Syntetické údaje generované AI, jednoduchý a rýchly prístup k vysokokvalitným údajom?
AI generovala syntetické dáta v praxi
Syntho, odborník na syntetické dáta generované AI, sa chce obrátiť privacy by design do konkurenčnej výhody so syntetickými údajmi generovanými AI. Pomáhajú organizáciám vybudovať silnú dátovú základňu s jednoduchým a rýchlym prístupom k vysokokvalitným dátam a nedávno získali ocenenie Philips Innovation Award.
Generovanie syntetických údajov pomocou AI je však relatívne nové riešenie, ktoré zvyčajne prináša často kladené otázky. Aby sme na ne odpovedali, spoločnosť Syntho začala prípadovú štúdiu spolu so spoločnosťou SAS, lídrom na trhu v oblasti softvéru Advanced Analytics a AI.
V spolupráci s holandskou koalíciou AI (NL AIC) skúmali hodnotu syntetických údajov porovnaním syntetických údajov generovaných AI generovaných systémom Syntho Engine s pôvodnými údajmi prostredníctvom rôznych hodnotení kvality údajov, právnej platnosti a použiteľnosti.
Nie je anonymizácia údajov riešením?
Klasické anonymizačné techniky majú spoločné to, že manipulujú s pôvodnými údajmi, aby zabránili spätnému vysledovaniu jednotlivcov. Príkladmi sú zovšeobecnenie, potlačenie, vymazanie, pseudonymizácia, maskovanie údajov a miešanie riadkov a stĺpcov. Príklady nájdete v tabuľke nižšie.
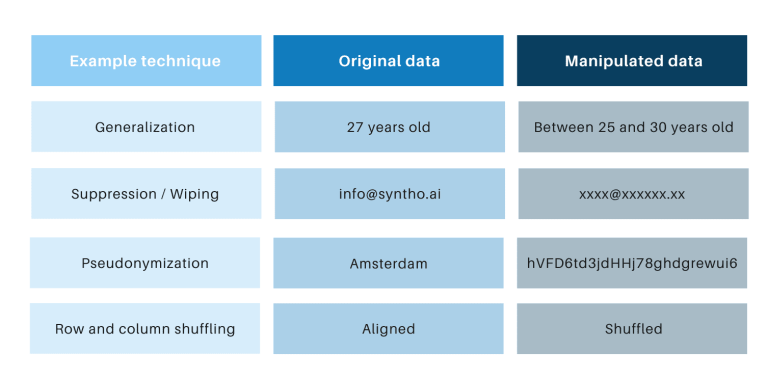
Tieto techniky prinášajú 3 kľúčové výzvy:
- Fungujú odlišne v závislosti od typu údajov a množiny údajov, čo sťažuje ich škálovanie. Okrem toho, keďže fungujú odlišne, vždy sa bude diskutovať o tom, ktoré metódy použiť a aká kombinácia techník je potrebná.
- Vždy existuje vzťah jedna k jednej s pôvodnými údajmi. To znamená, že vždy bude existovať riziko ochrany súkromia, najmä kvôli všetkým otvoreným súborom údajov a dostupným technikám na prepojenie týchto súborov údajov.
- Manipulujú s údajmi a tým údaje v procese ničia. Toto je obzvlášť zničujúce pre úlohy AI, kde je nevyhnutná „prediktívna sila“, pretože nekvalitné údaje budú mať za následok zlé poznatky z modelu AI (Garbage-in bude mať za následok odpadnutie).
Tieto body sú tiež hodnotené prostredníctvom tejto prípadovej štúdie.
Úvod do prípadovej štúdie
Pre prípadovú štúdiu bol cieľovým súborom údajov telekomunikačný súbor údajov poskytnutý spoločnosťou SAS obsahujúci údaje 56.600 128 zákazníkov. Súbor údajov obsahuje XNUMX stĺpcov, vrátane jedného stĺpca, ktorý označuje, či zákazník opustil spoločnosť (tj „vyhodil“) alebo nie. Cieľom prípadovej štúdie bolo použiť syntetické údaje na trénovanie niektorých modelov na predpovedanie odchodu zákazníkov a na vyhodnotenie výkonnosti týchto trénovaných modelov. Keďže predikcia miznutia je klasifikačná úloha, SAS vybral štyri populárne klasifikačné modely na predpovede, vrátane:
- Náhodný les
- Zosilnenie gradientu
- Logistická regresia
- Neurónová sieť
Pred vygenerovaním syntetických údajov SAS náhodne rozdelí telekomunikačný súbor údajov na vlakovú súpravu (na trénovanie modelov) a vypínaciu súpravu (na hodnotenie modelov). Samostatná súprava bodov na hodnotenie umožňuje nezaujaté posúdenie toho, ako dobre by mohol model klasifikácie fungovať pri aplikácii na nové údaje.
Použitím vlakovej súpravy ako vstupu, Syntho použil svoj Syntho Engine na generovanie syntetického súboru údajov. Pre benchmarking SAS vytvoril aj manipulovanú verziu vlakovej súpravy po aplikovaní rôznych anonymizačných techník na dosiahnutie určitého prahu (k-anonymity). Predchádzajúce kroky vyústili do štyroch súborov údajov:
- Súbor údajov o vlaku (tj pôvodný súbor údajov mínus súbor údajov o pozastavení)
- Zádržný súbor údajov (tj podmnožina pôvodného súboru údajov)
- Anonymizovaný súbor údajov (na základe súboru údajov o vlaku)
- Syntetický súbor údajov (založený na súbore údajov o vlaku)
Súbory údajov 1, 3 a 4 sa použili na trénovanie každého klasifikačného modelu, výsledkom čoho bolo 12 (3 x 4) trénovaných modelov. Spoločnosť SAS následne použila tento súbor údajov na meranie presnosti, s akou každý model predpovedá odchod zákazníkov. Výsledky sú uvedené nižšie, počnúc niekoľkými základnými štatistikami.
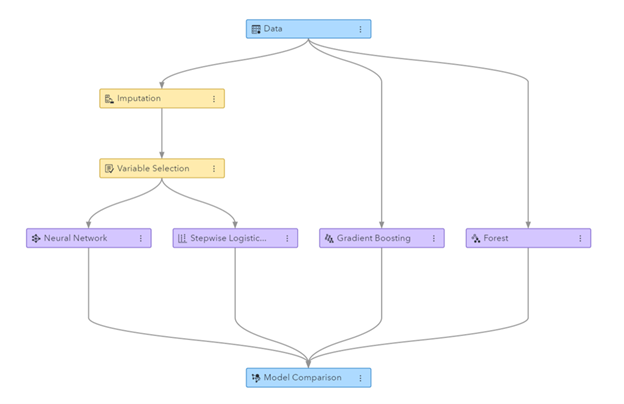
Obrázok: Priebeh strojového učenia vygenerovaný v SAS Visual Data Mining a Machine Learning
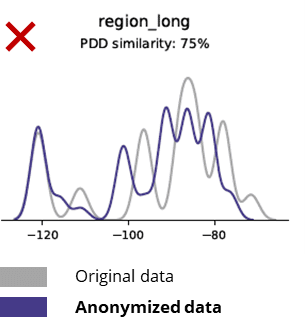
Základné štatistiky pri porovnávaní anonymizovaných údajov s pôvodnými údajmi
Anonymizačné techniky ničia aj základné vzorce, obchodnú logiku, vzťahy a štatistiky (ako v príklade nižšie). Používanie anonymizovaných údajov na základnú analýzu tak prináša nespoľahlivé výsledky. Nízka kvalita anonymizovaných údajov v skutočnosti takmer znemožňovala ich použitie na pokročilé analytické úlohy (napr. modelovanie AI/ML a dashboarding).
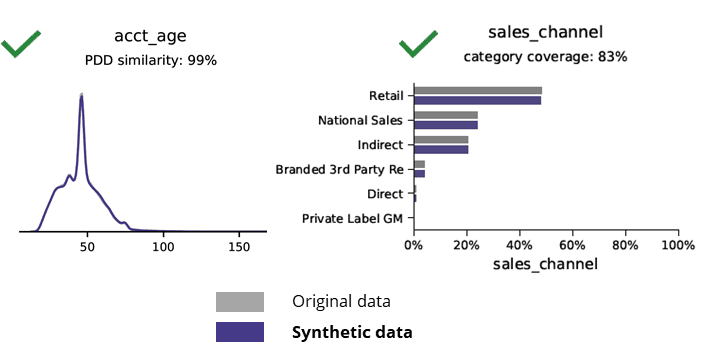
Základné štatistiky pri porovnávaní syntetických údajov s pôvodnými údajmi
Generovanie syntetických údajov pomocou AI zachováva základné vzorce, obchodnú logiku, vzťahy a štatistiky (ako v príklade nižšie). Použitie syntetických údajov na základnú analýzu tak poskytuje spoľahlivé výsledky. Kľúčová otázka, platia syntetické údaje pre pokročilé analytické úlohy (napr. modelovanie AI/ML a dashboarding)?
Syntetické údaje vygenerované AI a pokročilé analýzy
Syntetické údaje platia nielen pre základné vzory (ako je znázornené na predchádzajúcich grafoch), ale zachytávajú aj hlboké „skryté“ štatistické vzorce potrebné pre pokročilé analytické úlohy. Posledné uvedené je znázornené v stĺpcovom grafe nižšie, čo naznačuje, že presnosť modelov trénovaných na syntetických údajoch oproti modelom trénovaným na pôvodných údajoch je podobná. Okrem toho, s plochou pod krivkou (AUC*) blízkou 0.5 majú modely trénované na anonymizovaných údajoch zďaleka najhoršie výsledky. Úplná správa so všetkými pokročilými analytickými hodnoteniami syntetických údajov v porovnaní s pôvodnými údajmi je k dispozícii na vyžiadanie.
*AUC: plocha pod krivkou je mierou presnosti pokročilých analytických modelov, berúc do úvahy skutočne pozitívne, falošne pozitívne, falošne negatívne a skutočne negatívne výsledky. 0,5 znamená, že model predpovedá náhodne a nemá žiadnu predikčnú silu a 1 znamená, že model je vždy správny a má plnú predikčnú silu.
Okrem toho môžu byť tieto syntetické údaje použité na pochopenie údajových charakteristík a hlavných premenných potrebných na skutočné trénovanie modelov. Vstupy vybrané algoritmami na syntetických údajoch v porovnaní s pôvodnými údajmi boli veľmi podobné. Proces modelovania sa teda môže vykonávať na tejto syntetickej verzii, čo znižuje riziko narušenia údajov. Pri vyvodzovaní individuálnych záznamov (napr. telco zákazník) sa však odporúča preškolenie na pôvodné údaje z dôvodu vysvetliteľnosti, zvýšenej akceptácie alebo len z dôvodu regulácie.
AUC podľa algoritmu zoskupené podľa metódy
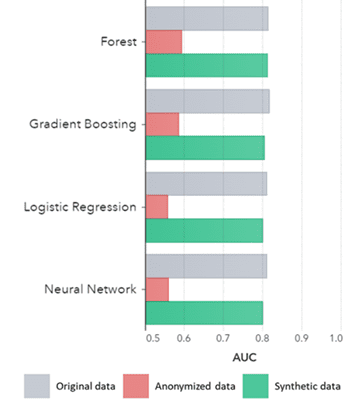
Závery:
- Modely trénované na syntetických údajoch v porovnaní s modelmi trénovanými na pôvodných údajoch vykazujú veľmi podobný výkon
- Modely trénované na anonymizovaných údajoch pomocou „klasických anonymizačných techník“ vykazujú horší výkon v porovnaní s modelmi trénovanými na pôvodných údajoch alebo syntetických údajoch
- Generovanie syntetických údajov je jednoduché a rýchle, pretože technika funguje presne rovnako pre množinu údajov a pre typ údajov.
Prípady použitia syntetických údajov s pridanou hodnotou
Prípad použitia 1: Syntetické údaje pre vývoj modelov a pokročilú analýzu
Silný dátový základ s jednoduchým a rýchlym prístupom k použiteľným a vysokokvalitným údajom je nevyhnutný na vývoj modelov (napr. dashboardy [BI] a pokročilé analýzy [AI & ML]). Mnohé organizácie však trpia neoptimálnym dátovým základom, čo má za následok 3 kľúčové výzvy:
- Získanie prístupu k údajom trvá vekom kvôli predpisom (na ochranu osobných údajov), interným procesom alebo dátovým silám
- Klasické anonymizačné techniky ničia údaje, čím sa údaje stávajú nevhodnými na analýzu a pokročilú analýzu (odpadky dovnútra = odpadky von)
- Existujúce riešenia nie sú škálovateľné, pretože fungujú odlišne podľa množiny údajov a podľa typu údajov a nedokážu spracovať veľké databázy s viacerými tabuľkami.
Prístup k syntetickým údajom: vytvorte modely so syntetickými údajmi, ktoré sú rovnako dobré ako skutočné, aby:
- Minimalizujte používanie pôvodných údajov bez toho, aby ste prekážali svojim vývojárom
- Odomknite osobné údaje a získajte prístup k ďalším údajom, ktoré boli predtým obmedzené (napr. Z dôvodu ochrany osobných údajov)
- Jednoduchý a rýchly prístup k relevantným údajom
- Škálovateľné riešenie, ktoré funguje rovnako pre každý súbor údajov, typ údajov a pre rozsiahle databázy
To umožňuje organizácii vybudovať silnú dátovú základňu s jednoduchým a rýchlym prístupom k použiteľným, vysokokvalitným dátam na odomknutie dát a využitie dátových príležitostí.
Prípad použitia 2: dáta z inteligentných syntetických testov na testovanie, vývoj a dodávku softvéru
Testovanie a vývoj s vysokokvalitnými testovacími údajmi je nevyhnutný na poskytovanie najmodernejších softvérových riešení. Používanie pôvodných výrobných údajov sa zdá byť samozrejmosťou, ale nie je povolené kvôli predpisom o ochrane súkromia. Alternatívne Test Data Management (TDM) nástroje zavádzajú „legacy-by-design” pri správnom získavaní testovacích údajov:
- Neodrážajú produkčné údaje a obchodná logika a referenčná integrita nie sú zachované
- Pracujte pomaly a časovo náročné
- Vyžaduje sa manuálna práca
Prístup k syntetickým údajom: Testujte a vyvíjajte pomocou syntetických testovacích údajov generovaných AI, aby ste mohli poskytovať najmodernejšie softvérové riešenia inteligentne s:
- Dáta podobné produkcii so zachovanou obchodnou logikou a referenčnou integritou
- Jednoduché a rýchle generovanie údajov s najmodernejšou AI
- Ochrana súkromia už od návrhu
- Jednoduché, rýchle a agile
To umožňuje organizácii testovať a vyvíjať s testovacími dátami ďalšej úrovne a poskytovať najmodernejšie softvérové riešenia!
Viac informácií
Máte záujem? Pre viac informácií o syntetických dátach navštívte webovú stránku Syntho alebo kontaktujte Wima Keesa Janssena. Pre viac informácií o SAS navštívte www.sas.com alebo kontaktujte kees@syntho.ai.
V tomto prípade použitia Syntho, SAS a NL AIC spolupracujú na dosiahnutí zamýšľaných výsledkov. Syntho je expertom na syntetické dáta generované AI a SAS je lídrom na trhu v oblasti analytiky a ponúka softvér na skúmanie, analýzu a vizualizáciu dát.
* Predpovede do roku 2021 – Dátové a analytické stratégie na riadenie, škálovanie a transformáciu digitálneho podnikania, Gartner, 2020.

Uložte si svojho sprievodcu syntetickými údajmi teraz!
- Čo sú syntetické údaje?
- Prečo to organizácie používajú?
- Prípady klientov so syntetickými údajmi s pridanou hodnotou
- Ako začať
