AI-ի չտեսնված մեղավորը. Բացահայտելով ներսի կողմնակալությունը
Կողմնակալության բլոգային շարք՝ մաս 1
ներածություն
Մեր աշխարհում, որտեղ ինտելեկտի ավելի ու ավելի արհեստական ձևեր կան, մեքենաները, որոնց հանձնարարված է բարդ որոշումներ կայացնել, ավելի ու ավելի են տարածվում: Գոյություն ունի աճող գրականություն, որը ցույց է տալիս AI-ի օգտագործումը տարբեր ոլորտներում, ինչպիսիք են Բիզնեսը, որոշումների կայացման բարձր մակարդակը և վերջին մի քանի տարիների ընթացքում բժշկական ոլորտում: Այս աճող տարածվածությամբ, սակայն, մարդիկ նկատել են նշված համակարգերում առկա միտումները. Այսինքն, թեև դրանք ի սկզբանե նախագծված են տվյալների մեջ զուտ օրինաչափություններին հետևելու համար, նրանք նախապաշարմունքի նշաններ են ցույց տվել, այն իմաստով, որ կարելի է նկատել տարբեր սեքսիստական և խտրական վարքագիծ: Վերջին Եվրոպական AI ակտ, նաև բավականին լայնորեն անդրադառնում է նման նախապաշարմունքների խնդրին և հիմք է դնում դրա հետ կապված խնդիրների լուծման համար:
Տեխնիկական փաստաթղթերի մշակման տարիների ընթացքում մարդիկ հակված են եղել օգտագործել «կողմնակալություն» տերմինը՝ նկարագրելու ժողովրդագրության որոշակի տեսակների նկատմամբ վարքագծի այս շեղված տեսակը. բառ, որի իմաստը տարբեր է՝ առաջացնելով շփոթություն և բարդացնելով դրան անդրադառնալու խնդիրը:
Այս հոդվածը առաջինն է բլոգային գրառումների շարքից, որոնք ընդգրկում են կողմնակալության թեման: Այս շարքում մենք նպատակ կունենանք ձեզ պարզ, մարսելի պատկերացում տալ AI-ի կողմնակալության մասին: Մենք կներկայացնենք կողմնակալությունը չափելու և նվազագույնի հասցնելու եղանակներ և կուսումնասիրենք սինթետիկ տվյալների դերը ավելի արդար համակարգերի այս ճանապարհին: Մենք նաև կներկայացնենք, թե ինչպես կարող է Syntho-ն՝ սինթետիկ տվյալների արտադրության առաջատար խաղացողը, նպաստել այս ջանքերին: Այսպիսով, անկախ նրանից, թե դուք գործնական պատկերացումներ փնտրող մասնագետ եք, թե պարզապես հետաքրքրված եք այս թեմայով, դուք ճիշտ տեղում եք:
Կողմնակալությունը գործողության մեջ. իրական աշխարհի օրինակ
Դուք կարող եք մտածել, «AI-ի այս կողմնակալությունն ամեն ինչ կարևոր է, բայց ի՞նչ է դա նշանակում ինձ համար, սովորական մարդկանց համար»: Ճշմարտությունն այն է, որ ազդեցությունը հեռուն գնացող է, հաճախ անտեսանելի, բայց հզոր: AI-ի կողմնակալությունը զուտ ակադեմիական հասկացություն չէ. դա իրական աշխարհի խնդիր է՝ լուրջ հետևանքներով:
Որպես օրինակ վերցրեք երեխաների բարեկեցության հոլանդական սկանդալը: Ավտոմատացված համակարգը, ենթադրաբար գործիք, որը ստեղծվել է մարդկային նվազագույն միջամտությամբ արդար և արդյունավետ արդյունքներ ստեղծելու համար, եղել է կողմնակալ: Այն սխալմամբ նշում էր հազարավոր ծնողների խարդախության համար՝ հիմնված թերի տվյալների և ենթադրությունների վրա: Արդյունքը? Ընտանիքներ, որոնք ընկել են իրարանցման մեջ, վնասվել է անձնական հեղինակությունը և ֆինանսական դժվարությունները, բոլորը՝ արհեստական ինտելեկտի համակարգի կողմնակալության պատճառով: Հենց սրա նման օրինակներն են ընդգծում արհեստական ինտելեկտում կողմնակալության լուծման հրատապությունը:

Աղբյուր՝ «Compensatie ouders toeslagenaffaire kan zomaar tot 2030 duren», 2023. ՄԵՐ
Բայց եկեք դրանով չսահմանափակվենք։ Այս միջադեպը ավերածություններ առաջացնող կողմնակալության առանձին դեպք չէ: AI-ի մեջ կողմնակալության ազդեցությունը տարածվում է մեր կյանքի բոլոր անկյուններում: Սկսած, թե ով է աշխատանքի ընդունվում աշխատանքի, ով ստանում է վարկի հաստատում, մինչև ով ինչ բժշկական բուժում է ստանում՝ կանխակալ AI համակարգերը կարող են հավերժացնել առկա անհավասարությունները և ստեղծել նորերը:
Հաշվի առեք սա. AI համակարգը, որը վերապատրաստվել է կանխակալ պատմական տվյալների վրա, կարող է լավ որակավորված թեկնածուին զրկել աշխատանքից միայն նրանց սեռի կամ էթնիկ պատկանելության պատճառով: Կամ կողմնակալ AI համակարգը կարող է մերժել վարկը արժանի թեկնածուին իր փոստային ինդեքսի պատճառով: Սրանք պարզապես հիպոթետիկ սցենարներ չեն. դրանք տեղի են ունենում հենց հիմա:
Կողմնակալության հատուկ տեսակները, ինչպիսիք են Պատմական կողմնակալությունը և չափման կողմնակալությունը, հանգեցնում են նման թերի որոշումների: Դրանք բնորոշ են տվյալներին, խորապես արմատավորված են հասարակական կողմնակալության մեջ և արտացոլվում են ժողովրդագրական տարբեր խմբերի միջև անհավասար արդյունքներով: Նրանք կարող են շեղել կանխատեսող մոդելների որոշումները և հանգեցնել անարդար վերաբերմունքի:
Իրերի մեծ սխեմայի համաձայն, AI-ի կողմնակալությունը կարող է հանդես գալ որպես լուռ ազդեցիկ՝ նրբորեն ձևավորելով մեր հասարակությունը և մեր կյանքը, հաճախ այնպիսի ձևերով, որոնք մենք նույնիսկ չենք գիտակցում: Վերոհիշյալ բոլոր կետերը ձեզ կարող են հանգեցնել այն հարցի, թե ինչու չեն ձեռնարկվել գործողություններ դադարեցնելու համար, և արդյոք դա հնարավոր է:
Իրոք, նոր տեխնոլոգիական առաջընթացի շնորհիվ գնալով ավելի մատչելի է դառնում նման խնդրի լուծումը: Այնուամենայնիվ, այս խնդրի լուծման առաջին քայլը դրա գոյությունն ու ազդեցությունը հասկանալն ու ընդունելն է: Առայժմ դրա գոյության ճանաչումը ստեղծվել է՝ թողնելով «ըմբռնման» հարցը դեռ բավական անորոշ։
Հասկանալով կողմնակալություն
Մինչդեռ կողմնակալության սկզբնական սահմանումը, ինչպես ներկայացված է Քեմբրիջի բառարան շատ չի շեղվում բառի հիմնական նպատակից, քանի որ այն վերաբերում է AI-ին, շատ տարբեր մեկնաբանություններ պետք է արվեն նույնիսկ այս եզակի սահմանմանը: Տաքսոնոմիաները, ինչպիսիք են հետազոտողները, ինչպիսիք են Hellström et al (2020) և Կլիգր (2021), տրամադրել ավելի խորը պատկերացումներ կողմնակալության սահմանման վերաբերյալ: Այս փաստաթղթերին պարզ հայացք նետելը, սակայն, կբացահայտի, որ խնդրի արդյունավետ լուծման համար անհրաժեշտ է տերմինի սահմանման մեծ նեղացում:
Իրադարձությունների փոփոխություն լինելով հանդերձ, կողմնակալության իմաստը օպտիմալ կերպով սահմանելու և փոխանցելու համար կարելի է ավելի լավ սահմանել հակառակը, դա արդարությունն է:
Արդարության սահմանում
Ինչպես սահմանվում է տարբեր վերջին գրականության մեջ, ինչպիսիք են Castelnovo et al. (2022), արդարությունը կարելի է մշակել՝ հաշվի առնելով պոտենցիալ տարածություն տերմինի ըմբռնումը: Քանի որ գոյություն ունի, պոտենցիալ տարածությունը (PS) վերաբերում է անհատի կարողությունների և գիտելիքների չափին՝ անկախ ժողովրդագրական որոշակի խմբի պատկանելությունից: Հաշվի առնելով PS հասկացության այս սահմանումը, կարելի է հեշտությամբ սահմանել արդարությունը՝ որպես հավասար PS ունեցող երկու անհատների միջև հավասար վերաբերմունք՝ անկախ նրանց տեսանելի և թաքնված տարբերություններից, որոնք առաջացնում են կողմնակալություն առաջացնող պարամետրերում (օրինակ՝ ռասայական, տարիք կամ սեռ): Այս սահմանումից ցանկացած շեղում, որը նաև կոչվում է հնարավորությունների հավասարություն, կողմնակալության հստակ ցուցիչ է և արժանի է հետագա հետաքննության:
Ընթերցողների շրջանում պրակտիկանտները կարող են նկատել, որ ինչ-որ բանի հասնելը, ինչպես սահմանված է այստեղ, կարող է լիովին անհնար լինել՝ հաշվի առնելով մեր աշխարհում գոյություն ունեցող բնածին կողմնակալությունները: Դա ճիշտ է! Աշխարհը, որտեղ մենք ապրում ենք, այս աշխարհում տեղի ունեցող դեպքերից հավաքագրված բոլոր տվյալների հետ մեկտեղ ենթարկվում է պատմական և վիճակագրական շատ կողմնակալության: Սա, իսկապես, նվազեցնում է վստահությունը, որ մի օր լիովին մեղմացնում է կանխակալության ազդեցությունը կանխատեսող մոդելների վրա, որոնք պատրաստված են նման «կողմնակալ» տվյալների վրա: Այնուամենայնիվ, տարբեր մեթոդների կիրառման միջոցով կարելի է փորձել նվազագույնի հասցնել կողմնակալության ազդեցությունը: Այս դեպքում, այս բլոգի գրառում(ներ)ում օգտագործված տերմինաբանությունը կփոխի կողմնակալության ազդեցությունը նվազագույնի հասցնելու գաղափարը, այլ ոչ թե ամբողջությամբ մեղմելու այն:
Լավ! Այսպիսով, հիմա, երբ առաջ է քաշվել գաղափար, թե ինչ է կողմնակալությունը և ինչպես կարելի է գնահատել դրա գոյությունը. Եթե մենք ցանկանում ենք ճիշտ լուծել խնդիրը, այնուամենայնիվ, մենք պետք է իմանանք, թե որտեղից են ծագում այս բոլոր կողմնակալությունները:
Հասկանալով աղբյուրները և տեսակները
Առկա հետազոտությունները արժեքավոր պատկերացումներ են տալիս մեքենայական ուսուցման տարբեր տեսակի կողմնակալության վերաբերյալ: Ինչպես Մեհրաբի և. ալ. (2019) անցել են մեքենայական ուսուցման մեջ կողմնակալությունների բաժանմանը, կարելի է բաժանել կողմնակալությունները 3 հիմնական կատեգորիաների: Մասնավորապես՝
- Տվյալներ դեպի ալգորիթմ. կատեգորիա, որը ներառում է կողմնակալություններ, որոնք բխում են հենց տվյալներից: Հնարավոր է, որ դա պայմանավորված է տվյալների վատ հավաքագրմամբ, աշխարհում գոյություն ունեցող բնածին կողմնակալությամբ և այլն:
- Ալգորիթմ դեպի օգտվող. կատեգորիա, որը կենտրոնանում է կողմնակալությունների վրա, որոնք բխում են ալգորիթմների նախագծումից և ֆունկցիոնալությունից: Այն ներառում է, թե ինչպես ալգորիթմները կարող են մեկնաբանել, կշռել կամ դիտարկել որոշակի տվյալների կետեր մյուսների նկատմամբ, ինչը կարող է հանգեցնել կողմնակալ արդյունքների:
- User to Data. վերաբերում է կողմնակալությանը, որն առաջանում է համակարգի հետ օգտագործողի փոխազդեցությունից: Այն եղանակը, որով օգտատերերը մուտքագրում են տվյալներ, նրանց բնորոշ կողմնակալությունները կամ նույնիսկ նրանց վստահությունը համակարգի արդյունքների նկատմամբ, կարող են ազդել արդյունքների վրա:
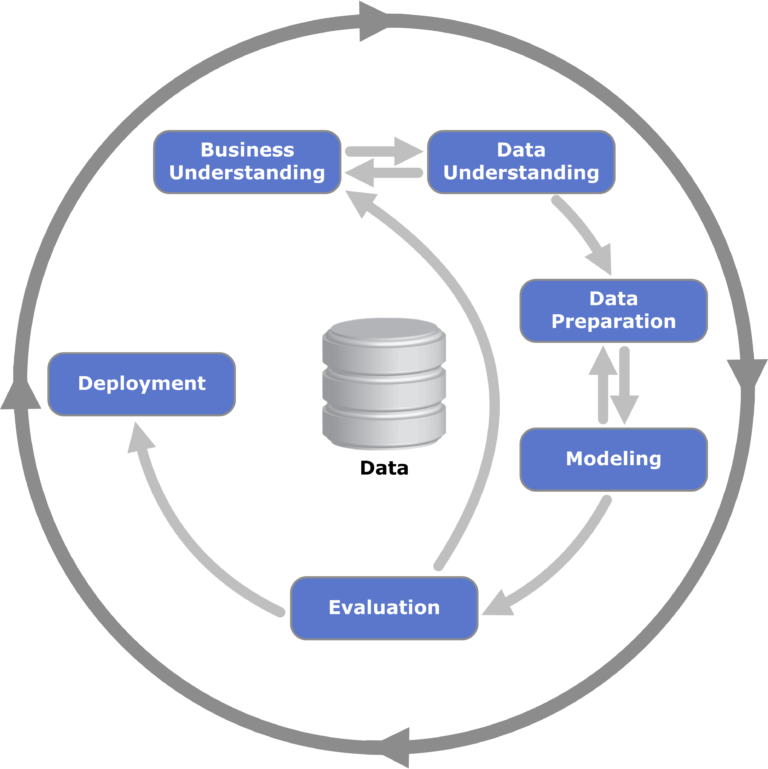
Նկար 1. CRISP-DM շրջանակի պատկերացում տվյալների արդյունահանման համար; սովորաբար օգտագործվում է տվյալների արդյունահանման մեջ և վերաբերում է այն փուլերի բացահայտման գործընթացին, որոնցում կողմնակալությունը կարող է առաջանալ:
Թեև անունները ցույց են տալիս կողմնակալության ձևը, դեռևս կարող են հարցեր ունենալ, թե ինչ տեսակի կողմնակալություն կարելի է դասակարգել այս հովանու ներքո: Մեր ընթերցողների էնտուզիաստների համար մենք տրամադրել ենք այս տերմինաբանության և դասակարգման հետ կապված որոշ գրականության հղումներ: Այս բլոգի գրառման մեջ պարզության համար մենք կանդրադառնանք մի քանի ընտրված կողմնակալության, որոնք առնչվում են իրավիճակին (գրեթե բոլորը ալգորիթմի տվյալների կատեգորիային են): Շեղումների հատուկ տեսակները հետևյալն են.
