AI ٺاهيل مصنوعي ڊيٽا، اعلي معيار جي ڊيٽا تائين آسان ۽ تيز رسائي؟
AI ٺاهيل مصنوعي ڊيٽا عملي طور تي
Syntho، AI-generated synthetic data ۾ هڪ ماهر، جو مقصد ڦرڻ آهي privacy by design AI ٺاهيل مصنوعي ڊيٽا سان مقابلي واري فائدي ۾. اهي تنظيمن جي مدد ڪن ٿا مضبوط ڊيٽا فائونڊيشن ٺاهڻ ۾ آسان ۽ تيز پهچ سان گڏ اعليٰ معيار جي ڊيٽا تائين ۽ تازو ئي فلپس انوويشن اوارڊ کٽيو آهي.
بهرحال، مصنوعي ڊيٽا جي پيداوار AI سان گڏ هڪ نسبتا نئين حل آهي جيڪو عام طور تي متعارف ڪرايو ويندو آهي اڪثر پڇيا ويا سوال. انهن جو جواب ڏيڻ لاءِ، Syntho SAS سان گڏجي هڪ ڪيس-مطالعو شروع ڪيو، Advanced Analytics ۽ AI سافٽ ويئر ۾ مارڪيٽ ليڊر.
ڊچ AI ڪوئليشن (NL AIC) جي تعاون سان، ھنن مصنوعي ڊيٽا جي قدر جي تحقيق ڪئي سنٿيو انجڻ پاران ٺاھيل AI-جنريٽ ٿيل مصنوعي ڊيٽا کي اصل ڊيٽا سان ڊيٽا جي معيار، قانوني صحيحيت ۽ استعمال جي مختلف جائزي ذريعي.
ڇا ڊيٽا گمنام ڪرڻ هڪ حل ناهي؟
ڪلاسيڪل گمنامي ٽيڪنڪ ۾ عام آهي ته اهي اصل ڊيٽا کي هٿي وٺن ٿا ته جيئن ماڻهن کي واپس ڪرڻ ۾ رڪاوٽ وجهن. مثال آهن عام ڪرڻ، دٻائڻ، وائپنگ، تخلص، ڊيٽا ماسڪنگ، ۽ قطارن ۽ ڪالمن جي شفلنگ. توھان ھيٺ ڏنل جدول ۾ مثال ڳولي سگھو ٿا.
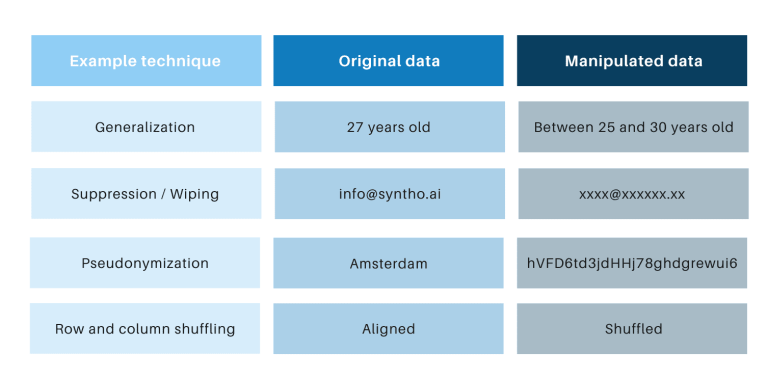
اهي ٽيڪنڪ متعارف ڪرايو 3 اهم چئلينج:
- اهي مختلف طريقي سان ڪم ڪن ٿا في ڊيٽا جي قسم ۽ في ڊيٽا سيٽ، انهن کي پيماني تي ڏکيو بڻائي ٿو. ان کان علاوه، ڇاڪاڻ ته اهي مختلف طريقي سان ڪم ڪن ٿا، اتي هميشه بحث ڪيو ويندو ته ڪهڙن طريقن کي لاڳو ڪرڻ ۽ ٽيڪنالاجي جي ڪهڙي ميلاپ جي ضرورت آهي.
