


Syntho жасаған синтетикалық деректерді SAS деректер сарапшылары сыртқы және объективті тұрғыдан бағалайды, тексереді және бекітеді.
Syntho өз пайдаланушыларына сапаны қамтамасыз етудің жетілдірілген есебін мақтанышпен ұсынса да, біз синтетикалық деректерімізді сала жетекшілерінің сыртқы және объективті бағалауының маңыздылығын түсінеміз. Сондықтан синтетикалық деректерімізді бағалау үшін аналитика саласындағы көшбасшы SAS компаниясымен ынтымақтасамыз.
SAS бастапқы деректермен салыстырғанда деректердің дәлдігі, құпиялылықты қорғау және Syntho компаниясының AI жасаған синтетикалық деректерінің қолайлылығы бойынша әртүрлі мұқият бағалаулар жүргізеді. Қорытынды ретінде SAS Syntho синтетикалық деректерін бастапқы деректермен салыстырғанда дәл, қауіпсіз және пайдалануға жарамды деп бағалады және мақұлдады.
Біз мақсатты деректер ретінде «шайқау» болжамы үшін пайдаланылатын телекоммуникациялық деректерді пайдаландық. Бағалаудың мақсаты әртүрлі болжау модельдерін үйрету және әрбір модельдің өнімділігін бағалау үшін синтетикалық деректерді пайдалану болды. Шығаруды болжау жіктеу тапсырмасы болғандықтан, SAS болжамдар жасау үшін танымал жіктеу үлгілерін таңдады, соның ішінде:
Синтетикалық деректерді жасамас бұрын, SAS телекоммуникациялық деректер жинағын пойыз жинағына (модельдерді үйрету үшін) және ұстау жинағына (модельдерді бағалау үшін) кездейсоқ түрде бөледі. Балл қою үшін бөлек күту жиынының болуы жіктеу үлгісі жаңа деректерге қолданғанда қаншалықты жақсы жұмыс істей алатынын объективті бағалауға мүмкіндік береді.
Пойыз жинағын кіріс ретінде пайдаланып, Syntho синтетикалық деректер жинағын жасау үшін Syntho қозғалтқышын пайдаланды. Бенчмаркинг үшін SAS белгілі бір шекке (k-анонимділік) жету үшін әртүрлі анонимдеу әдістерін қолданғаннан кейін пойыз жиынтығының анонимді нұсқасын жасады. Бұрынғы қадамдар төрт деректер жиынтығына әкелді:
1, 3 және 4 деректер жиыны әрбір жіктеу үлгісін үйрету үшін пайдаланылды, нәтижесінде 12 (3 x 4) оқытылған үлгі алынды. Кейіннен SAS тұтынушы шығынын болжаудағы әрбір үлгінің дәлдігін өлшеу үшін күту деректер жинағын пайдаланды.
SAS бастапқы деректермен салыстырғанда деректердің дәлдігі, құпиялылықты қорғау және Syntho компаниясының AI жасаған синтетикалық деректерінің қолайлылығы бойынша әртүрлі мұқият бағалаулар жүргізеді. Қорытынды ретінде SAS Syntho синтетикалық деректерін бастапқы деректермен салыстырғанда дәл, қауіпсіз және пайдалануға жарамды деп бағалады және мақұлдады.
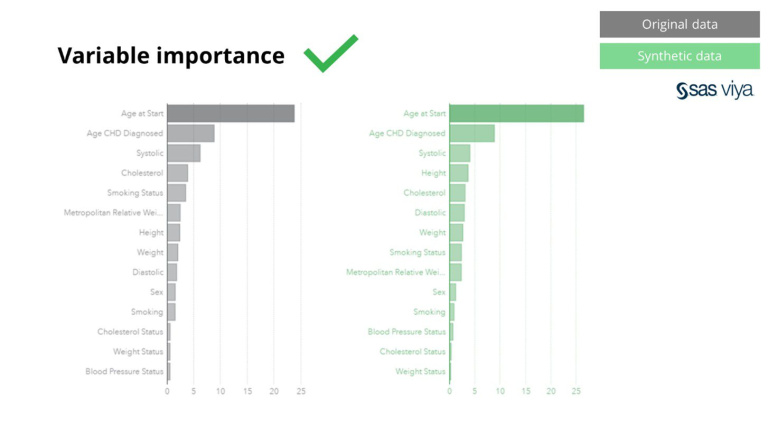
Syntho синтетикалық деректері тек негізгі үлгілерге ғана емес, сонымен қатар кеңейтілген аналитика тапсырмалары үшін қажетті терең «жасырын» статистикалық үлгілерді түсіреді. Соңғысы бағаналы диаграммада көрсетілген, бұл синтетикалық деректерде үйретілген үлгілердің түпнұсқа деректерде үйретілген үлгілермен салыстырғанда дәлдігі ұқсас екенін көрсетеді. Демек, синтетикалық деректерді модельдерді нақты оқыту үшін пайдалануға болады. Синтетикалық деректерде алгоритмдер таңдаған кірістер мен айнымалы маңыздылық бастапқы деректермен салыстырғанда өте ұқсас болды. Демек, модельдеу процесін нақты сезімтал деректерді пайдаланудың баламасы ретінде синтетикалық деректерде жасауға болады деген қорытынды жасалды.
