Szybki kurs danych syntetycznych
ZOBACZ WIĘCEJ
skontaktuj się z nami
Wprowadzenie
Co to są dane syntetyczne?
Odpowiedź jest stosunkowo prosta. Podczas gdy oryginalne dane są gromadzone we wszystkich Twoich interakcjach z prawdziwymi osobami (np. klientami, pacjentami, pracownikami itp.) oraz za pośrednictwem wszystkich Twoich procesów wewnętrznych, dane syntetyczne są generowane przez algorytm komputerowy. Ten algorytm komputerowy generuje zupełnie nowe i sztuczne punkty danych.
Rozwiązuj wyzwania związane z prywatnością danych
Dane wygenerowane syntetycznie składają się z zupełnie nowych i sztucznych punktów danych bez relacji jeden-do-jednego z danymi oryginalnymi. W związku z tym żadnego z syntetycznych punktów danych nie można prześledzić ani odtworzyć z oryginalnymi danymi. W rezultacie dane syntetyczne są zwolnione z przepisów dotyczących prywatności, takich jak RODO i służą jako rozwiązanie do rozwiązywania i przezwyciężania problemów związanych z prywatnością danych.
Rozszerz i symuluj
Aspekt generatywny generowania danych syntetycznych pozwala na powiększanie i symulowanie zupełnie nowych danych. Funkcjonuje to jako rozwiązanie, gdy nie masz wystarczającej ilości danych (niedobór danych), chciałbyś wykonać próbkowanie w skrajnych przypadkach lub gdy nie masz jeszcze danych.
W tym przypadku Syntho koncentruje się na danych strukturalnych (dane sformatowane w tabelach zawierających wiersze i kolumny, jak widać w arkuszach Excela), ale zawsze lubimy ilustrować koncepcję danych syntetycznych za pomocą obrazów, ponieważ jest to bardziej atrakcyjne.
Rodzaje danych syntetycznych
W ramach danych syntetycznych istnieją trzy rodzaje danych syntetycznych. Te 3 rodzaje danych syntetycznych to: dane fikcyjne, dane syntetyczne generowane na podstawie reguł oraz dane syntetyczne generowane przez sztuczną inteligencję (AI). Krótko wyjaśniamy, czym są 3 różne rodzaje danych syntetycznych.
Dane fikcyjne / dane pozorne
Dane fikcyjne to dane generowane losowo (np. przez generator danych pozornych).
W konsekwencji cechy, relacje i wzorce statystyczne, które znajdują się w oryginalnych danych, nie są zachowywane, przechwytywane i odtwarzane w wygenerowanych danych fikcyjnych. W związku z tym reprezentatywność danych fikcyjnych / danych pozornych jest minimalna w porównaniu z danymi oryginalnymi.
- Kiedy używać: do zastąpienia identyfikatorów bezpośrednich (PII) lub gdy nie masz (jeszcze) danych i nie chcesz tracić czasu i energii na definiowanie reguł.
Dane syntetyczne generowane na podstawie reguł
Dane syntetyczne generowane na podstawie reguł to dane syntetyczne generowane przez wstępnie zdefiniowany zestaw reguł. Przykładami tych predefiniowanych reguł może być chęć posiadania danych syntetycznych o określonej wartości minimalnej, maksymalnej lub średniej. Wszelkie cechy, relacje i wzorce statystyczne, które chciałbyś odtworzyć w danych syntetycznych generowanych na podstawie reguł, muszą być wstępnie zdefiniowane.
W rezultacie jakość danych będzie tak dobra, jak wstępnie zdefiniowany zestaw reguł. Powoduje to wyzwania, gdy najważniejsza jest wysoka jakość danych. Po pierwsze, można zdefiniować tylko ograniczony zestaw reguł, które mają być uchwycone w danych syntetycznych. Ponadto skonfigurowanie wielu reguł zwykle powoduje nakładanie się i konflikt reguł. Co więcej, nigdy nie omówisz w pełni wszystkich istotnych zasad. Ponadto mogą istnieć odpowiednie zasady, o których nawet nie wiesz. I wreszcie (nie zapominajmy), że zajmie Ci to dużo czasu i energii, czego efektem będzie nieefektywne rozwiązanie.
- Kiedy używać: kiedy nie masz danych (jeszcze)
Dane syntetyczne generowane przez sztuczną inteligencję (AI)
Jak można się spodziewać po nazwie, dane syntetyczne generowane przez sztuczną inteligencję (AI) to dane syntetyczne generowane przez algorytm sztucznej inteligencji (AI). Model AI jest szkolony na oryginalnych danych, aby poznać wszystkie cechy, relacje i wzorce statystyczne. Następnie ten algorytm sztucznej inteligencji jest w stanie generować zupełnie nowe punkty danych i modelować te nowe punkty danych w taki sposób, że odtwarza cechy, relacje i wzorce statystyczne z oryginalnego zestawu danych. Nazywamy to syntetycznym bliźniakiem danych.
Model sztucznej inteligencji naśladuje oryginalne dane w celu wygenerowania bliźniaków danych syntetycznych, których można używać tak, jakby były to oryginalne dane. Odblokowuje to różne przypadki użycia, w których dane syntetyczne generowane przez sztuczną inteligencję mogą być wykorzystywane jako alternatywa dla oryginalnych (wrażliwych) danych, takich jak wykorzystanie danych syntetycznych generowanych przez sztuczną inteligencję jako danych testowych, danych demonstracyjnych lub do analizy.
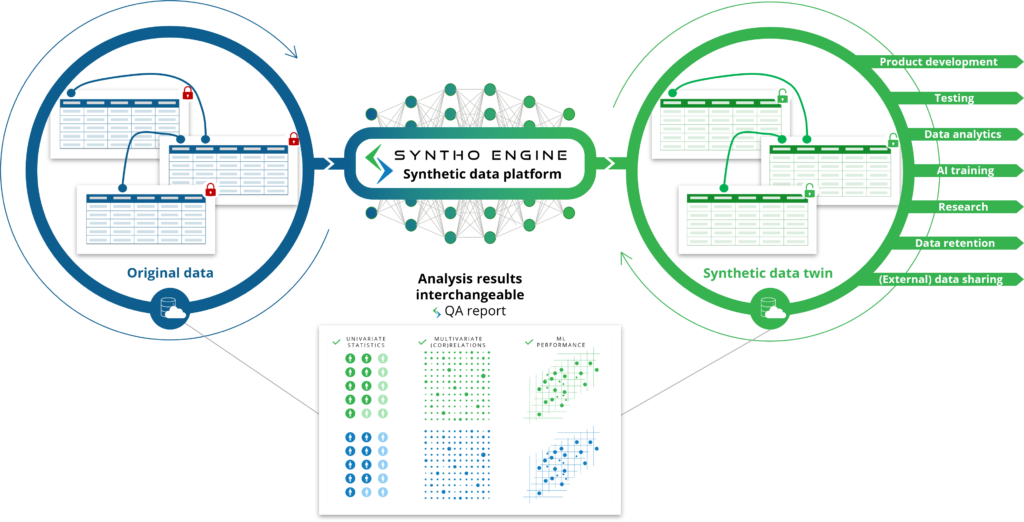
W porównaniu do danych syntetycznych generowanych na podstawie reguł: zamiast studiować i definiować odpowiednie reguły, algorytm AI robi to automatycznie za Ciebie. Tutaj omówione zostaną nie tylko cechy, relacje i wzorce statystyczne, których jesteś świadomy, ale także cechy, relacje i wzorce statystyczne, których nawet nie jesteś świadomy.
- Kiedy tego użyć: gdy masz (niektóre) dane jako dane wejściowe do naśladowania lub do wykorzystania jako punkt wyjścia do inteligentnego generowania danych i funkcji rozszerzania
Jakiego rodzaju danych syntetycznych użyć?
W zależności od przypadku użycia zaleca się połączenie danych fikcyjnych / danych pozornych, danych syntetycznych generowanych na podstawie reguł lub danych syntetycznych generowanych przez sztuczną inteligencję (AI). Ten przegląd zawiera pierwszą wskazówkę, jakiego rodzaju danych syntetycznych należy użyć. Ponieważ Syntho obsługuje je wszystkie, zachęcamy do kontaktu z naszymi ekspertami, aby zgłębić u nas swój przypadek użycia.


