Penyebab Ghaib AI: Membongkar Bias Dalam
Siri blog bias: bahagian 1
Pengenalan
Dalam dunia kita dengan bentuk kecerdasan yang semakin tiruan, mesin yang ditugaskan untuk membuat keputusan yang rumit semakin berleluasa. Terdapat semakin banyak literatur yang menunjukkan penggunaan AI dalam pelbagai domain seperti Perniagaan, membuat keputusan berkepentingan tinggi, dan sejak beberapa tahun lalu dalam sektor perubatan. Walau bagaimanapun, dengan kelaziman yang semakin meningkat ini, orang ramai menyedari tentang kecenderungan dalam sistem tersebut; Iaitu, walaupun secara semula jadi direka untuk mengikuti corak dalam data semata-mata, mereka telah menunjukkan tanda-tanda prasangka, dalam erti kata bahawa pelbagai tingkah laku seksis dan diskriminasi boleh diperhatikan. Yang terbaru Akta AI Eropah, juga merangkumi perkara prejudis sedemikian secara agak meluas dan menetapkan asas untuk menangani masalah yang berkaitan dengannya.
Sepanjang tahun dokumentasi teknikal, orang ramai cenderung menggunakan istilah "berat sebelah" untuk menerangkan jenis tingkah laku yang condong ini terhadap demografi tertentu; perkataan yang maknanya berbeza-beza, menyebabkan kekeliruan dan menyukarkan tugas menanganinya.
Artikel ini adalah yang pertama dalam siri catatan blog yang merangkumi topik berat sebelah. Dalam siri ini, kami akan menyasarkan untuk memberi anda pemahaman yang jelas dan mudah dihadam tentang berat sebelah dalam AI. Kami akan memperkenalkan cara untuk mengukur dan meminimumkan berat sebelah serta meneroka peranan data sintetik dalam laluan ini ke sistem yang lebih adil. Kami juga akan memberi anda gambaran tentang bagaimana Syntho, pemain terkemuka dalam penjanaan data sintetik, boleh menyumbang kepada usaha ini. Jadi, sama ada anda seorang pengamal yang mencari cerapan yang boleh diambil tindakan atau hanya ingin tahu tentang topik ini, anda berada di tempat yang betul.
Bias in Action: Contoh Dunia Nyata
Anda mungkin tertanya-tanya, "Kecondongan dalam AI ini semuanya penting, tetapi apakah maksudnya bagi saya, bagi orang biasa?" Sebenarnya, impaknya sangat luas, selalunya tidak kelihatan tetapi kuat. Bias dalam AI bukanlah konsep akademik semata-mata; ia adalah masalah dunia nyata dengan akibat yang serius.
Ambil contoh skandal kebajikan kanak-kanak Belanda. Sistem automatik, kononnya alat yang dicipta untuk menjana keputusan yang adil dan cekap dengan campur tangan manusia yang minimum, adalah berat sebelah. Ia secara salah menandakan beribu-ribu ibu bapa untuk penipuan berdasarkan data dan andaian yang salah. Keputusan? Keluarga dilemparkan ke dalam kegawatan, reputasi peribadi rosak dan kesukaran kewangan, semuanya disebabkan oleh berat sebelah dalam Sistem AI. Contoh seperti ini yang menyerlahkan keperluan untuk menangani berat sebelah dalam AI.

Sumber: “Compensatie ouders toeslagenaffaire kan zomaar tot 2030 duren”, 2023. AS
Tetapi jangan berhenti di situ sahaja. Insiden ini bukan kes terpencil yang membawa malapetaka. Kesan berat sebelah dalam AI meluas ke semua sudut kehidupan kita. Daripada siapa yang diambil bekerja, siapa yang diluluskan untuk pinjaman, kepada siapa yang menerima jenis rawatan perubatan - sistem AI yang berat sebelah boleh mengekalkan ketidaksamaan sedia ada dan mencipta yang baharu.
Pertimbangkan ini: sistem AI yang dilatih mengenai data sejarah yang berat sebelah boleh menafikan calon yang layak mendapat pekerjaan hanya kerana jantina atau etnik mereka. Atau sistem AI yang berat sebelah mungkin menolak pinjaman kepada calon yang layak kerana poskod mereka. Ini bukan hanya senario hipotesis; mereka sedang berlaku sekarang.
Jenis-jenis berat sebelah tertentu, seperti Bias Sejarah dan Bias Pengukuran, membawa kepada keputusan yang salah. Ia wujud dalam data, berakar umbi dalam berat sebelah masyarakat, dan dicerminkan dalam hasil yang tidak sama rata dalam kalangan kumpulan demografi yang berbeza. Mereka boleh memesongkan keputusan model ramalan dan mengakibatkan layanan yang tidak adil.
Dalam skema besar perkara, berat sebelah dalam AI boleh bertindak sebagai pengaruh senyap, secara halus membentuk masyarakat dan kehidupan kita, selalunya dalam cara yang tidak kita sedari. Semua perkara yang disebutkan di atas ini mungkin membawa anda untuk mempersoalkan mengapa tindakan tidak diambil untuk menghentikannya, dan sama ada ia mungkin.
Sememangnya, dengan kemajuan teknologi baharu ia menjadi semakin mudah untuk menangani masalah tersebut. Walau bagaimanapun, langkah pertama untuk menangani masalah ini ialah memahami dan mengakui kewujudan dan kesannya. Buat masa ini, pengakuan kewujudannya telah diwujudkan, menjadikan perkara "pemahaman" masih agak kabur.
Memahami Bias
Manakala definisi asal bias seperti yang dikemukakan oleh Kamus Cambridge tidak tersasar terlalu jauh dari tujuan utama perkataan kerana ia berkaitan dengan AI, banyak tafsiran berbeza perlu dibuat walaupun definisi tunggal ini. Taksonomi, seperti yang dikemukakan oleh penyelidik seperti Hellström et al (2020) and Kliegr (2021), memberikan pandangan yang lebih mendalam tentang definisi berat sebelah. Sepintas lalu pada kertas kerja ini akan mendedahkan, bagaimanapun, bahawa penyempitan besar definisi istilah diperlukan untuk menangani masalah dengan berkesan.
Walaupun menjadi perubahan peristiwa, untuk mentakrifkan dan menyampaikan maksud berat sebelah secara optimum, seseorang boleh mentakrifkan sebaliknya, iaitu Keadilan.
Mendefinisikan Keadilan
Seperti yang ditakrifkan dalam pelbagai literatur terkini seperti Castelnovo et al. (2022), keadilan boleh dihuraikan apabila diberi pemahaman tentang istilah ruang berpotensi. Seperti yang wujud, ruang potensi (PS) merujuk kepada sejauh mana keupayaan dan pengetahuan seseorang individu tanpa mengira kepunyaan mereka dalam kumpulan demografi tertentu. Memandangkan takrifan konsep PS ini, seseorang boleh dengan mudah mentakrifkan keadilan sebagai kesamarataan layanan antara dua individu yang mempunyai PS yang sama, tanpa mengira perbezaan yang boleh diperhatikan dan tersembunyi dalam parameter mendorong berat sebelah (seperti bangsa, umur atau jantina). Sebarang lencongan daripada takrifan ini, yang juga dikenali sebagai Kesaksamaan Peluang, merupakan petunjuk jelas tentang berat sebelah dan patut disiasat lebih lanjut.
Pengamal di kalangan pembaca mungkin menyedari bahawa mencapai sesuatu seperti yang ditakrifkan di sini mungkin mustahil sepenuhnya memandangkan kecenderungan yang wujud di dunia kita. Itu benar! Dunia yang kita diami, bersama-sama dengan semua data yang dikumpul daripada kejadian di dunia ini, tertakluk kepada banyak bias sejarah dan statistik. Ini, sememangnya, mengurangkan keyakinan suatu hari nanti mengurangkan sepenuhnya kesan berat sebelah pada model ramalan yang dilatih pada data "berat sebelah" sedemikian. Walau bagaimanapun, melalui penggunaan pelbagai kaedah, seseorang boleh cuba meminimumkan kesan berat sebelah. Dalam keadaan ini, terminologi yang digunakan dalam catatan blog yang lain ini akan beralih ke arah idea untuk meminimumkan kesan berat sebelah dan bukannya mengurangkannya sepenuhnya.
Baik! Jadi sekarang bahawa idea telah dikemukakan tentang apa itu berat sebelah dan bagaimana seseorang berpotensi menilai kewujudannya; Walau bagaimanapun, jika kita ingin menangani masalah itu dengan betul, kita perlu tahu dari mana semua bias ini berasal.
Memahami Sumber dan jenis
Penyelidikan sedia ada memberikan cerapan berharga tentang pelbagai jenis berat sebelah dalam pembelajaran mesin. Sebagai Mehrabi et. al. (2019) telah meneruskan untuk membahagikan bias dalam pembelajaran mesin, seseorang boleh membahagikan bias kepada 3 kategori utama. Iaitu mereka dari:
- Data kepada Algoritma: kategori yang merangkumi berat sebelah yang berasal daripada data itu sendiri. Mungkin itu disebabkan oleh pengumpulan data yang lemah, kecenderungan yang wujud di dunia, dsb.
- Algoritma kepada Pengguna: kategori yang memfokuskan pada berat sebelah yang berpunca daripada reka bentuk dan kefungsian algoritma. Ia termasuk cara algoritma mungkin mentafsir, menimbang atau mempertimbangkan titik data tertentu berbanding yang lain, yang boleh membawa kepada hasil yang berat sebelah.
- Pengguna kepada Data: berkaitan dengan berat sebelah yang timbul daripada interaksi pengguna dengan sistem. Cara pengguna memasukkan data, berat sebelah yang wujud, atau kepercayaan mereka terhadap output sistem boleh mempengaruhi hasil.
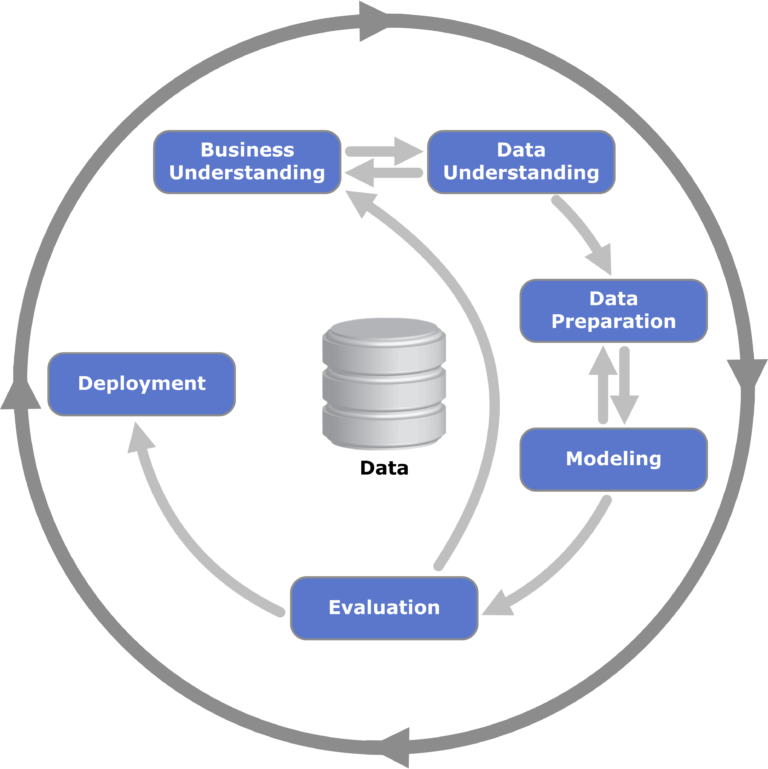
Rajah 1: Visualisasi rangka kerja CRISP-DM untuk perlombongan data; biasa digunakan dalam perlombongan data dan berkaitan dengan proses mengenal pasti peringkat di mana kecenderungan boleh wujud.
Walaupun nama-nama itu menunjukkan bentuk berat sebelah, seseorang mungkin masih mempunyai soalan tentang jenis berat sebelah yang mungkin dikategorikan di bawah istilah payung ini. Untuk peminat di kalangan pembaca kami, kami telah menyediakan pautan kepada beberapa literatur yang berkaitan dengan istilah dan klasifikasi ini. Demi kesederhanaan dalam catatan blog ini, kami akan merangkumi beberapa bias terpilih yang berkaitan dengan situasi (Hampir kesemuanya adalah data kategori kepada algoritma). Jenis berat sebelah khusus adalah seperti berikut:
- Bias Sejarah: Jenis bias yang wujud pada data yang disebabkan oleh berat sebelah semula jadi yang wujud di dunia dalam kumpulan sosial dan masyarakat yang berbeza secara amnya. Ia adalah kerana sifat asli data ini di dunia bahawa ia tidak boleh dikurangkan melalui pelbagai cara persampelan dan pemilihan ciri.
- Bias Pengukuran & Bias Perwakilan: Kedua-dua berat sebelah yang berkait rapat ini berlaku apabila subkumpulan berbeza set data mengandungi jumlah hasil yang "menguntungkan" yang tidak sama rata. Oleh itu, bias jenis ini boleh memesongkan hasil model ramalan
- Bias Algoritma: Bias semata-mata berkaitan dengan algoritma yang digunakan. Seperti yang juga diperhatikan dalam ujian yang dijalankan (dihuraikan lebih lanjut dalam siaran), jenis berat sebelah ini boleh memberi kesan yang besar pada kewajaran algoritma tertentu.
Pemahaman asas tentang berat sebelah dalam pembelajaran mesin ini akan digunakan untuk menangani masalah dengan lebih berkesan dalam siaran kemudian.
Pemikiran Akhir
Dalam penerokaan berat sebelah dalam kecerdasan buatan ini, kami telah menerangkan implikasi mendalam yang ada dalam dunia kami yang semakin dipacu AI. Daripada contoh dunia sebenar seperti skandal kebajikan kanak-kanak Belanda kepada nuansa rumit kategori dan jenis berat sebelah, adalah jelas bahawa mengiktiraf dan memahami berat sebelah adalah yang paling penting.
Walaupun cabaran yang ditimbulkan oleh berat sebelah — sama ada ia adalah sejarah, algoritma atau disebabkan oleh pengguna — adalah penting, ia tidak boleh diatasi. Dengan pemahaman yang kukuh tentang asal-usul dan manifestasi berat sebelah, kami lebih bersedia untuk menanganinya. Walau bagaimanapun, pengiktirafan dan pemahaman hanyalah titik permulaan.
Semasa kami bergerak ke hadapan dalam siri ini, tumpuan kami seterusnya adalah pada alat dan rangka kerja yang nyata yang kami gunakan. Bagaimanakah kita mengukur tahap berat sebelah dalam model AI? Dan yang lebih penting, bagaimana kita meminimumkan kesannya? Ini adalah soalan mendesak yang akan kami teliti seterusnya, memastikan bahawa semasa AI terus berkembang, ia melakukannya ke arah yang adil dan berprestasi.

Data adalah sintetik, tetapi pasukan kami adalah sebenar!
Hubungi Syntho dan salah seorang pakar kami akan menghubungi anda dengan kelajuan cahaya untuk meneroka nilai data sintetik!