


Data sintetis sing digawe dening Syntho ditaksir, divalidasi lan disetujoni saka sudut pandang eksternal lan obyektif dening ahli data SAS.
Sanajan Syntho bangga nawakake laporan jaminan kualitas sing luwih maju, kita uga ngerti pentinge duwe evaluasi eksternal lan objektif babagan data sintetik saka pimpinan industri. Pramila kita kolaborasi karo SAS, pimpinan analitik, kanggo netepake data sintetik kita.
SAS nganakake macem-macem evaluasi lengkap babagan akurasi data, proteksi privasi, lan kegunaan data sintetik sing digawe AI Syntho dibandhingake karo data asli. Minangka kesimpulan, SAS ngevaluasi lan nyetujoni data sintetik Syntho minangka akurat, aman, lan bisa digunakake dibandhingake karo data asli.
Kita nggunakake data telekomunikasi sing digunakake kanggo prediksi "churn" minangka data target. Tujuan evaluasi yaiku nggunakake data sintetik kanggo nglatih macem-macem model prediksi churn lan kanggo netepake kinerja saben model. Amarga prediksi churn minangka tugas klasifikasi, SAS milih model klasifikasi populer kanggo nggawe prediksi, kalebu:
Sadurunge ngasilake data sintetik, SAS misahake set data telekomunikasi kanthi acak dadi set sepur (kanggo latihan model) lan set holdout (kanggo menehi skor model). Duwe set holdout sing kapisah kanggo nyetak ngidini penilaian sing ora bias babagan kepiye model klasifikasi bisa ditindakake nalika ditrapake ing data anyar.
Nggunakake set sepur minangka input, Syntho nggunakake Mesin Syntho kanggo ngasilake set data sintetik. Kanggo benchmarking, SAS uga nggawe versi anonim saka pesawat sepur sawise nggunakake macem-macem teknik anonim kanggo nggayuh ambang tartamtu (saka k-anonim). Langkah-langkah sadurunge ngasilake papat dataset:
Dataset 1, 3 lan 4 digunakake kanggo nglatih saben model klasifikasi, ngasilake 12 (3 x 4) model sing dilatih. SAS banjur nggunakake dataset holdout kanggo ngukur akurasi saben model ing prediksi churn pelanggan.
SAS nganakake macem-macem evaluasi lengkap babagan akurasi data, proteksi privasi, lan kegunaan data sintetik sing digawe AI Syntho dibandhingake karo data asli. Minangka kesimpulan, SAS ngevaluasi lan nyetujoni data sintetik Syntho minangka akurat, aman, lan bisa digunakake dibandhingake karo data asli.
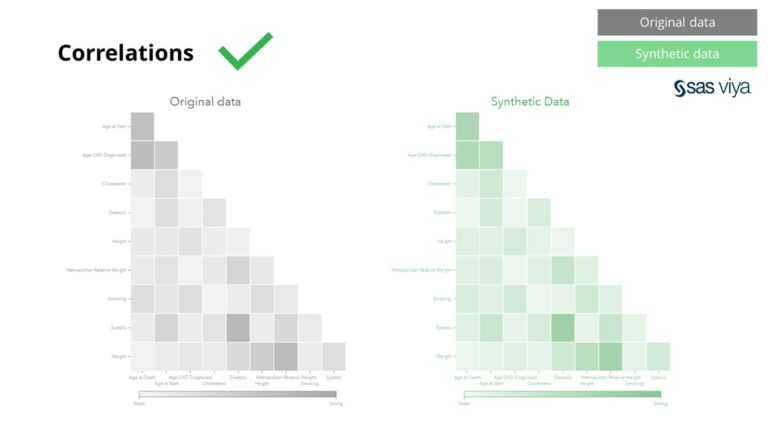
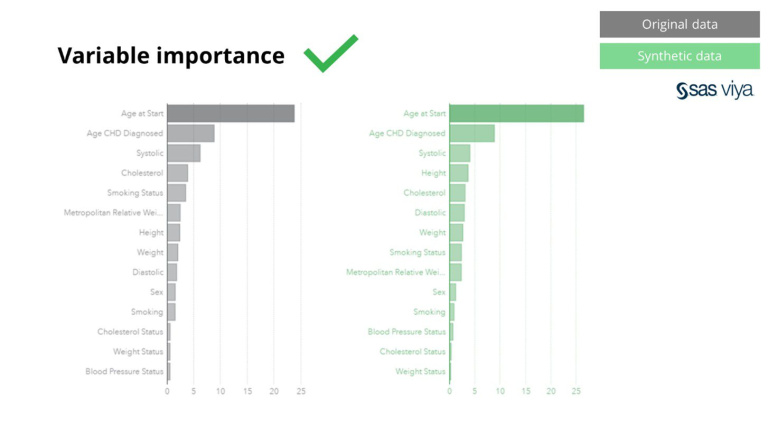
Data sintetis saka Syntho ora mung kanggo pola dhasar, nanging uga njupuk pola statistik 'didhelikake' jero sing dibutuhake kanggo tugas analisis lanjut. Sing terakhir dituduhake ing bagan garis, nuduhake manawa akurasi model sing dilatih ing data sintetik karo model sing dilatih ing data asli padha. Mula, data sintetik bisa digunakake kanggo latihan model sing nyata. Input lan variabel penting sing dipilih dening algoritma ing data sintetik dibandhingake karo data asli padha banget. Mula, disimpulake yen proses pemodelan bisa ditindakake ing data sintetik, minangka alternatif kanggo nggunakake data sensitif nyata.
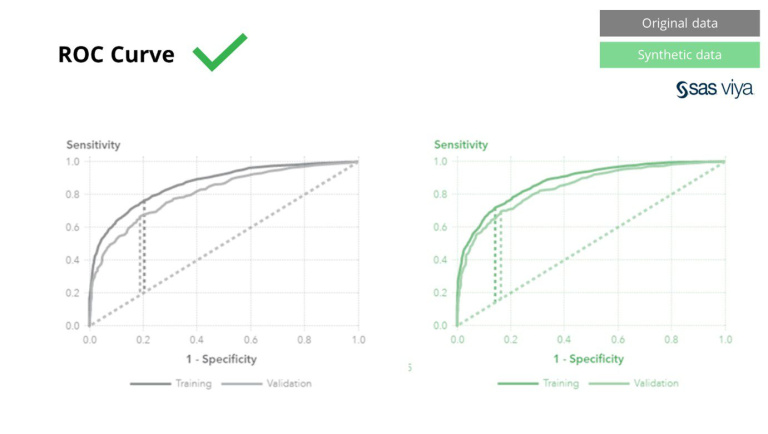
Teknik anonimisasi klasik duwe persamaan sing padha ngapusi data asli kanggo ngalang-alangi nelusuri wong liya. Dheweke ngapusi data lan kanthi mangkono ngrusak data ing proses kasebut. Yen sampeyan anonim, luwih apik data sampeyan dilindhungi, nanging uga data sampeyan bakal rusak. Iki utamané ngancurake kanggo AI lan tugas modeling ngendi "daya prediksi" iku penting, amarga data kualitas ala bakal nyebabake pemahaman ala saka model AI. SAS nduduhake iki, kanthi area ing sangisore kurva (AUC *) cedhak karo 0.5, nuduhake manawa model sing dilatih ing data anonim nindakake paling awon.
Korelasi lan hubungan antarane variabel disimpen kanthi akurat ing data sintetik.
Area Under the Curve (AUC), metrik kanggo ngukur kinerja model, tetep konsisten.
Salajengipun, pentinge variabel, sing nuduhake daya prediksi variabel ing model, tetep utuh nalika mbandhingake data sintetik karo dataset asli.
Adhedhasar pengamatan kasebut dening SAS lan kanthi nggunakake SAS Viya, kita bisa yakin manawa data sintetik sing diasilake dening Mesin Syntho pancen cocog karo data nyata babagan kualitas. Iki validasi panggunaan data sintetik kanggo pangembangan model, mbukak dalan kanggo analitik canggih kanthi data sintetik.