- اصل ڊيٽا سان هميشه هڪ کان هڪ تعلق آهي. هن جو مطلب اهو آهي ته اتي هميشه هڪ رازداري خطرو هوندو، خاص طور تي سڀني کليل ڊيٽا سيٽ ۽ دستياب ٽيڪنالاجي جي ڪري انهن ڊيٽا سيٽن کي ڳنڍڻ لاء.
- اهي ڊيٽا کي هٿي وٺن ٿا ۽ انهي طريقي سان عمل ۾ ڊيٽا کي تباهه ڪن ٿا. اهو خاص طور تي AI ڪمن لاءِ تباهه ڪندڙ آهي جتي ”پيش گوئي ڪرڻ واري طاقت“ ضروري آهي، ڇاڪاڻ ته خراب معيار جي ڊيٽا جي نتيجي ۾ AI ماڊل کان خراب بصيرت پيدا ٿيندي (گاربيج-ان جي نتيجي ۾ گندگي ٻاهر نڪرندي).
انهن نقطن جو پڻ جائزو ورتو ويو آهي هن ڪيس جي مطالعي ذريعي.
ڪيس جي مطالعي جو هڪ تعارف
ڪيس جي مطالعي لاءِ، ٽارگيٽ ڊيٽا سيٽ SAS پاران مهيا ڪيل هڪ ٽيليڪ ڊيٽا سيٽ هو جنهن ۾ 56.600 گراهڪن جي ڊيٽا شامل هئي. ڊيٽا سيٽ 128 ڪالمن تي مشتمل آهي، جنهن ۾ هڪ ڪالم اهو ظاهر ڪري ٿو ته ڇا هڪ گراهڪ ڪمپني ڇڏي آهي (يعني 'چريو') يا نه. ڪيس جي مطالعي جو مقصد ڪجهه ماڊلز کي تربيت ڏيڻ لاءِ مصنوعي ڊيٽا استعمال ڪرڻ هو ته گراهڪ جي چرن جي اڳڪٿي ڪرڻ ۽ انهن تربيت يافته ماڊل جي ڪارڪردگي جو جائزو وٺڻ. جيئن ته چرن جي اڳڪٿي هڪ درجه بندي جو ڪم آهي، SAS اڳڪٿيون ڪرڻ لاءِ چار مشهور درجه بندي ماڊل چونڊيا، جن ۾ شامل آهن:
- بي ترتيب forestيلو
- تدريسي واڌارو
- لاجسٽڪ ريگريشن
- نيٽورڪ نيٽ ورڪ
مصنوعي ڊيٽا پيدا ڪرڻ کان اڳ، SAS بي ترتيب طور تي ٽيليڪ ڊيٽا سيٽ کي ٽرين سيٽ ۾ ورهايو (ماڊلن جي تربيت لاءِ) ۽ هڪ هولڊ آئوٽ سيٽ (ماڊلن کي اسڪور ڪرڻ لاءِ). اسڪورنگ لاءِ هڪ الڳ هولڊ آئوٽ سيٽ هجڻ هڪ غيرجانبدارانه اندازي جي اجازت ڏئي ٿو ته نئين ڊيٽا تي لاڳو ٿيڻ تي درجه بندي ماڊل ڪيترو سٺو ڪم ڪري سگهي ٿو.