- Պատմական կողմնակալություն. Տարբեր սոցիալական խմբերի և ընդհանրապես հասարակության մեջ աշխարհում գոյություն ունեցող բնական կողմնակալության հետևանքով առաջացած տվյալներին բնորոշ կողմնակալության տեսակ: Աշխարհում այս տվյալների բնորոշ լինելու պատճառով է, որ դրանք չեն կարող մեղմվել նմուշառման և առանձնահատկությունների ընտրության տարբեր միջոցներով:
- Չափման կողմնակալություն և ներկայացման կողմնակալություն. այս երկու սերտորեն կապված կողմնակալությունները տեղի են ունենում, երբ տվյալների բազայի տարբեր ենթախմբերը պարունակում են անհավասար քանակությամբ «բարենպաստ» արդյունքներ: Հետևաբար, այս տեսակի կողմնակալությունը կարող է շեղել կանխատեսող մոդելների արդյունքը
- Ալգորիթմական կողմնակալություն. կողմնակալություն, որը զուտ կապված է օգտագործվող ալգորիթմի հետ: Ինչպես նկատվեց նաև անցկացված թեստերում (հետագայում մանրամասն նկարագրված է գրառման մեջ), այս տեսակի կողմնակալությունը կարող է հսկայական ազդեցություն ունենալ տվյալ ալգորիթմի արդարության վրա:
Մեքենայական ուսուցման մեջ կողմնակալության այս հիմնարար ըմբռնումները կօգտագործվեն հետագա հաղորդագրություններում խնդիրը ավելի արդյունավետ լուծելու համար:
Վերջնական Մտքեր
Արհեստական ինտելեկտի շրջանակներում կողմնակալության այս հետազոտության ընթացքում մենք լուսաբանել ենք այն խորը հետևանքները, որոնք այն ունի մեր աճող AI-ի վրա հիմնված աշխարհում: Իրական աշխարհի օրինակներից, ինչպիսին է Հոլանդիայի երեխաների բարեկեցության սկանդալը, մինչև կողմնակալության կատեգորիաների և տեսակների բարդ նրբությունները, ակնհայտ է, որ կողմնակալության ճանաչումն ու ըմբռնումը առաջնային է:
Թեև կողմնակալության հետևանքով առաջացած մարտահրավերները՝ լինեն դրանք պատմական, ալգորիթմական կամ օգտագործողի կողմից առաջացած, նշանակալի են, դրանք անհաղթահարելի չեն: Կողմնակալության ծագման և դրսևորումների վերաբերյալ ամուր ըմբռնմամբ՝ մենք ավելի լավ պատրաստված ենք դրանք լուծելու համար: Այնուամենայնիվ, ճանաչումն ու ըմբռնումը միայն մեկնարկային կետերն են:
Երբ մենք առաջ ենք շարժվում այս շարքում, մեր հաջորդ ուշադրությունը կլինի մեր տրամադրության տակ գտնվող շոշափելի գործիքների և շրջանակների վրա: Ինչպե՞ս ենք մենք չափում կողմնակալության աստիճանը AI մոդելներում: Եվ որ ավելի կարևոր է, ինչպե՞ս նվազագույնի հասցնենք դրա ազդեցությունը: Սրանք այն հրատապ հարցերն են, որոնց մեջ մենք կխորանանք հաջորդիվ, ապահովելով, որ AI-ն շարունակում է զարգանալ, դա անում է այնպես, որ արդար և արդյունավետ լինի:

Տվյալները սինթետիկ են, բայց մեր թիմն իրական է:
Կապվեք Syntho- ի հետ և մեր փորձագետներից մեկը լույսի արագությամբ կկապվի ձեզ հետ՝ ուսումնասիրելու սինթետիկ տվյալների արժեքը: