ทายซิว่าใคร? 5 ตัวอย่างว่าทำไมการลบชื่อจึงไม่ใช่ตัวเลือก



ทายซิว่าใคร? แม้ว่าฉันจะแน่ใจว่าพวกคุณส่วนใหญ่รู้จักเกมนี้ตั้งแต่สมัยก่อนแล้วก็ตาม แต่นี่เป็นบทสรุปสั้น ๆ เป้าหมายของเกม: ค้นหาชื่อของตัวการ์ตูนที่เลือกโดยคู่ต่อสู้ของคุณโดยถามคำถามว่า "ใช่" และ "ไม่ใช่" เช่น 'บุคคลนั้นสวมหมวกหรือไม่' หรือ 'คนใส่แว่น'? ผู้เล่นกำจัดผู้สมัครตามการตอบสนองของฝ่ายตรงข้ามและเรียนรู้คุณลักษณะที่เกี่ยวข้องกับตัวละครลึกลับของคู่ต่อสู้ ผู้เล่นคนแรกที่ค้นพบตัวละครลึกลับของผู้เล่นคนอื่นชนะเกม
คุณได้รับมัน หนึ่งต้องระบุบุคคลจากชุดข้อมูลโดยมีสิทธิ์เข้าถึงแอตทริบิวต์ที่เกี่ยวข้องเท่านั้น อันที่จริง เราเห็นแนวคิดของ Guess Who ที่นำไปใช้ในทางปฏิบัติเป็นประจำ แต่จากนั้นก็นำไปใช้กับชุดข้อมูลที่จัดรูปแบบด้วยแถวและคอลัมน์ที่มีคุณลักษณะของคนจริง ความแตกต่างหลักเมื่อทำงานกับข้อมูลก็คือ ผู้คนมักจะดูถูกดูแคลนความสะดวกที่บุคคลจริงสามารถเปิดโปงได้โดยการเข้าถึงคุณลักษณะเพียงไม่กี่อย่างเท่านั้น
ดังที่เกม Guess Who แสดงให้เห็น ใครบางคนสามารถระบุตัวบุคคลได้ด้วยการเข้าถึงคุณลักษณะเพียงไม่กี่อย่าง มันทำหน้าที่เป็นตัวอย่างง่ายๆ ว่าทำไมการลบเฉพาะ 'ชื่อ' (หรือตัวระบุโดยตรงอื่นๆ) ออกจากชุดข้อมูลของคุณจึงล้มเหลวเนื่องจากเทคนิคการลบข้อมูลระบุตัวตน ในบล็อกนี้ เรามีกรณีที่ใช้งานได้จริงสี่กรณีเพื่อแจ้งให้คุณทราบเกี่ยวกับความเสี่ยงด้านความเป็นส่วนตัวที่เกี่ยวข้องกับการลบคอลัมน์เพื่อเป็นการปกปิดข้อมูล
ความเสี่ยงของการโจมตีแบบเชื่อมโยงเป็นสาเหตุที่สำคัญที่สุดที่ทำให้การลบชื่อออกเพียงอย่างเดียวไม่ได้ผล (อีกต่อไป) เป็นวิธีการทำให้ไม่เปิดเผยชื่อ ด้วยการโจมตีแบบเชื่อมโยง ผู้โจมตีจะรวมข้อมูลดั้งเดิมกับแหล่งข้อมูลอื่นที่สามารถเข้าถึงได้เพื่อระบุตัวบุคคลและเรียนรู้ข้อมูล (มักจะละเอียดอ่อน) เกี่ยวกับบุคคลนี้
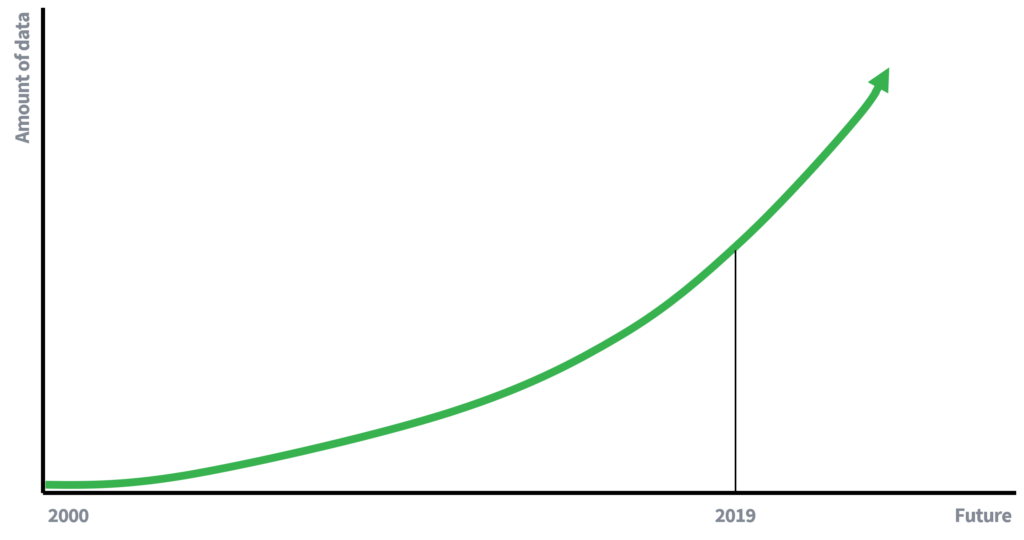
กุญแจสำคัญคือความพร้อมใช้งานของแหล่งข้อมูลอื่นๆ ที่มีอยู่ในขณะนี้ หรืออาจมีอยู่ในอนาคต คิดถึงตัวเอง. ข้อมูลส่วนตัวของคุณสามารถพบได้บน Facebook, Instagram หรือ LinkedIn ที่อาจถูกนำไปใช้ในทางที่ผิดสำหรับการโจมตีแบบเชื่อมโยงได้อย่างไร?
ในสมัยก่อน ความพร้อมใช้งานของข้อมูลมีจำกัด ซึ่งส่วนหนึ่งอธิบายได้ว่าทำไมการลบชื่อจึงเพียงพอที่จะรักษาความเป็นส่วนตัวของบุคคล ข้อมูลที่มีน้อยลงหมายถึงโอกาสในการเชื่อมโยงข้อมูลน้อยลง อย่างไรก็ตาม ขณะนี้เรา (ใช้งานอยู่) มีส่วนร่วมในเศรษฐกิจที่ขับเคลื่อนด้วยข้อมูล ซึ่งปริมาณข้อมูลเติบโตในอัตราเลขชี้กำลัง ข้อมูลเพิ่มเติมและการปรับปรุงเทคโนโลยีสำหรับการรวบรวมข้อมูลจะนำไปสู่ศักยภาพในการโจมตีที่เชื่อมโยงกันมากขึ้น อะไรจะเขียนใน 10 ปีเกี่ยวกับความเสี่ยงของการโจมตีเชื่อมโยง?
ภาพประกอบ 1
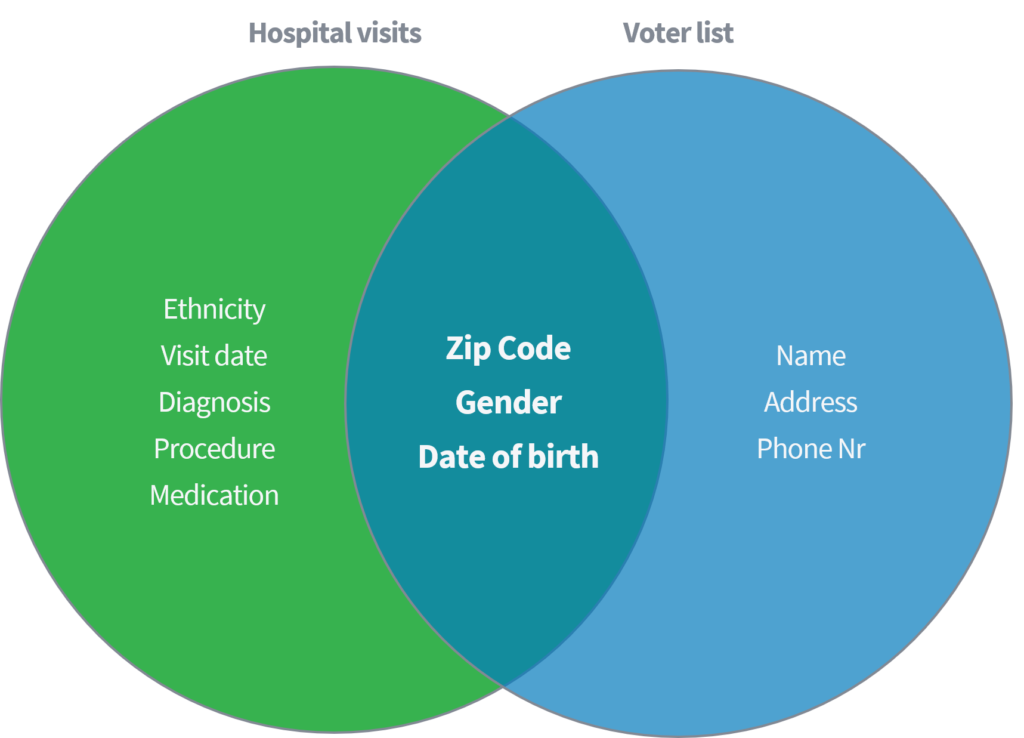
Sweeney (2002) แสดงให้เห็นในเอกสารวิชาการว่าเธอสามารถระบุและเรียกข้อมูลทางการแพทย์ที่ละเอียดอ่อนจากบุคคลโดยอิงจากการเชื่อมโยงชุดข้อมูลสาธารณะของ 'การเยี่ยมโรงพยาบาล' ที่เปิดเผยต่อสาธารณะไปยังนายทะเบียนการลงคะแนนเสียงที่เปิดเผยต่อสาธารณะในสหรัฐอเมริกา ชุดข้อมูลทั้งสองชุดที่ถือว่าไม่ระบุชื่ออย่างถูกต้องผ่านการลบชื่อและตัวระบุโดยตรงอื่นๆ
ภาพประกอบ 2
จากพารามิเตอร์สามตัวเท่านั้น (1) รหัสไปรษณีย์ (2) เพศ และ (3) วันเดือนปีเกิด เธอแสดงให้เห็นว่า 87% ของประชากรสหรัฐทั้งหมดสามารถระบุได้อีกครั้งโดยจับคู่แอตทริบิวต์ดังกล่าวจากชุดข้อมูลทั้งสองชุด จากนั้นสวีนีย์ก็ทำงานของเธอซ้ำอีกครั้งโดยมี 'ประเทศ' เป็นทางเลือกแทน 'รหัสไปรษณีย์' นอกจากนี้ เธอยังแสดงให้เห็นว่า 18% ของประชากรทั้งหมดในสหรัฐอเมริกาสามารถระบุได้โดยการเข้าถึงชุดข้อมูลที่มีข้อมูลเกี่ยวกับ (1) ประเทศบ้านเกิด (2) เพศ และ (3) วันเดือนปีเกิดเท่านั้น ลองนึกถึงแหล่งข้อมูลสาธารณะที่กล่าวถึงข้างต้น เช่น Facebook, LinkedIn หรือ Instagram ประเทศ เพศ และวันเกิดของคุณสามารถมองเห็นได้หรือผู้ใช้รายอื่นสามารถหักเงินได้หรือไม่
ภาพประกอบ 3
| ตัวระบุเสมือน | % ระบุเฉพาะของประชากรสหรัฐ (248 ล้านคน) |
| รหัสไปรษณีย์ 5 หลัก เพศ วันเดือนปีเกิด | ลด 87% |
| สถานที่, เพศ, วันเดือนปีเกิด | ลด 53% |
| ประเทศ, เพศ, วันเดือนปีเกิด | ลด 18% |
ตัวอย่างนี้แสดงให้เห็นว่าการลบชื่อบุคคลในข้อมูลที่ดูเหมือนไม่ระบุตัวตนเป็นเรื่องง่ายอย่างน่าทึ่ง ประการแรก การศึกษานี้บ่งชี้ถึงความเสี่ยงอย่างใหญ่หลวง เช่น 87% ของประชากรสหรัฐสามารถระบุได้อย่างง่ายดายโดยใช้ ลักษณะเล็กน้อย. ประการที่สอง ข้อมูลทางการแพทย์ที่เปิดเผยในการศึกษานี้มีความไวสูง ตัวอย่างข้อมูลของบุคคลที่ถูกเปิดเผยจากชุดข้อมูลการเข้ารับการตรวจในโรงพยาบาล ได้แก่ เชื้อชาติ การวินิจฉัย และการใช้ยา คุณลักษณะที่อาจเก็บเป็นความลับ เช่น จากบริษัทประกันภัย
ความเสี่ยงอีกประการหนึ่งในการลบเฉพาะตัวระบุโดยตรง เช่น ชื่อ เกิดขึ้นเมื่อบุคคลที่ได้รับแจ้งมีความรู้หรือข้อมูลเกี่ยวกับลักษณะหรือพฤติกรรมเฉพาะของบุคคลในชุดข้อมูลที่เหนือกว่า. จากความรู้ของพวกเขา ผู้โจมตีอาจสามารถเชื่อมโยงบันทึกข้อมูลเฉพาะกับบุคคลจริงได้
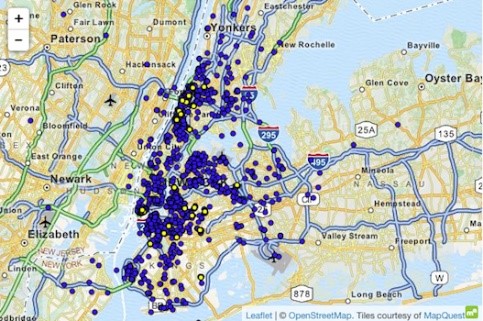
ตัวอย่างของการโจมตีชุดข้อมูลโดยใช้ความรู้ที่เหนือกว่าคือกรณีรถแท็กซี่ในนิวยอร์ก ซึ่ง Atocar (2014) สามารถเปิดโปงบุคคลที่เฉพาะเจาะจงได้ ชุดข้อมูลดังกล่าวประกอบด้วยการเดินทางโดยแท็กซี่ทั้งหมดในนิวยอร์ก ซึ่งเสริมด้วยคุณลักษณะพื้นฐาน เช่น พิกัดเริ่มต้น พิกัดสิ้นสุด ราคา และจุดสิ้นสุดของการเดินทาง
บุคคลที่มีข้อมูลซึ่งรู้ว่านิวยอร์กสามารถใช้บริการรถแท็กซี่ไปยังสโมสรสำหรับผู้ใหญ่ 'Hustler' ได้ โดยการกรอง 'ตำแหน่งสิ้นสุด' เขาอนุมานที่อยู่เริ่มต้นที่แน่นอนและด้วยเหตุนี้จึงระบุผู้เยี่ยมชมหลายราย ในทำนองเดียวกัน เราสามารถสรุปการนั่งแท็กซี่ได้เมื่อทราบที่อยู่บ้านของบุคคลนั้น เวลาและสถานที่ของดาราภาพยนตร์ที่มีชื่อเสียงหลายคนถูกค้นพบในไซต์ซุบซิบ หลังจากเชื่อมโยงข้อมูลนี้กับข้อมูลรถแท็กซี่ของ NYC แล้ว ก็สามารถเรียกแท็กซี่ได้ จำนวนเงินที่จ่ายไป และให้ทิปได้ง่ายหรือไม่
ภาพประกอบ 4
พิกัดไปส่ง Hustler
แบรดลีย์คูเปอร์
Jessica Alba
ข้อโต้แย้งทั่วไปคือ 'ข้อมูลนี้ไร้ค่า' หรือ 'ไม่มีใครสามารถทำอะไรกับข้อมูลนี้ได้' นี้มักจะเป็นความเข้าใจผิด แม้แต่ข้อมูลที่ไร้เดียงสาที่สุดก็สามารถสร้าง 'ลายนิ้วมือ' ที่ไม่เหมือนใครและใช้เพื่อระบุตัวบุคคลได้อีกครั้ง เป็นความเสี่ยงที่เกิดจากความเชื่อที่ว่าตัวข้อมูลเองนั้นไร้ค่าทั้งๆ ที่มันไม่ใช่
ความเสี่ยงในการระบุตัวตนจะเพิ่มขึ้นตามการเพิ่มขึ้นของข้อมูล AI ตลอดจนเครื่องมือและอัลกอริทึมอื่นๆ ที่ช่วยให้สามารถเปิดเผยความสัมพันธ์ที่ซับซ้อนในข้อมูลได้ ดังนั้น แม้ว่าชุดข้อมูลของคุณจะไม่ถูกเปิดเผยในตอนนี้ และน่าจะไร้ประโยชน์สำหรับบุคคลที่ไม่ได้รับอนุญาตในวันนี้ แต่อาจไม่ใช่พรุ่งนี้
ตัวอย่างที่ดีคือกรณีที่ Netflix ตั้งใจจะรวบรวมแผนก R&D ของทางบริษัทด้วยการแนะนำการแข่งขัน Netflix แบบเปิดเพื่อปรับปรุงระบบแนะนำภาพยนตร์ของตน 'สิ่งที่ปรับปรุงอัลกอริธึมการกรองการทำงานร่วมกันเพื่อคาดการณ์การให้คะแนนของผู้ใช้สำหรับภาพยนตร์จะได้รับรางวัลมูลค่า 1,000,000 เหรียญสหรัฐ' เพื่อรองรับฝูงชน Netflix ได้เผยแพร่ชุดข้อมูลที่มีเฉพาะแอตทริบิวต์พื้นฐานต่อไปนี้: รหัสผู้ใช้ ภาพยนตร์ วันที่เกรดและเกรด (ดังนั้นจึงไม่มีข้อมูลเพิ่มเติมเกี่ยวกับผู้ใช้หรือตัวภาพยนตร์เอง)
ภาพประกอบ 5
| หมายเลขผู้ใช้ | Movie | วันที่เรียน | เกรด |
| 123456789 | ภารกิจไปไม่ได้ | 10-12-2008 | 4 |
ข้อมูลปรากฏว่าไร้ประโยชน์ เมื่อถามคำถาม 'มีข้อมูลลูกค้าในชุดข้อมูลที่ควรเก็บไว้เป็นความลับหรือไม่' คำตอบคือ:
'ไม่ ข้อมูลระบุตัวตนลูกค้าทั้งหมดถูกลบออก สิ่งที่เหลืออยู่คือการให้คะแนนและวันที่ เป็นไปตามนโยบายความเป็นส่วนตัวของเรา …'
อย่างไรก็ตาม Narayanan (2008) จาก University of Texas at Austin ได้พิสูจน์เป็นอย่างอื่น การรวมกันของเกรด วันที่ของเกรด และภาพยนตร์ของแต่ละบุคคลทำให้เกิดลายนิ้วมือของภาพยนตร์ที่ไม่เหมือนใคร นึกถึงพฤติกรรม Netflix ของคุณเอง คุณคิดว่ามีคนดูหนังชุดเดียวกันกี่คน? ดูหนังชุดเดียวกันพร้อมกันกี่เรื่อง?
คำถามหลัก จะจับคู่ลายนิ้วมือนี้ได้อย่างไร? มันค่อนข้างง่าย จากข้อมูลจากเว็บไซต์จัดอันดับภาพยนตร์ที่มีชื่อเสียง IMDb (ฐานข้อมูลภาพยนตร์อินเทอร์เน็ต) สามารถสร้างลายนิ้วมือที่คล้ายกันได้ จึงสามารถระบุตัวบุคคลได้อีกครั้ง
แม้ว่าพฤติกรรมการชมภาพยนตร์อาจไม่ถูกมองว่าเป็นข้อมูลที่ละเอียดอ่อน แต่ให้นึกถึงพฤติกรรมของคุณเอง – คุณจะรังเกียจไหมหากเผยแพร่สู่สาธารณะ ตัวอย่างที่ Narayanan ระบุไว้ในบทความคือความชอบทางการเมือง (การให้คะแนนเรื่อง 'Jesus of Nazareth' และ 'The Gospel of John') และความพึงพอใจทางเพศ (การให้คะแนนเรื่อง 'Bent' และ 'Queer as folk') ที่กลั่นกรองได้ง่าย
GDPR อาจไม่น่าตื่นเต้นอย่างยิ่ง หรือเป็นหัวข้อย่อยสีเงินในหัวข้อบล็อก อย่างไรก็ตาม การให้คำจำกัดความอย่างตรงไปตรงมาเมื่อประมวลผลข้อมูลส่วนบุคคลนั้นมีประโยชน์ เนื่องจากบล็อกนี้เกี่ยวกับความเข้าใจผิดทั่วไปในการลบคอลัมน์เพื่อปกปิดข้อมูลและให้ความรู้แก่คุณในฐานะผู้ประมวลผลข้อมูล ให้เราเริ่มต้นด้วยการสำรวจคำจำกัดความของการไม่เปิดเผยชื่อตาม GDPR
ตามบทบรรยายที่ 26 จาก GDPR ข้อมูลที่ไม่เปิดเผยตัวตนถูกกำหนดเป็น:
'ข้อมูลที่ไม่เกี่ยวข้องกับบุคคลธรรมดาที่ระบุหรือระบุตัวตนได้หรือข้อมูลส่วนบุคคลที่ไม่ระบุตัวตนในลักษณะที่เจ้าของข้อมูลไม่สามารถระบุได้หรือไม่สามารถระบุได้อีกต่อไป'
เนื่องจากบุคคลหนึ่งประมวลผลข้อมูลส่วนบุคคลที่เกี่ยวข้องกับบุคคลธรรมดา คำจำกัดความเฉพาะส่วนที่ 2 เท่านั้นที่เกี่ยวข้อง เพื่อให้เป็นไปตามคำจำกัดความ เราต้องแน่ใจว่าเจ้าของข้อมูล (บุคคล) ไม่สามารถระบุตัวตนได้หรือไม่ได้อีกต่อไป อย่างไรก็ตาม ตามที่ระบุไว้ในบล็อกนี้ การระบุตัวบุคคลโดยอาศัยคุณลักษณะบางอย่างนั้นง่ายมากอย่างน่าทึ่ง ดังนั้น การลบชื่อออกจากชุดข้อมูลจึงไม่เป็นไปตามคำจำกัดความของ GDPR ของการไม่เปิดเผยชื่อ
เราท้าทายวิธีหนึ่งที่พิจารณาโดยทั่วไป และน่าเสียดายที่ยังคงใช้วิธีการที่ไม่ระบุชื่อข้อมูลบ่อยครั้ง นั่นคือการลบชื่อ ในเกม Guess Who และอีกสี่ตัวอย่างเกี่ยวกับ:
มันแสดงให้เห็นว่าการลบชื่อล้มเหลวในการทำให้ไม่เปิดเผยชื่อ แม้ว่าตัวอย่างจะเป็นกรณีที่น่าสนใจ แต่แต่ละรายการก็แสดงให้เห็นถึงความเรียบง่ายของการระบุตัวตนอีกครั้ง และผลกระทบด้านลบที่อาจเกิดขึ้นต่อความเป็นส่วนตัวของบุคคล
โดยสรุป การลบชื่อออกจากชุดข้อมูลของคุณไม่ส่งผลให้มีข้อมูลที่ไม่ระบุตัวตน ดังนั้น เราจึงควรหลีกเลี่ยงการใช้ทั้งสองคำแทนกัน ฉันหวังเป็นอย่างยิ่งว่าคุณจะไม่ใช้วิธีนี้ในการปกปิดชื่อ และหากคุณยังคงทำอยู่ ตรวจสอบให้แน่ใจว่าคุณและทีมของคุณเข้าใจความเสี่ยงด้านความเป็นส่วนตัวอย่างครบถ้วน และได้รับอนุญาตให้ยอมรับความเสี่ยงเหล่านั้นในนามของบุคคลที่ได้รับผลกระทบ
ติดต่อ Syntho และหนึ่งในผู้เชี่ยวชาญของเราจะติดต่อคุณด้วยความเร็วแสงเพื่อสำรวจคุณค่าของข้อมูลสังเคราะห์!