ٽرين سيٽ کي انپٽ طور استعمال ڪندي، Syntho پنھنجي Syntho انجڻ کي ھڪ مصنوعي ڊيٽا سيٽ تيار ڪرڻ لاءِ استعمال ڪيو. بينچ مارڪنگ لاءِ، SAS پڻ ٺاھيو ٽرين سيٽ جو ھڪ ٺھيل ورزن ھڪڙي مخصوص حد تائين پھچڻ لاءِ گمنامي جي مختلف طريقن کي لاڳو ڪرڻ کان پوءِ (k-anonimity جي). اڳوڻي قدمن جي نتيجي ۾ چار ڊيٽا سيٽس:
- هڪ ٽرين ڊيٽا سيٽ (يعني اصل ڊيٽا سيٽ مائنس هولڊ آئوٽ ڊيٽا سيٽ)
- هڪ هولڊ آئوٽ ڊيٽا سيٽ (يعني اصل ڊيٽا سيٽ جو هڪ ذيلي سيٽ)
- هڪ گمنام ڊيٽا سيٽ (ٽرين جي ڊيٽا سيٽ تي ٻڌل)
- هڪ مصنوعي ڊيٽا سيٽ (ٽرين جي ڊيٽا سيٽ تي ٻڌل)
ڊيٽا سيٽس 1، 3 ۽ 4 استعمال ڪيا ويا ھر ھڪڙي درجه بندي ماڊل کي تربيت ڏيڻ لاء، نتيجي ۾ 12 (3 x 4) تربيتي ماڊل. SAS بعد ۾ استعمال ڪيو هولڊ آئوٽ ڊيٽا سيٽ جي درستگي کي ماپڻ لاءِ جنهن سان هر ماڊل گراهڪ جي چرن جي اڳڪٿي ڪري ٿو. نتيجا ھيٺ پيش ڪيا ويا آھن، ڪجھ بنيادي انگن اکرن سان شروع ڪندي.
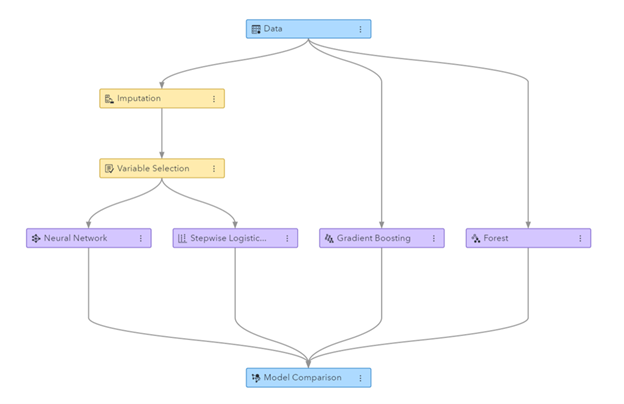
شڪل: مشين لرننگ پائيپ لائين SAS Visual Data Mining and Machine Learning ۾ ٺاهي وئي
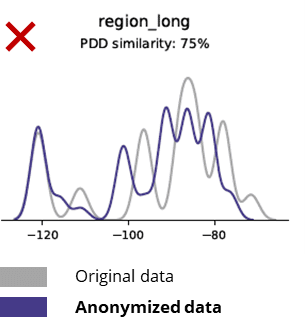
بنيادي انگ اکر جڏهن گمنام ڊيٽا کي اصل ڊيٽا سان ڀيٽيو وڃي
گمنامي ٽيڪنڪ به بنيادي نمونن، ڪاروباري منطق، رشتا ۽ انگ اکر کي تباهه ڪري ٿي (جيئن هيٺ ڏنل مثال ۾). بنيادي اينالائيٽڪس لاءِ گمنام ڊيٽا استعمال ڪندي اهڙيءَ طرح ناقابل اعتبار نتيجا پيدا ڪري ٿي. حقيقت ۾، گمنام ٿيل ڊيٽا جي خراب معيار ان کي جديد تجزياتي ڪمن لاءِ استعمال ڪرڻ لڳ ڀڳ ناممڪن بڻائي ڇڏيو آهي (مثال طور AI/ML ماڊلنگ ۽ ڊيش بورڊنگ).
