุทธ์ด้านข้อมูลและการวิเคราะห์เพื่อควบคุม ปรับขนาด และพลิกโฉมธุรกิจดิจิทัล, Gartner, 2020

บันทึกคู่มือข้อมูลสังเคราะห์ของคุณตอนนี้!
- ข้อมูลสังเคราะห์คืออะไร?
- ทำไมองค์กรถึงใช้มัน?
- การเพิ่มมูลค่ากรณีไคลเอ็นต์ข้อมูลสังเคราะห์
- วิธีการเริ่มต้น