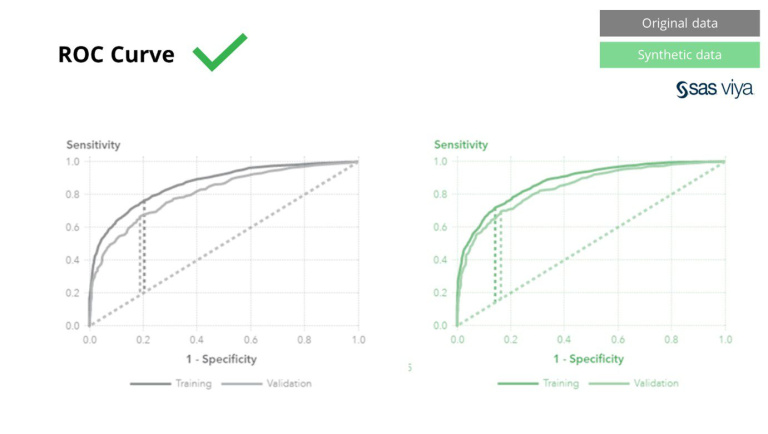
Классикалық анонимизация әдістерінің ортақ қасиеті бар, олар жеке тұлғаларды іздеуге кедергі жасау үшін бастапқы деректерді өңдейді. Олар деректерді манипуляциялайды және осылайша процесте деректерді жояды. Анонимділік неғұрлым көп болса, деректеріңіз соғұрлым жақсы қорғалады, сонымен қатар деректеріңіз жойылады. Бұл әсіресе AI және модельдеу тапсырмалары үшін «болжау күші» маңызды, өйткені сапасыз деректер AI моделінен нашар түсініктерге әкеледі. SAS мұны қисық астындағы аудан (AUC*) 0.5-ке жақын етіп көрсетті, бұл анонимді деректер бойынша дайындалған үлгілердің ең нашар жұмыс істейтінін көрсетті.
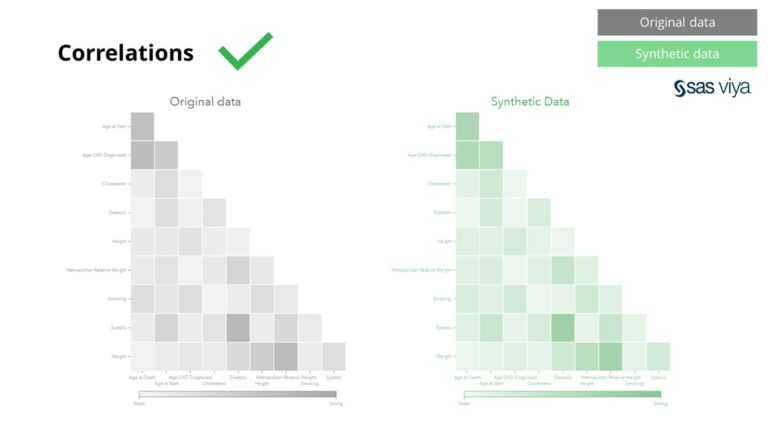
Айнымалылар арасындағы корреляциялар мен қатынастар синтетикалық деректерде дәл сақталған.
Үлгі өнімділігін өлшеуге арналған метрика қисық астындағы аумақ (AUC) тұрақты болып қалды.
Сонымен қатар, модельдегі айнымалылардың болжамдық күшін көрсететін айнымалы мән синтетикалық деректерді бастапқы деректер жиынымен салыстыру кезінде өзгеріссіз қалды.
SAS және SAS Viya пайдалану арқылы осы бақылауларға сүйене отырып, Syntho қозғалтқышы жасаған синтетикалық деректер сапа жағынан нақты деректермен шынымен тең деп сенімді түрде қорытынды жасауға болады. Бұл синтетикалық деректермен кеңейтілген аналитикаға жол ашып, модельді әзірлеу үшін синтетикалық деректерді пайдалануды растайды.
