Синтетички податоци за пад на курсот
Дознај повеќе
контактирајте не
Вовед
Што се синтетички податоци?
Одговорот е релативно едноставен. Додека оригиналните податоци се собираат во сите ваши интеракции со вистински лица (на пр. клиенти, пациенти, вработени итн.) и преку сите ваши внатрешни процеси, синтетичките податоци се генерираат со компјутерски алгоритам. Овој компјутерски алгоритам генерира целосно нови и вештачки точки на податоци.
Решете ги предизвиците за приватност на податоците
Синтетички генерираните податоци се состојат од сосема нови и вештачки точки на податоци без врски еден на еден со оригиналните податоци. Оттука, ниту една од синтетичките точки на податоци не може да се следи наназад или обратно инженеринг до оригиналните податоци. Како резултат на тоа, синтетичките податоци се изземени од прописите за приватност, како што е GDPR и служат како решение за решавање и надминување на предизвиците за приватност на податоците.
Зголемете и симулирајте
Генеративниот аспект на генерирање на синтетички податоци овозможува да се зголемат и симулираат целосно нови податоци. Ова функционира како решение кога немате доволно податоци (недостаток на податоци), би сакале да ги зголемите примероците на рабовите или кога сè уште немате податоци.
Тука, фокусот на Syntho е структуирани податоци (податоци форматирани во табели што содржат редови и колони, како што гледате во листовите на Excel), но ние секогаш сакаме да го илустрираме концептот на синтетички податоци преку слики, бидејќи е попривлечен.
Видови синтетички податоци
Постојат три типа на синтетички податоци во чадорот за синтетички податоци. Тие 3 типа на синтетички податоци се: лажни податоци, генерирани синтетички податоци засновани на правила и синтетички податоци генерирани од вештачка интелигенција (ВИ). Накратко објаснуваме кои се 3-те различни типови на синтетички податоци.
Лажни податоци / лажни податоци
Лажни податоци се случајно генерирани податоци (на пр. од лажен генератор на податоци).
Следствено, карактеристиките, врските и статистичките обрасци кои се во оригиналните податоци не се зачувани, заробени и репродуцирани во генерираните лажни податоци. Оттука, репрезентативноста на лажни податоци / лажни податоци е минимална во споредба со оригиналните податоци.
- Кога да го користите: да ги замените директните идентификатори (PII) или кога немате податоци (сè уште) и не сакате да трошите време и енергија на дефинирање правила.
Генерирани синтетички податоци базирани на правила
Синтетички податоци генерирани врз основа на правила се синтетички податоци генерирани од претходно дефиниран сет на правила. Примери за тие однапред дефинирани правила би можеле да бидат дека би сакале да имате синтетички податоци со одредена минимална вредност, максимална вредност или просечна вредност. Секоја од карактеристиките, врските и статистичките обрасци што би сакале да ги репродуцирате во синтетичките генерирани базирани на правила, треба да бидат однапред дефинирани.
Следствено, квалитетот на податоците ќе биде подеднакво добар како и претходно дефинираниот сет на правила. Ова резултира со предизвици кога високиот квалитет на податоците е од суштинско значење. Прво, може да се дефинира само ограничен сет на правила што треба да се зафатат во синтетичките податоци. Дополнително, поставувањето повеќе правила обично ќе резултира со преклопување и конфликтни правила. Покрај тоа, никогаш нема целосно да ги покриете сите релевантни правила. Понатаму, може да има релевантни правила за кои не сте ни свесни. И конечно (и да не заборавиме), ова ќе ви одземе многу време и енергија што ќе резултира со неефикасно решение.
- Кога да го користите: кога немате податоци (сè уште)
Синтетички податоци генерирани од вештачка интелигенција (ВИ)
Како што очекувате од името, синтетичките податоци генерирани од вештачката интелигенција (AI) се синтетички податоци генерирани од алгоритам за вештачка интелигенција (AI). Моделот на вештачка интелигенција е обучен на оригиналните податоци за да ги научи сите карактеристики, врски и статистички обрасци. Потоа, овој алгоритам за вештачка интелигенција може да генерира целосно нови податочни точки и да ги моделира тие нови точки на податоци на таков начин што ги репродуцира карактеристиките, врските и статистичките обрасци од оригиналната база на податоци. Ова е она што ние го нарекуваме синтетички близнак на податоци.
Моделот со вештачка интелигенција имитира оригинални податоци за да генерира синтетички близнаци на податоци што може да се користат како да се оригинални податоци. Ова отклучува различни случаи на употреба каде синтетичките податоци генерирани со вештачка интелигенција може да се користат како алтернатива за користење на оригинални (чувствителни) податоци, како што е употребата на синтетички податоци генерирани со вештачка интелигенција како податоци за тестирање, демо податоци или за аналитика.
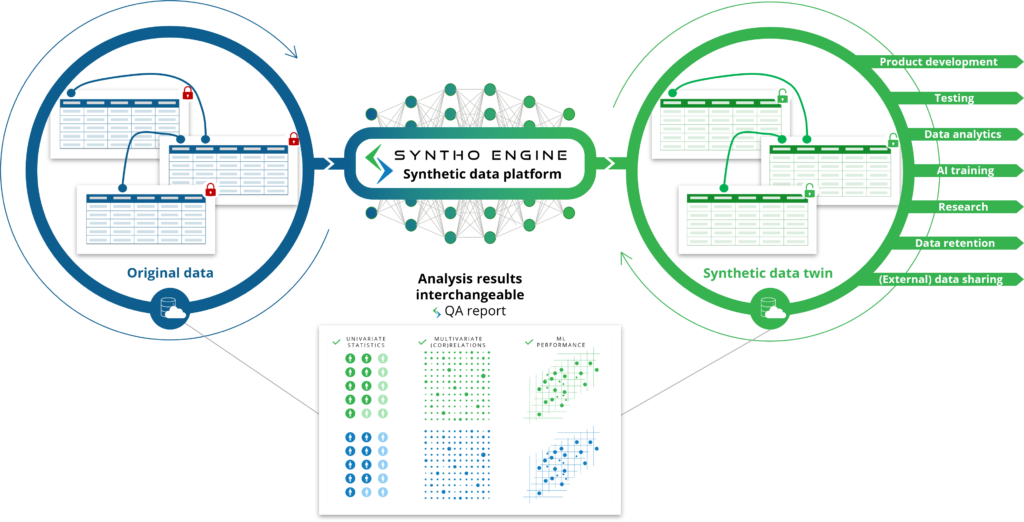
Во споредба со генерираните синтетички податоци засновани на правила: наместо вие да ги проучувате и дефинирате релевантните правила, алгоритмот за вештачка интелигенција го прави тоа автоматски за вас. Овде нема да бидат опфатени само карактеристиките, врските и статистичките обрасци за кои сте свесни, туку ќе бидат опфатени и карактеристиките, врските и статистичките обрасци за кои не сте ни свесни.
- Кога да го користите: кога имате (некои) податоци како влез за имитирање или користење како почетна точка за паметно генерирање податоци и функции за зголемување
Каков тип на синтетички податоци да се користат?
Во зависност од вашиот случај на употреба, се советува комбинација од лажни податоци / лажни податоци, генерирани синтетички податоци засновани на правила или синтетички податоци генерирани од вештачка интелигенција (ВИ). Овој преглед ви дава прва индикација за тоа кој тип на синтетички податоци да ги користите. Бидејќи Syntho ги поддржува сите нив, слободно контактирајте со нашите експерти за да нурнете длабоко кај нас.