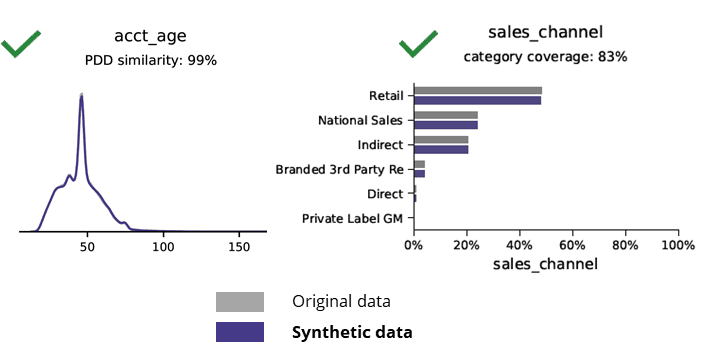
بنيادي انگ اکر جڏهن مصنوعي ڊيٽا کي اصل ڊيٽا سان موازنہ ڪريو
مصنوعي ڊيٽا جي پيداوار AI سان گڏ بنيادي نمونن، ڪاروباري منطق، رشتا ۽ انگ اکر کي محفوظ ڪري ٿو (جيئن هيٺ ڏنل مثال ۾). بنيادي اينالائيٽڪس لاءِ مصنوعي ڊيٽا استعمال ڪندي اهڙيءَ طرح قابل اعتماد نتيجا پيدا ڪري ٿي. اهم سوال، ڇا مصنوعي ڊيٽا ترقي يافته تجزياتي ڪمن لاءِ رکي ٿي (مثال طور AI/ML ماڊلنگ ۽ ڊيش بورڊنگ)؟
AI ٺاهيل مصنوعي ڊيٽا ۽ جديد تجزياتي
مصنوعي ڊيٽا نه رڳو بنيادي نمونن لاءِ رکي ٿي (جيئن ته اڳئين پلاٽن ۾ ڏيکاريل آهي)، اهو پڻ ڳجهو 'لڪيل' شمارياتي نمونن کي قبضو ڪري ٿو جيڪي جديد تجزياتي ڪمن لاءِ گهربل آهن. جنهنڪري هيٺ ڏنل بار چارٽ ۾ ڏيکاريل آهي، اهو ظاهر ڪري ٿو ته مصنوعي ڊيٽا تي تربيت ڪيل ماڊلز جي درستگي ۽ اصل ڊيٽا تي تربيت ڪيل ماڊل هڪجهڙا آهن. ان کان علاوه، 0.5 جي ويجهو وکر (AUC*) جي هيٺان علائقي سان، گمنام ڊيٽا تي تربيت وارا ماڊل تمام بدترين ڪارڪردگي ڪن ٿا. اصل ڊيٽا جي مقابلي ۾ مصنوعي ڊيٽا تي تمام جديد تجزياتي جائزي سان مڪمل رپورٽ درخواست تي دستياب آهي.
*AUC: وکر جي هيٺان ايراضي ترقي يافته تجزياتي ماڊلز جي درستگي لاءِ هڪ ماپ آهي، اڪائونٽ ۾ صحيح مثبت، غلط مثبت، غلط منفي ۽ سچا منفي. 0,5 جو مطلب آھي ھڪڙو ماڊل بي ترتيب انداز ۾ اڳڪٿي ڪري ٿو ۽ ان ۾ ڪا اڳڪٿي ڪرڻ واري طاقت نه آھي ۽ 1 جو مطلب آھي ته ماڊل ھميشه صحيح آھي ۽ مڪمل اڳڪٿي ڪرڻ واري طاقت آھي.
اضافي طور تي، هي مصنوعي ڊيٽا استعمال ڪري سگهجي ٿي ڊيٽا جي خاصيتن کي سمجهڻ ۽ ماڊل جي حقيقي تربيت لاءِ گهربل مکيه متغير. اصل ڊيٽا جي مقابلي ۾ مصنوعي ڊيٽا تي الگورتھم پاران چونڊيل انپٽس تمام گهڻو ملندڙ هئا. انهيء ڪري، ماڊلنگ جي عمل کي هن مصنوعي نسخي تي ڪري سگهجي ٿو، جيڪا ڊيٽا جي ڀڃڪڙي جي خطري کي گھٽائي ٿي. جڏهن ته، جڏهن انفرادي رڪارڊ (مثال طور. telco ڪسٽمر) جو حوالو ڏنو ويو آهي اصل ڊيٽا تي ٻيهر تربيت ڏيڻ جي سفارش ڪئي وئي آهي وضاحت جي لاء، قبوليت وڌائي يا صرف ضابطي جي سبب.
AUC الورورٿم طرفان گروپ ڪيل طريقي سان
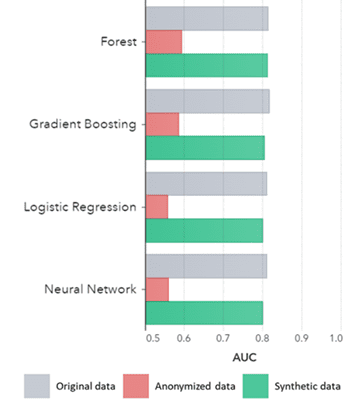
نتيجو:
- مصنوعي ڊيٽا تي تربيت وارا ماڊل اصل ڊيٽا تي تربيت يافته ماڊل جي مقابلي ۾ انتهائي ساڳي ڪارڪردگي ڏيکاريندا آهن
- 'ڪلاسڪ گمنامي ٽيڪنڪس' سان گڏ گمنام ڊيٽا تي تربيت يافته ماڊل اصل ڊيٽا يا مصنوعي ڊيٽا تي تربيت يافته ماڊل جي مقابلي ۾ گهٽ ڪارڪردگي ڏيکاريندا آهن
- مصنوعي ڊيٽا جي پيداوار آسان ۽ تيز آهي ڇو ته ٽيڪنڪ بلڪل ساڳي ڪم ڪري ٿي في ڊيٽا سيٽ ۽ في ڊيٽا جي قسم.
قدر-شامل مصنوعي ڊيٽا استعمال ڪيس
ڪيس 1 استعمال ڪريو: ماڊل ڊولپمينٽ ۽ جديد اينالائيٽڪس لاءِ مصنوعي ڊيٽا
استعمال جي قابل، اعليٰ معيار جي ڊيٽا کي آسان ۽ تيزيءَ سان رسائي حاصل ڪرڻ سان گڏ مضبوط ڊيٽا جو بنياد هجڻ ضروري آهي ماڊلز ٺاهڻ لاءِ (مثال طور ڊيش بورڊ [BI] ۽ جديد تجزياتي [AI ۽ ML]). بهرحال، ڪيتريون ئي تنظيمون هڪ ذيلي اپٽمل ڊيٽا بنيادن جو شڪار آهن جنهن جي نتيجي ۾ 3 اهم چئلينج آهن:
- ڊيٽا تائين رسائي حاصل ڪرڻ عمرون و takesن ٿيون (رازداري) ضابطن ، اندروني عملن يا ڊيٽا سائلز جي ڪري
- ڪلاسيڪل گمنامي ٽيڪنڪ ڊيٽا کي تباهه ڪري ٿي، ڊيٽا کي وڌيڪ مناسب نه آهي تجزيو ۽ جديد تجزيي لاءِ
- موجوده حل اسپيبلبل نه آهن ڇاڪاڻ ته اهي مختلف طريقي سان ڪم ڪن ٿا في ڊيٽا سيٽ ۽ في ڊيٽا جي قسم ۽ نه ٿا سنڀالي سگھن وڏا ملٽي ٽيبل ڊيٽابيس
مصنوعي ڊيٽا جو طريقو: ماڊل ٺاهيو جيئن-سٺو-حقيقي مصنوعي ڊيٽا سان:
- گھٽ ڪريو اصل ڊيٽا جو استعمال ، بغير توھان جي ڊولپرز جي
- ذاتي ڊيٽا کي کوليو ۽ و moreيڪ ڊيٽا تائين رسائي حاصل ڪريو جيڪا ا restricted ۾ محدود هئي (مثال طور رازداري جي ڪري)
- لا Easyاپيل ڊيٽا تائين آسان ۽ تيز ڊيٽا رسائي
- توسيع جو solutionو حل جيڪو سا worksيو ڪم ڪري ٿو هر ڊيٽاسٽ ، ڊيٽائپ ۽ وڏي ڊيٽابيس لاءِ
اهو تنظيم کي اجازت ڏئي ٿو ته هڪ مضبوط ڊيٽا بنياد ٺاهي سگهي ٿو آسان ۽ تيز رسائي سان استعمال جي قابل، اعلي معيار جي ڊيٽا ڊيٽا کي انلاڪ ڪرڻ ۽ ڊيٽا جي موقعن کي فائدو ڏيڻ لاء.
ڪيس 2 استعمال ڪريو: سافٽ ويئر ٽيسٽنگ، ڊولپمينٽ ۽ ترسيل لاءِ سمارٽ مصنوعي ٽيسٽ ڊيٽا
جديد ترين سافٽ ويئر حل پهچائڻ لاءِ اعليٰ معيار جي ٽيسٽ ڊيٽا سان جانچ ۽ ترقي ضروري آهي. اصل پيداوار جي ڊيٽا استعمال ڪرڻ واضح لڳي ٿو، پر (رازداري) ضابطن جي ڪري اجازت نه آهي. متبادل Test Data Management (TDM) اوزار متعارف ڪرايو "legacy-by-design"صحيح ٽيسٽ ڊيٽا حاصل ڪرڻ ۾:
- پيداوار جي ڊيٽا کي ظاهر نه ڪريو ۽ ڪاروباري منطق ۽ حوالن جي سالميت محفوظ نه آهن
- سست ۽ وقت وٺندڙ ڪم
- دستي ڪم جي ضرورت آهي
مصنوعي ڊيٽا جو طريقو: ٽيسٽ ۽ ترقي ڪريو AI سان ٺاهيل مصنوعي ٽيسٽ ڊيٽا کي پهچائڻ لاءِ جديد سافٽ ويئر حل سمارٽ سان:
- پيداوار جهڙو ڊيٽا محفوظ ڪاروباري منطق ۽ حوالي سان سالميت سان
- آسان ۽ تيز ڊيٽا generationاھڻ جديد آرٽ سان AI
- رازداري-جي-ڊزائن
- آسان، تيز ۽ agile
هي تنظيم کي اجازت ڏئي ٿو جانچ ۽ ترقي ڪري ايندڙ سطح جي ٽيسٽ ڊيٽا سان گڏ رياست جي جديد سافٽ ويئر حل پهچائڻ لاءِ!
وڌيڪ ڄاڻ
دلچسپي؟ مصنوعي ڊيٽا بابت وڌيڪ معلومات لاءِ، وڃو Syntho ويب سائيٽ يا Wim Kees Janssen سان رابطو ڪريو. SAS بابت وڌيڪ معلومات لاء، دورو ڪريو www.sas.com يا رابطو ڪريو kees@syntho.ai.
ھن استعمال جي صورت ۾، Syntho، SAS ۽ NL AIC گڏجي ڪم ڪن ٿا مطلوب نتيجا حاصل ڪرڻ لاءِ. Syntho AI-generated synthetic data ۾ هڪ ماهر آهي ۽ SAS تجزياتي ۾ مارڪيٽ ليڊر آهي ۽ ڊيٽا کي ڳولڻ، تجزيو ڪرڻ ۽ ڏسڻ لاءِ سافٽ ويئر پيش ڪري ٿو.
* اڳڪٿيون 2021 - ڊيٽا ۽ تجزياتي حڪمت عمليون گورنمينٽ، اسڪيل ۽ ٽرانسفارم ڊجيٽل بزنس، گارٽنر، 2020.

ھاڻي پنھنجي مصنوعي ڊيٽا ھدايت کي محفوظ ڪريو!
- مصنوعي ڊيٽا ا آهي؟
- تنظيمون ان کي ڇو استعمال ڪندا آهن؟
- قدر شامل ڪرڻ مصنوعي ڊيٽا ڪلائنٽ ڪيس
- ڪيئن شروع ڪجي
