


Data sintetik yang dijana oleh Syntho dinilai, disahkan dan diluluskan dari sudut luaran dan objektif oleh pakar data SAS.
Walaupun Syntho berbangga untuk menawarkan kepada penggunanya laporan jaminan kualiti lanjutan, kami juga memahami kepentingan mengadakan penilaian luaran dan objektif data sintetik kami daripada peneraju industri. Itulah sebabnya kami bekerjasama dengan SAS, peneraju dalam analitik, untuk menilai data sintetik kami.
SAS menjalankan pelbagai penilaian menyeluruh tentang ketepatan data, perlindungan privasi dan kebolehgunaan data sintetik yang dijana AI Syntho berbanding dengan data asal. Sebagai kesimpulan, SAS menilai dan meluluskan data sintetik Syntho sebagai tepat, selamat dan boleh digunakan berbanding dengan data asal.
Kami menggunakan data telekom yang digunakan untuk ramalan "churn" sebagai data sasaran. Matlamat penilaian adalah untuk menggunakan data sintetik untuk melatih pelbagai model ramalan churn dan untuk menilai prestasi setiap model. Memandangkan ramalan churn ialah tugas pengelasan, SAS memilih model klasifikasi popular untuk membuat ramalan, termasuk:
Sebelum menjana data sintetik, SAS membahagikan set data telekomunikasi secara rawak kepada set kereta api (untuk melatih model) dan set penahanan (untuk menskor model). Mempunyai set penahanan yang berasingan untuk pemarkahan membolehkan penilaian tidak berat sebelah tentang prestasi model pengelasan apabila digunakan pada data baharu.
Menggunakan set kereta api sebagai input, Syntho menggunakan Enjin Syntho untuk menjana set data sintetik. Untuk penanda aras, SAS juga mencipta versi tanpa nama bagi set kereta api selepas menggunakan pelbagai teknik anonim untuk mencapai ambang tertentu (k-tanpa nama). Langkah terdahulu menghasilkan empat set data:
Set data 1, 3 dan 4 digunakan untuk melatih setiap model klasifikasi, menghasilkan 12 (3 x 4) model terlatih. SAS kemudiannya menggunakan set data holdout untuk mengukur ketepatan setiap model dalam ramalan churn pelanggan.
SAS menjalankan pelbagai penilaian menyeluruh tentang ketepatan data, perlindungan privasi dan kebolehgunaan data sintetik yang dijana AI Syntho berbanding dengan data asal. Sebagai kesimpulan, SAS menilai dan meluluskan data sintetik Syntho sebagai tepat, selamat dan boleh digunakan berbanding dengan data asal.
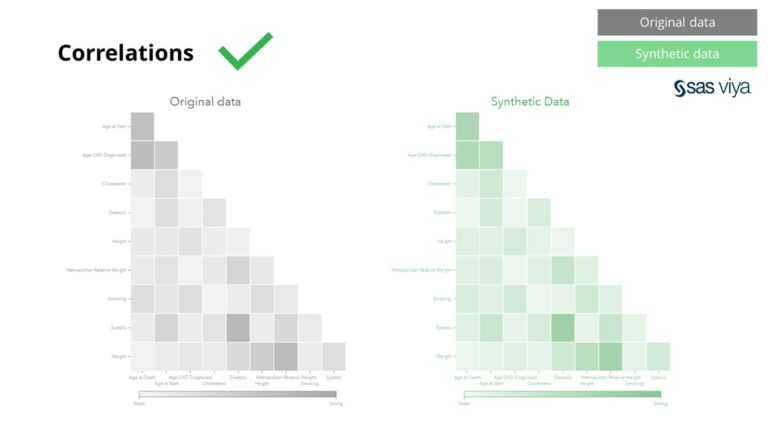
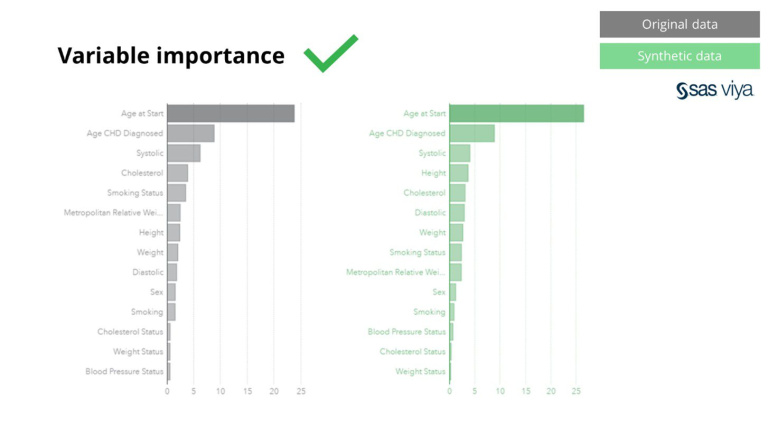
Data sintetik daripada Syntho bukan sahaja untuk corak asas, ia juga menangkap corak statistik 'tersembunyi' mendalam yang diperlukan untuk tugasan analitik lanjutan. Yang terakhir ditunjukkan dalam carta bar, menunjukkan bahawa ketepatan model yang dilatih pada data sintetik berbanding model yang dilatih pada data asal adalah serupa. Oleh itu, data sintetik boleh digunakan untuk latihan sebenar model. Input dan kepentingan pembolehubah yang dipilih oleh algoritma pada data sintetik berbanding dengan data asal adalah sangat serupa. Oleh itu, disimpulkan bahawa proses pemodelan boleh dilakukan pada data sintetik, sebagai alternatif untuk menggunakan data sensitif sebenar.
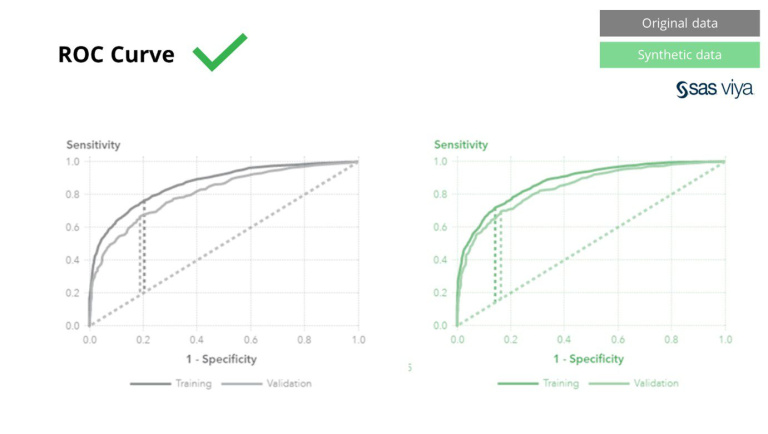
Teknik anonimasi klasik mempunyai persamaan iaitu ia memanipulasi data asal untuk menghalang pengesanan semula individu. Mereka memanipulasi data dan dengan itu memusnahkan data dalam proses. Lebih banyak anda tanpa nama, lebih baik data anda dilindungi, tetapi juga lebih banyak data anda dimusnahkan. Ini amat memusnahkan AI dan tugas pemodelan yang "kuasa ramalan" adalah penting, kerana data kualiti yang buruk akan menghasilkan cerapan yang tidak baik daripada model AI. SAS menunjukkan ini, dengan kawasan di bawah lengkung (AUC*) hampir 0.5, menunjukkan bahawa model yang dilatih pada data awanama menunjukkan prestasi yang paling teruk.
Korelasi dan hubungan antara pembolehubah dipelihara dengan tepat dalam data sintetik.
Kawasan Di Bawah Lengkung (AUC), metrik untuk mengukur prestasi model, kekal konsisten.
Tambahan pula, kepentingan pembolehubah, yang menunjukkan kuasa ramalan pembolehubah dalam model, kekal utuh apabila membandingkan data sintetik dengan set data asal.
Berdasarkan pemerhatian oleh SAS dan dengan menggunakan SAS Viya, kami dengan yakin boleh membuat kesimpulan bahawa data sintetik yang dihasilkan oleh Enjin Syntho sememangnya setanding dengan data sebenar dari segi kualiti. Ini mengesahkan penggunaan data sintetik untuk pembangunan model, membuka jalan untuk analisis lanjutan dengan data sintetik.
