


Syntho-ի կողմից ստեղծված սինթետիկ տվյալները գնահատվում, վավերացվում և հաստատվում են արտաքին և օբյեկտիվ տեսանկյունից SAS-ի տվյալների փորձագետների կողմից:
Թեև Syntho-ն հպարտ է իր օգտատերերին առաջարկել որակի ապահովման առաջադեմ զեկույց, մենք նաև հասկանում ենք ոլորտի առաջատարներից մեր սինթետիկ տվյալների արտաքին և օբյեկտիվ գնահատման կարևորությունը: Այդ իսկ պատճառով մենք համագործակցում ենք SAS-ի հետ, որը հանդիսանում է վերլուծության առաջատարը՝ գնահատելու մեր սինթետիկ տվյալները:
SAS-ն իրականացնում է տարբեր մանրակրկիտ գնահատումներ՝ տվյալների ճշգրտության, գաղտնիության պաշտպանության և Syntho-ի AI-ի կողմից ստեղծված սինթետիկ տվյալների օգտագործման վերաբերյալ՝ սկզբնական տվյալների համեմատ: Որպես եզրակացություն, SAS-ը գնահատեց և հաստատեց Syntho-ի սինթետիկ տվյալները որպես ճշգրիտ, անվտանգ և օգտագործելի սկզբնական տվյալների համեմատ:
Որպես թիրախային տվյալներ, մենք օգտագործել ենք հեռահաղորդակցության տվյալները, որոնք օգտագործվում են «խափանման» կանխատեսման համար: Գնահատման նպատակն էր օգտագործել սինթետիկ տվյալներ՝ թրթռման կանխատեսման տարբեր մոդելներ պատրաստելու և յուրաքանչյուր մոդելի կատարողականությունը գնահատելու համար: Քանի որ խափանումների կանխատեսումը դասակարգման խնդիր է, SAS-ն ընտրեց դասակարգման հանրաճանաչ մոդելներ՝ կանխատեսումներ կատարելու համար, այդ թվում՝
Նախքան սինթետիկ տվյալներ ստեղծելը, SAS-ը պատահականորեն բաժանում է հեռահաղորդակցության տվյալների բազան գնացքների հավաքածուի (մոդելները վարժեցնելու համար) և պահվող հավաքածուի (մոդելները գնահատելու համար): Գնահատման համար առանձին պահվող հավաքածու ունենալը թույլ է տալիս անկողմնակալ գնահատել, թե դասակարգման մոդելը որքան լավ կարող է գործել, երբ կիրառվի նոր տվյալների վրա:
Օգտագործելով գնացքի հավաքածուն որպես մուտքագրում՝ Syntho-ն օգտագործեց իր Syntho Engine-ը՝ սինթետիկ տվյալների բազա ստեղծելու համար: Հենանիշավորման համար SAS-ը նաև ստեղծեց գնացքների հավաքածուի անանուն տարբերակը՝ անանունացման տարբեր մեթոդներ կիրառելուց հետո՝ որոշակի շեմի (k-անանունության) հասնելու համար: Նախկին քայլերը հանգեցրին չորս տվյալների հավաքածուի.
1, 3 և 4 տվյալների հավաքածուները օգտագործվել են դասակարգման յուրաքանչյուր մոդելի վերապատրաստման համար, որի արդյունքում ստացվել են 12 (3 x 4) պատրաստված մոդելներ: SAS-ն այնուհետև օգտագործեց պահվող տվյալների բազան՝ յուրաքանչյուր մոդելի ճշգրտությունը հաճախորդի անկման կանխատեսման համար չափելու համար:
SAS-ն իրականացնում է տարբեր մանրակրկիտ գնահատումներ՝ տվյալների ճշգրտության, գաղտնիության պաշտպանության և Syntho-ի AI-ի կողմից ստեղծված սինթետիկ տվյալների օգտագործման վերաբերյալ՝ սկզբնական տվյալների համեմատ: Որպես եզրակացություն, SAS-ը գնահատեց և հաստատեց Syntho-ի սինթետիկ տվյալները որպես ճշգրիտ, անվտանգ և օգտագործելի սկզբնական տվյալների համեմատ:
Syntho-ի սինթետիկ տվյալները վերաբերում են ոչ միայն հիմնական օրինաչափություններին, այն նաև ընդգրկում է խորը «թաքնված» վիճակագրական օրինաչափություններ, որոնք անհրաժեշտ են առաջադեմ վերլուծական առաջադրանքների համար: Վերջինս ցուցադրված է գծապատկերում, ցույց տալով, որ սինթետիկ տվյալների վրա պատրաստված մոդելների ճշգրտությունը և սկզբնական տվյալների վրա պատրաստված մոդելները նման են: Այսպիսով, սինթետիկ տվյալները կարող են օգտագործվել մոդելների իրական վերապատրաստման համար: Սինթետիկ տվյալների վերաբերյալ ալգորիթմների կողմից ընտրված մուտքերը և փոփոխական նշանակությունը սկզբնական տվյալների համեմատ շատ նման էին: Այսպիսով, եզրակացվում է, որ մոդելավորման գործընթացը կարող է իրականացվել սինթետիկ տվյալների վրա՝ որպես իրական զգայուն տվյալների օգտագործման այլընտրանք:
Դասական անանունացման տեխնիկան ընդհանուր է այն, որ նրանք շահարկում են բնօրինակ տվյալները՝ անհատներին հետախուզելու համար խոչընդոտելու համար: Նրանք շահարկում են տվյալները և դրանով իսկ ոչնչացնում տվյալները գործընթացում: Որքան շատ եք անանունացնում, այնքան ավելի լավ է ձեր տվյալները պաշտպանված, բայց նաև այնքան ավելի շատ են ձեր տվյալները ոչնչացվում: Սա հատկապես կործանարար է AI-ի և մոդելավորման առաջադրանքների համար, որտեղ «կանխատեսող ուժը» կարևոր է, քանի որ վատ որակի տվյալները կհանգեցնեն վատ պատկերացումների AI մոդելից: SAS-ը ցույց տվեց դա՝ կորի տակ գտնվող տարածքով (AUC*) մոտ 0.5-ին, ցույց տալով, որ անանուն տվյալների վրա ուսուցանված մոդելները շատ վատն են գործում:
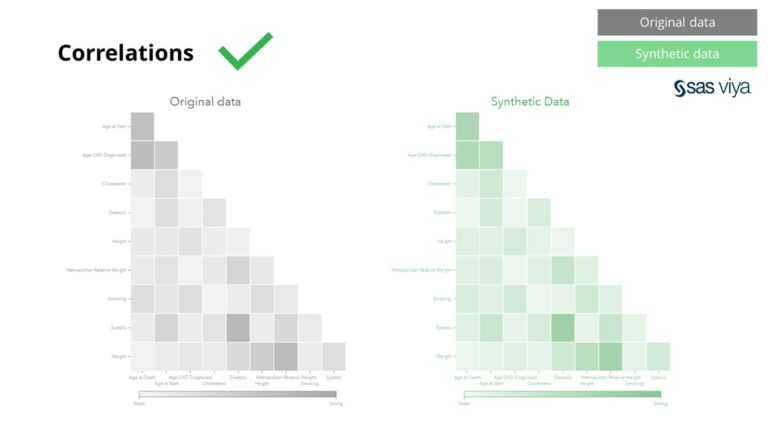
Փոփոխականների միջև փոխկապակցվածությունն ու հարաբերությունները ճշգրտորեն պահպանվել են սինթետիկ տվյալների մեջ:
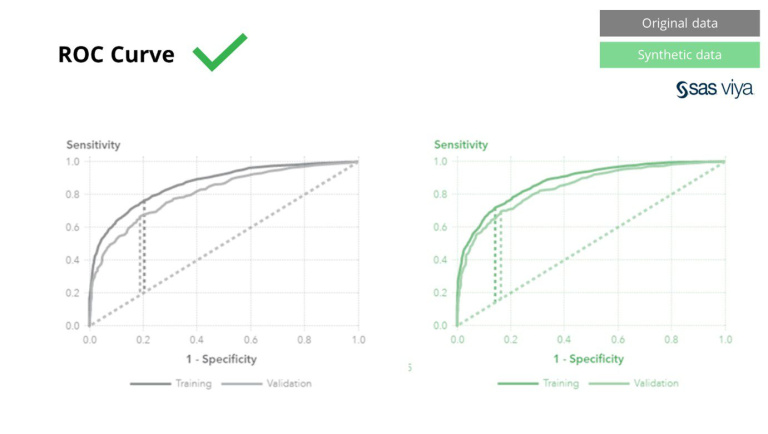
Կորի տակ գտնվող տարածքը (AUC), մոդելի կատարողականությունը չափելու չափիչ, մնաց հետևողական:
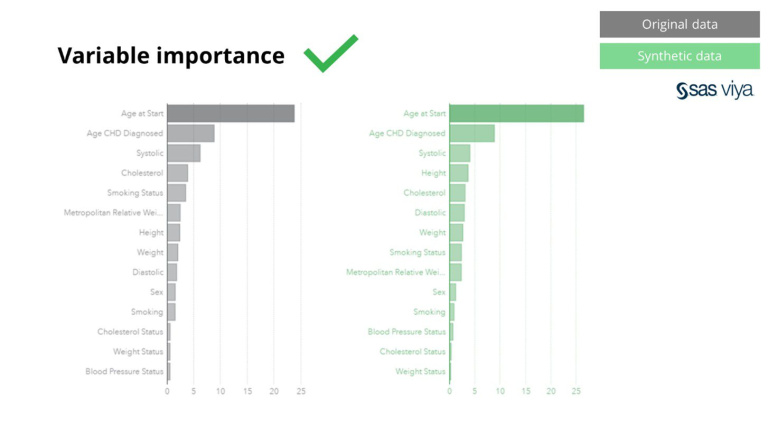
Ավելին, փոփոխականի կարևորությունը, որը ցույց էր տալիս մոդելի փոփոխականների կանխատեսող ուժը, մնաց անփոփոխ՝ սինթետիկ տվյալները սկզբնական տվյալների հետ համեմատելիս:
Ելնելով SAS-ի այս դիտարկումներից և օգտագործելով SAS Viya-ն, մենք կարող ենք վստահորեն եզրակացնել, որ Syntho Engine-ի կողմից գեներացված սինթետիկ տվյալները որակի առումով իսկապես համընկնում են իրական տվյալների հետ: Սա հաստատում է սինթետիկ տվյալների օգտագործումը մոդելի մշակման համար՝ ճանապարհ հարթելով սինթետիկ տվյալների հետ առաջադեմ վերլուծությունների համար:
