Data Sintetik yang dijana AI, akses mudah dan pantas kepada data berkualiti tinggi?
AI menjana data sintetik dalam amalan
Syntho, pakar dalam data sintetik yang dijana AI, bertujuan untuk mengubahnya privacy by design menjadi kelebihan daya saing dengan data sintetik yang dijana AI. Mereka membantu organisasi membina asas data yang kukuh dengan akses mudah dan pantas kepada data berkualiti tinggi dan baru-baru ini memenangi Anugerah Inovasi Philips.
Walau bagaimanapun, penjanaan data sintetik dengan AI ialah penyelesaian yang agak baharu yang biasanya memperkenalkan soalan lazim. Untuk menjawabnya, Syntho memulakan kajian kes bersama SAS, peneraju pasaran dalam Analitis Lanjutan dan perisian AI.
Dengan kerjasama Dutch AI Coalition (NL AIC), mereka menyiasat nilai data sintetik dengan membandingkan data sintetik jana AI yang dijana oleh Enjin Syntho dengan data asal melalui pelbagai penilaian tentang kualiti data, kesahihan undang-undang dan kebolehgunaan.
Adakah penganamaan data bukan penyelesaian?
Teknik anonimasi klasik mempunyai persamaan iaitu ia memanipulasi data asal untuk menghalang pengesanan semula individu. Contohnya ialah generalisasi, penindasan, mengelap, nama samaran, menyembunyikan data dan mengocok baris & lajur. Anda boleh mendapatkan contoh dalam jadual di bawah.
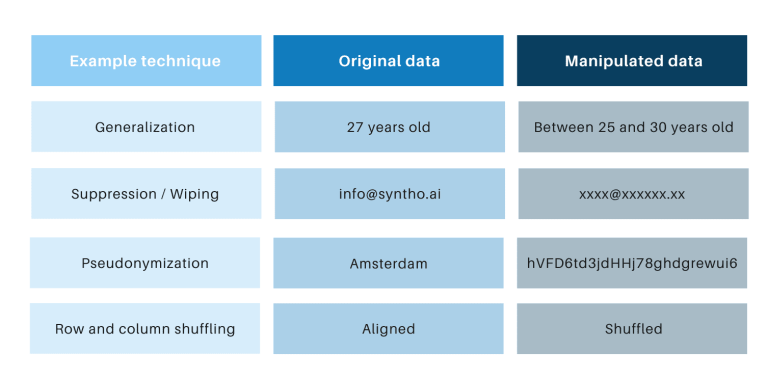
Teknik tersebut memperkenalkan 3 cabaran utama:
- Ia berfungsi secara berbeza mengikut jenis data dan setiap set data, menjadikannya sukar untuk skala. Tambahan pula, kerana ia berfungsi secara berbeza, akan sentiasa ada perdebatan tentang kaedah yang mana untuk digunakan dan gabungan teknik yang diperlukan.
- Sentiasa ada hubungan satu dengan satu dengan data asal. Ini bermakna bahawa risiko privasi akan sentiasa ada, terutamanya disebabkan oleh semua set data terbuka dan teknik yang tersedia untuk memautkan set data tersebut.
- Mereka memanipulasi data dan dengan itu memusnahkan data dalam proses. Ini amat memusnahkan tugas AI yang "kuasa ramalan" adalah penting, kerana data kualiti yang tidak baik akan menghasilkan cerapan yang tidak baik daripada model AI (Masuk sampah akan mengakibatkan pembuangan sampah).
Perkara ini juga dinilai melalui kajian kes ini.
Pengenalan kepada kajian kes
Untuk kajian kes, set data sasaran ialah set data telekom yang disediakan oleh SAS yang mengandungi data 56.600 pelanggan. Set data mengandungi 128 lajur, termasuk satu lajur yang menunjukkan sama ada pelanggan telah meninggalkan syarikat (iaitu 'tergelincir') atau tidak. Matlamat kajian kes adalah untuk menggunakan data sintetik untuk melatih beberapa model untuk meramalkan churn pelanggan dan untuk menilai prestasi model terlatih tersebut. Memandangkan ramalan churn ialah tugas pengelasan, SAS memilih empat model klasifikasi popular untuk membuat ramalan, termasuk:
- Hutan rawak
- Peningkatan kecerunan
- Regresi logistik
- Rangkaian neural
Sebelum menjana data sintetik, SAS membahagikan set data telekomunikasi secara rawak kepada set kereta api (untuk melatih model) dan set penahanan (untuk menskor model). Mempunyai set penahanan yang berasingan untuk pemarkahan membolehkan penilaian tidak berat sebelah tentang prestasi model klasifikasi apabila digunakan pada data baharu.
Menggunakan set kereta api sebagai input, Syntho menggunakan Enjin Syntho untuk menjana set data sintetik. Untuk penandaarasan, SAS juga mencipta versi set kereta api yang dimanipulasi selepas menggunakan pelbagai teknik anonimiti untuk mencapai ambang tertentu (k-anonimity). Langkah terdahulu menghasilkan empat set data:
- Set data kereta api (iaitu set data asal tolak set data tahan)
- Set data tertahan (iaitu subset set data asal)
- Set data awanama (berdasarkan set data kereta api)
- Set data sintetik (berdasarkan set data kereta api)
Set data 1, 3 dan 4 digunakan untuk melatih setiap model pengelasan, menghasilkan 12 (3 x 4) model terlatih. SAS kemudiannya menggunakan set data penahanan untuk mengukur ketepatan setiap model meramalkan perpindahan pelanggan. Hasilnya dibentangkan di bawah, bermula dengan beberapa statistik asas.
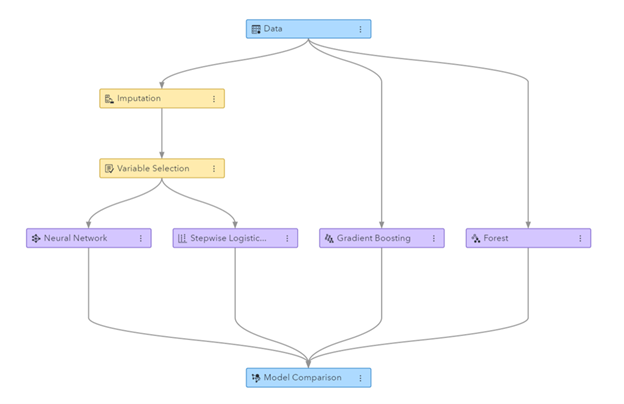
Rajah: Saluran paip Pembelajaran Mesin yang dijana dalam Perlombongan Data Visual SAS dan Pembelajaran Mesin
Statistik asas apabila membandingkan data tanpa nama dengan data asal
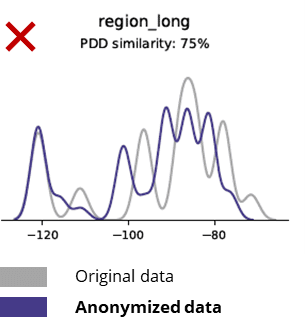
Teknik anonimasi memusnahkan walaupun corak asas, logik perniagaan, perhubungan dan statistik (seperti dalam contoh di bawah). Menggunakan data tanpa nama untuk analisis asas dengan itu menghasilkan hasil yang tidak boleh dipercayai. Malah, kualiti data tanpa nama yang lemah menjadikan hampir mustahil untuk menggunakannya untuk tugasan analitis lanjutan (cth pemodelan dan papan pemuka AI/ML).
Statistik asas apabila membandingkan data sintetik dengan data asal
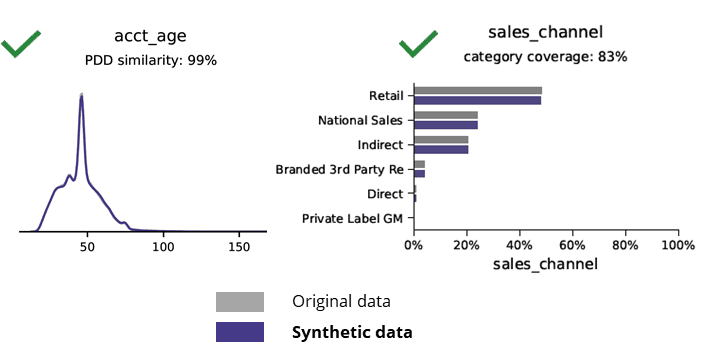
Penjanaan data sintetik dengan AI mengekalkan corak asas, logik perniagaan, perhubungan dan statistik (seperti dalam contoh di bawah). Menggunakan data sintetik untuk analisis asas dengan itu menghasilkan hasil yang boleh dipercayai. Soalan utama, adakah data sintetik sesuai untuk tugasan analitik lanjutan (cth pemodelan AI/ML dan papan pemuka)?
Data sintetik yang dijana AI dan analisis lanjutan
Data sintetik bukan sahaja disimpan untuk corak asas (seperti yang ditunjukkan dalam plot sebelumnya), ia juga menangkap corak statistik 'tersembunyi' yang mendalam yang diperlukan untuk tugasan analitik lanjutan. Yang terakhir ditunjukkan dalam carta bar di bawah, menunjukkan bahawa ketepatan model yang dilatih pada data sintetik berbanding model yang dilatih pada data asal adalah serupa. Tambahan pula, dengan kawasan di bawah lengkung (AUC*) hampir 0.5, model yang dilatih pada data awanama menunjukkan prestasi yang paling teruk. Laporan penuh dengan semua penilaian analitik lanjutan pada data sintetik berbanding dengan data asal tersedia atas permintaan.
*AUC: kawasan di bawah lengkung ialah ukuran untuk ketepatan model analitik lanjutan, dengan mengambil kira positif benar, positif palsu, negatif palsu dan negatif benar. 0,5 bermakna model meramal secara rawak dan tidak mempunyai kuasa ramalan dan 1 bermakna model sentiasa betul dan mempunyai kuasa ramalan penuh.
Selain itu, data sintetik ini boleh digunakan untuk memahami ciri data dan pembolehubah utama yang diperlukan untuk latihan sebenar model. Input yang dipilih oleh algoritma pada data sintetik berbanding dengan data asal adalah sangat serupa. Oleh itu, proses pemodelan boleh dilakukan pada versi sintetik ini, yang mengurangkan risiko pelanggaran data. Walau bagaimanapun, apabila membuat inferensi rekod individu (cth. pelanggan telco) latihan semula pada data asal disyorkan untuk kebolehjelasan, peningkatan penerimaan atau hanya kerana peraturan.
AUC mengikut Algoritma dikumpulkan mengikut Kaedah
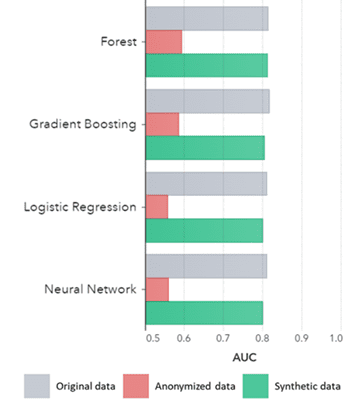
Kesimpulan:
- Model yang dilatih pada data sintetik berbanding dengan model yang dilatih pada data asal menunjukkan prestasi yang sangat serupa
- Model yang dilatih pada data awanama dengan 'teknik anonimasi klasik' menunjukkan prestasi yang lebih rendah berbanding model yang dilatih pada data asal atau data sintetik
- Penjanaan data sintetik adalah mudah dan pantas kerana teknik ini berfungsi sama persis setiap set data dan setiap jenis data.
Kes penggunaan data sintetik nilai tambah
Kes penggunaan 1: Data sintetik untuk pembangunan model dan analitis lanjutan
Mempunyai asas data yang kukuh dengan akses mudah dan pantas kepada data yang boleh digunakan dan berkualiti tinggi adalah penting untuk membangunkan model (cth papan pemuka [BI] dan analitik lanjutan [AI & ML]). Walau bagaimanapun, banyak organisasi mengalami asas data yang tidak optimum yang mengakibatkan 3 cabaran utama:
- Mendapatkan akses ke data memerlukan masa yang lama kerana peraturan (privasi), proses dalaman atau silo data
- Teknik anonimasi klasik memusnahkan data, menjadikan data tidak lagi sesuai untuk analisis dan analitik lanjutan (sampah masuk = sampah keluar)
- Penyelesaian sedia ada tidak boleh berskala kerana ia berfungsi secara berbeza bagi setiap set data dan setiap jenis data serta tidak boleh mengendalikan pangkalan data berbilang jadual yang besar
Pendekatan data sintetik: membangunkan model dengan data sintetik yang baik-sebagai-sebenar untuk:
- Minimumkan penggunaan data asal, tanpa menghalang pembangun anda
- Buka kunci data peribadi dan dapatkan akses ke lebih banyak data yang sebelumnya dibatasi (contohnya kerana privasi)
- Akses data yang mudah dan pantas ke data yang berkaitan
- Penyelesaian berskala yang berfungsi sama untuk setiap set data, jenis data dan untuk pangkalan data yang besar
Ini membolehkan organisasi membina asas data yang kukuh dengan akses mudah dan pantas kepada data berkualiti tinggi yang boleh digunakan untuk membuka kunci data dan memanfaatkan peluang data.
Kes penggunaan 2: data ujian sintetik pintar untuk ujian perisian, pembangunan dan penghantaran
Pengujian dan pembangunan dengan data ujian berkualiti tinggi adalah penting untuk menyampaikan penyelesaian perisian terkini. Menggunakan data pengeluaran asal nampaknya jelas, tetapi tidak dibenarkan kerana peraturan (privasi). Alternatif Test Data Management (TDM) memperkenalkan “legacy-by-design” dalam mendapatkan data ujian dengan betul:
- Jangan mencerminkan data pengeluaran dan logik perniagaan dan integriti rujukan tidak dipelihara
- Kerja perlahan dan memakan masa
- Kerja manual diperlukan
Pendekatan data sintetik: Uji dan bangunkan dengan data ujian sintetik yang dijana AI untuk menyampaikan penyelesaian perisian terkini yang pintar dengan:
- Data seperti pengeluaran dengan logik perniagaan yang dipelihara dan integriti rujukan
- Penjanaan data yang mudah dan pantas dengan AI canggih
- Privasi mengikut reka bentuk
- Mudah, cepat dan agile
Ini membolehkan organisasi menguji dan membangun dengan data ujian peringkat seterusnya untuk menyampaikan penyelesaian perisian terkini!
Maklumat lanjut
Berminat? Untuk maklumat lanjut tentang data sintetik, lawati tapak web Syntho atau hubungi Wim Kees Janssen. Untuk maklumat lanjut tentang SAS, lawati www.sas.com atau hubungi kees@syntho.ai.
Dalam kes penggunaan ini, Syntho, SAS dan NL AIC bekerjasama untuk mencapai hasil yang diinginkan. Syntho ialah pakar dalam data sintetik yang dijana AI dan SAS ialah peneraju pasaran dalam analisis dan menawarkan perisian untuk meneroka, menganalisis dan menggambarkan data.
* Ramal 2021 – Strategi Data dan Analitis untuk Mentadbir, Menskala dan Mengubah Perniagaan Digital, Gartner, 2020.

Simpan panduan data sintetik anda sekarang!
- Apa itu data sintetik?
- Mengapa organisasi menggunakannya?
- Kes pelanggan data sintetik menambah nilai
- Cara bermula
