Վթարի դասընթացի սինթետիկ տվյալներ
ներածություն
Ի՞նչ է սինթետիկ տվյալները:
Պատասխանը համեմատաբար պարզ է. Մինչդեռ բնօրինակ տվյալները հավաքվում են իրական անձանց հետ (օրինակ՝ հաճախորդներ, հիվանդներ, աշխատակիցներ և այլն) և ձեր բոլոր ներքին գործընթացների ընթացքում, սինթետիկ տվյալները ստեղծվում են համակարգչային ալգորիթմի միջոցով: Այս համակարգչային ալգորիթմը ստեղծում է բոլորովին նոր և արհեստական տվյալների կետեր:
Լուծեք տվյալների գաղտնիության խնդիրները
Սինթետիկորեն ստեղծվող տվյալները բաղկացած են բոլորովին նոր և արհեստական տվյալների կետերից, որոնք բնօրինակ տվյալների հետ մեկ առ մեկ կապ չունեն: Հետևաբար, սինթետիկ տվյալների կետերից և ոչ մեկը չի կարող հետագծվել կամ հետափոխվել սկզբնական տվյալների վրա: Արդյունքում, սինթետիկ տվյալները զերծ են գաղտնիության կանոնակարգերից, ինչպիսիք են GDPR-ը և ծառայում են որպես լուծում տվյալների գաղտնիության մարտահրավերները լուծելու և հաղթահարելու համար:
Ընդլայնել և մոդելավորել
Սինթետիկ տվյալների ստեղծման գեներատիվ ասպեկտը թույլ է տալիս ավելացնել և մոդելավորել բոլորովին նոր տվյալներ: Սա գործում է որպես լուծում, երբ դուք չունեք բավարար տվյալներ (տվյալների սակավություն), ցանկանում եք թարմացնել եզրային պատյանները կամ երբ դեռ տվյալներ չունեք:
Այստեղ Syntho- ի ուշադրության կենտրոնում կառուցվածքային տվյալներն են (տվյալները ՝ ձևակերպված տողեր և սյուներ պարունակող աղյուսակներում, ինչպես տեսնում եք Excel թերթերում), բայց մենք միշտ սիրում ենք պատկերների միջոցով պատկերել սինթետիկ տվյալների հայեցակարգը, քանի որ այն ավելի գրավիչ է:
Սինթետիկ տվյալների տեսակները
Սինթետիկ տվյալների հովանոցում գոյություն ունեն երեք տեսակի սինթետիկ տվյալներ: Սինթետիկ տվյալների այդ 3 տեսակներն են՝ կեղծ տվյալներ, կանոնների վրա հիմնված գեներացված սինթետիկ տվյալներ և արհեստական ինտելեկտի (AI) կողմից ստեղծված սինթետիկ տվյալներ։ Մենք կարճ բացատրում ենք, թե որոնք են սինթետիկ տվյալների 3 տարբեր տեսակները:
Կեղծ տվյալներ / կեղծ տվյալներ
Կեղծ տվյալները պատահականորեն գեներացված տվյալներ են (օրինակ՝ կեղծ տվյալների գեներատորի կողմից):
Հետևաբար, բնօրինակ տվյալների մեջ պարունակվող բնութագրերը, հարաբերությունները և վիճակագրական օրինաչափությունները չեն պահպանվում, չեն վերարտադրվում և չեն վերարտադրվում ստեղծված կեղծ տվյալների մեջ: Հետևաբար, կեղծ տվյալների / կեղծ տվյալների ներկայացուցչականությունը նվազագույն է սկզբնական տվյալների համեմատ:
- Երբ օգտագործել այն. փոխարինել ուղղակի նույնացուցիչները (PII) կամ երբ դուք տվյալներ չունեք (դեռևս) և չեք ցանկանում ժամանակ և էներգիա ծախսել կանոնների սահմանման վրա:
Կանոնների վրա հիմնված սինթետիկ տվյալներ
Կանոնների վրա հիմնված գեներացված սինթետիկ տվյալները սինթետիկ տվյալներ են, որոնք ստեղծվել են նախապես սահմանված կանոնների հավաքածուով: Այդ նախապես սահմանված կանոնների օրինակները կարող են լինել այն, որ դուք կցանկանայիք ունենալ սինթետիկ տվյալներ որոշակի նվազագույն արժեքով, առավելագույն արժեքով կամ միջին արժեքով: Ցանկացած բնութագրիչ, հարաբերություններ և վիճակագրական օրինաչափություններ, որոնք դուք կցանկանայիք վերարտադրել կանոնների վրա հիմնված գեներացված սինթետիկ տվյալների մեջ, պետք է նախապես սահմանված լինեն:
Հետևաբար, տվյալների որակը կլինի նույնքան լավ, որքան նախապես սահմանված կանոնների փաթեթը: Սա հանգեցնում է մարտահրավերների, երբ տվյալների բարձր որակը էական է: Նախ, կարելի է սահմանել միայն սահմանափակ կանոնների շարք, որոնք պետք է ներառվեն սինթետիկ տվյալների մեջ: Բացի այդ, մի քանի կանոնների սահմանումը սովորաբար հանգեցնում է համընկնման և հակասական կանոնների: Ավելին, դուք երբեք ամբողջությամբ չեք լուսաբանի բոլոր համապատասխան կանոնները: Ավելին, կարող են լինել համապատասխան կանոններ, որոնց մասին դուք նույնիսկ տեղյակ չեք: Եվ վերջապես (և չմոռանանք), սա ձեզանից շատ ժամանակ և էներգիա կխլի, ինչը կհանգեցնի ոչ արդյունավետ լուծման:
- Երբ օգտագործել այն. երբ դուք տվյալներ չունեք (դեռ)
Արհեստական ինտելեկտի (AI) կողմից ստեղծված սինթետիկ տվյալներ
Ինչպես ակնկալում եք անունից, արհեստական ինտելեկտի (AI) կողմից ստեղծված սինթետիկ տվյալները արհեստական ինտելեկտի (AI) ալգորիթմի կողմից ստեղծվող սինթետիկ տվյալներ են: AI մոդելը վերապատրաստվում է բնօրինակ տվյալների վրա՝ սովորելու բոլոր բնութագրերը, հարաբերությունները և վիճակագրական օրինաչափությունները: Այնուհետև այս AI ալգորիթմը կարող է ստեղծել բոլորովին նոր տվյալների կետեր և մոդելավորել այդ նոր տվյալների կետերն այնպես, որ վերարտադրի բնօրինակ տվյալների բազայի բնութագրերը, հարաբերությունները և վիճակագրական օրինաչափությունները: Սա այն է, ինչ մենք անվանում ենք սինթետիկ տվյալների երկվորյակ:
AI մոդելը ընդօրինակում է բնօրինակ տվյալները՝ սինթետիկ տվյալների երկվորյակներ ստեղծելու համար, որոնք կարող են օգտագործվել որպես բնօրինակ տվյալներ: Սա բացում է օգտագործման տարբեր դեպքեր, երբ AI-ի ստեղծած սինթետիկ տվյալները կարող են օգտագործվել որպես այլընտրանք բնօրինակ (զգայուն) տվյալներ օգտագործելու համար, ինչպես օրինակ՝ AI-ի ստեղծած սինթետիկ տվյալների օգտագործումը որպես թեստային տվյալներ, ցուցադրական տվյալներ կամ վերլուծության համար:
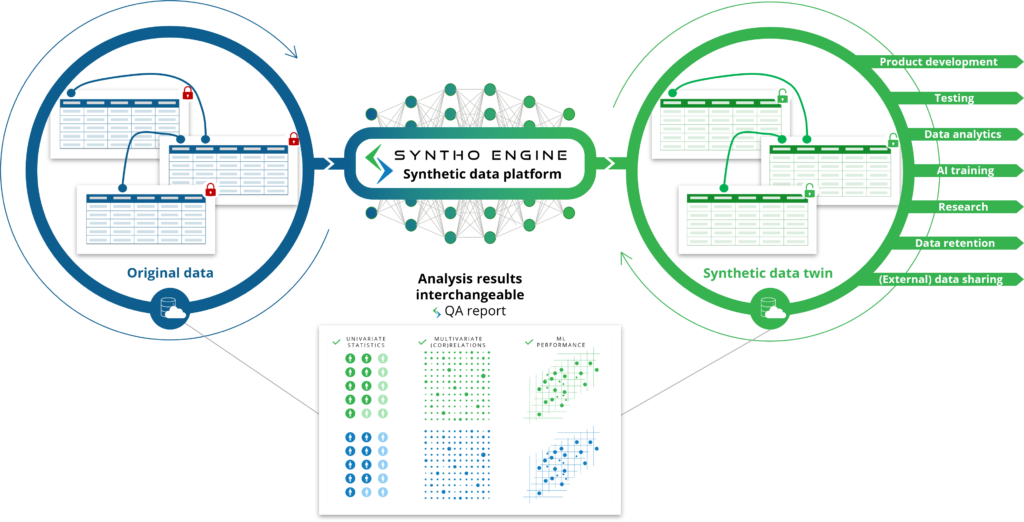
Համեմատած կանոնների վրա հիմնված սինթետիկ տվյալների հետ. փոխանակ ուսումնասիրեք և սահմանեք համապատասխան կանոններ, AI ալգորիթմը դա անում է ավտոմատ կերպով ձեզ համար: Այստեղ լուսաբանվելու են ոչ միայն այն բնութագրերը, հարաբերությունները և վիճակագրական օրինաչափությունները, որոնց մասին դուք տեղյակ եք, այլև բնութագրերը, հարաբերությունները և վիճակագրական օրինաչափությունները, որոնց մասին դուք նույնիսկ տեղյակ չեք:
- Երբ օգտագործել այն. երբ դուք ունեք (որոշ) տվյալներ որպես մուտքագրում ընդօրինակելու կամ որպես ելակետ օգտագործելու խելացի տվյալների ստեղծման և ավելացման գործառույթների համար:
Ինչ տեսակի սինթետիկ տվյալներ օգտագործել:
Կախված ձեր գործածությունից՝ խորհուրդ է տրվում կեղծ տվյալների/ կեղծ տվյալների, կանոնների վրա հիմնված սինթետիկ տվյալների կամ արհեստական ինտելեկտի (AI) կողմից ստեղծված սինթետիկ տվյալների համադրություն: Այս ակնարկը ձեզ տալիս է առաջին ցուցում, թե որ տեսակի սինթետիկ տվյալներ պետք է օգտագործել: Քանի որ Syntho-ն աջակցում է բոլորին, ազատ զգալ կապվեք մեր փորձագետների հետ՝ մեզ հետ ձեր գործածությունը խորացնելու համար:


