


Deidentifikacija je postopek, ki se uporablja za zaščito občutljivih informacij z odstranitvijo ali spreminjanjem osebno določljivih podatkov (PII) iz nabora podatkov ali zbirke podatkov.
Številne organizacije ravnajo z občutljivimi informacijami in zato potrebujejo zaščito. Cilj je povečati zasebnost in zmanjšati tveganje neposredne ali posredne identifikacije posameznikov. Deidentifikacija se pogosto uporablja v scenarijih, ki zahtevajo uporabo podatkov, na primer za namene testiranja in razvoja, s poudarkom na ohranjanju zasebnosti in upoštevanju predpisov o varstvu podatkov.
Syntho uporablja moč umetne inteligence, da vam omogoči de-identificiranje pametnega! V našem pristopu deidentifikacije uporabljamo pametne rešitve na treh temeljnih elementih. Prvič, prednost ima učinkovitost z uporabo našega skenerja osebnih podatkov, kar prihrani čas in zmanjša ročni napor. Drugič, zagotovimo, da se referenčna celovitost ohrani z uporabo doslednega preslikave. Nazadnje je prilagodljivost dosežena z uporabo naših mockerjev.
Zmanjšajte ročno delo in uporabite naše Skener PII za prepoznavanje stolpcev v vaši zbirki podatkov, ki vsebujejo neposredne podatke, ki omogočajo osebno identifikacijo (PII), z močjo umetne inteligence.
Zamenjajte občutljive PII, PHI in druge identifikatorje z reprezentativnimi Sintetični lažni podatki ki sledijo poslovni logiki in vzorcem.
Ohranite referenčno celovitost z dosledno preslikavo v celotnem podatkovnem ekosistemu za ujemanje podatkov v sintetičnih podatkovnih opravilih, bazah podatkov in sistemih.
Deidentifikacija pomeni spremembo ali odstranitev osebno določljivih podatkov (PII) iz obstoječih naborov podatkov in/ali zbirk podatkov. Še posebej je učinkovit za primere uporabe, ki vključujejo več relacijskih tabel, baz podatkov in/ali sistemov, in se običajno uporablja v primerih uporabe testnih podatkov.
Testni podatki za neprodukcijska okolja
Dostavite in objavite najsodobnejše programske rešitve hitreje in bolj kakovostno z reprezentativnimi testnimi podatki.
Predstavitveni podatki
Presenetite svoje potencialne stranke s predstavitvami izdelkov naslednje stopnje, prilagojenimi z reprezentativnimi podatki.
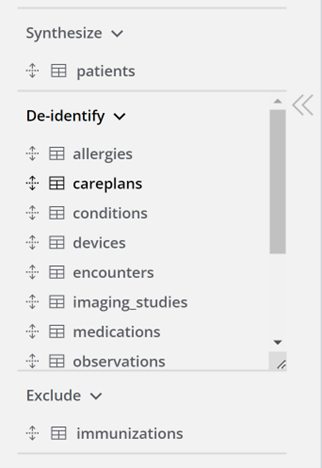
Brez težav konfigurirajte deidentifikacijo znotraj naše platforme z uporabniku prijaznimi možnostmi, prilagojenimi vašim potrebam. Ne glede na to, ali se osredotočate na celotne tabele ali določene stolpce v njih, naša platforma zagotavlja brezhibne konfiguracijske zmogljivosti.
Za deidentificiranje na ravni tabele preprosto povlecite tabele iz vaše relacijske baze podatkov v razdelek za deidentificiranje v delovnem prostoru.
Za deidentificiranje na ravni baze podatkov preprosto povlecite tabele iz svoje relacijske baze podatkov v razdelek za deidentificiranje v delovnem prostoru.
Če želite deidentifikacijo uporabiti na bolj razdrobljeni ravni ali ravni stolpca, odprite tabelo, izberite določen stolpec, ki ga želite deidentificirati, in brez truda uporabite mocker. Poenostavite svoj postopek varovanja podatkov z našimi intuitivnimi konfiguracijskimi funkcijami.
