Sintetički podaci generirani umjetnom inteligencijom, lak i brz pristup podacima visokog kvaliteta?
AI je generirao sintetičke podatke u praksi
Syntho, stručnjak za sintetičke podatke generirane umjetnom inteligencijom, ima za cilj da se okrene privacy by design u konkurentsku prednost sa sintetičkim podacima generiranim umjetnom inteligencijom. Oni pomažu organizacijama da izgrade snažnu osnovu podataka uz lak i brz pristup visokokvalitetnim podacima i nedavno su osvojili nagradu za inovacije kompanije Philips.
Međutim, sintetičko generiranje podataka s AI je relativno novo rješenje koje obično uvodi često postavljana pitanja. Kako bi odgovorio na njih, Syntho je započeo studiju slučaja zajedno sa SAS-om, tržišnim liderom u naprednoj analitici i softveru AI.
U saradnji sa Holandskom koalicijom za veštačku inteligenciju (NL AIC), istražili su vrednost sintetičkih podataka upoređujući sintetičke podatke generisane veštačkom inteligencijom koje generiše Syntho Engine sa originalnim podacima putem različitih procena kvaliteta podataka, pravne valjanosti i upotrebljivosti.
Zar anonimizacija podataka nije rješenje?
Klasične tehnike anonimizacije imaju zajedničko to što manipulišu originalnim podacima kako bi ometale pronalaženje pojedinaca. Primjeri su generalizacija, potiskivanje, brisanje, pseudonimizacija, maskiranje podataka i miješanje redova i stupaca. Primjere možete pronaći u donjoj tabeli.
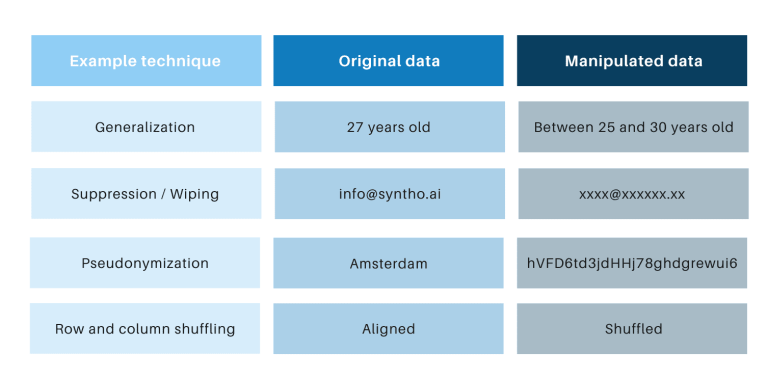
Ove tehnike uvode 3 ključna izazova:
- Oni rade različito po tipu podataka i po skupu podataka, što ih čini teškim za skaliranje. Nadalje, budući da rade drugačije, uvijek će se voditi debata o tome koje metode primijeniti i koja kombinacija tehnika je potrebna.
- Uvijek postoji odnos jedan-na-jedan s originalnim podacima. To znači da će uvijek postojati rizik privatnosti, posebno zbog svih otvorenih skupova podataka i dostupnih tehnika za povezivanje tih skupova podataka.
- Oni manipulišu podacima i na taj način uništavaju podatke u procesu. Ovo je posebno pogubno za AI zadatke u kojima je “predviđena moć” od suštinskog značaja, jer će podaci lošeg kvaliteta dovesti do loših uvida iz AI modela (Gurbage-in će rezultirati otpadom).
Ove tačke se također procjenjuju kroz ovu studiju slučaja.
Uvod u studiju slučaja
Za studiju slučaja, ciljni skup podataka bio je skup podataka o telekomunikacijama koji je obezbijedio SAS i koji sadrži podatke o 56.600 korisnika. Skup podataka sadrži 128 kolona, uključujući jednu kolonu koja pokazuje da li je kupac napustio kompaniju (tj. 'izbacio') ili ne. Cilj studije slučaja bio je korištenje sintetičkih podataka za obuku nekih modela za predviđanje odljeva kupaca i za procjenu učinka tih obučenih modela. Kako je predviđanje odljeva klasifikacijski zadatak, SAS je odabrao četiri popularna modela klasifikacije za predviđanja, uključujući:
- Slučajna šuma
- Pojačavanje gradijenta
- Logistička regresija
- Neuronska mreža
Prije generiranja sintetičkih podataka, SAS je nasumično podijelio telekomunikacioni skup podataka u skup vozova (za obuku modela) i skup za zadržavanje (za bodovanje modela). Posjedovanje zasebnog skupa zadržavanja za bodovanje omogućava nepristrasnu procjenu toga koliko dobro bi model klasifikacije mogao djelovati kada se primjenjuje na nove podatke.
Koristeći skup vlakova kao ulaz, Syntho je koristio svoj Syntho Engine za generiranje sintetičkog skupa podataka. Za benchmarking, SAS je takođe kreirao manipulisanu verziju skupa vozova nakon primene različitih tehnika anonimizacije da bi se dostigao određeni prag (k-anonimnosti). Prethodni koraci su rezultirali u četiri skupa podataka:
- Skup podataka o vlaku (tj. originalni skup podataka minus skup podataka o zadržavanju)
- Skup podataka za čekanje (tj. podskup originalnog skupa podataka)
- Anonimizirani skup podataka (zasnovano na skupu podataka o vozu)
- Sintetički skup podataka (baziran na skupu podataka o vlaku)
Skupovi podataka 1, 3 i 4 korišteni su za obuku svakog modela klasifikacije, što je rezultiralo sa 12 (3 x 4) obučenih modela. SAS je kasnije koristio skup podataka o zadržavanju da izmjeri tačnost s kojom svaki model predviđa odljev kupaca. Rezultati su predstavljeni u nastavku, počevši od nekih osnovnih statistika.
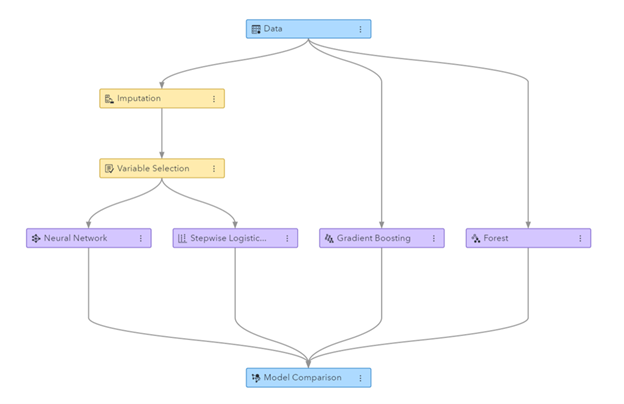
Slika: Cjevovod strojnog učenja generiran u SAS Visual Data Mining i Machine Learning
Osnovna statistika prilikom poređenja anonimiziranih podataka sa originalnim podacima
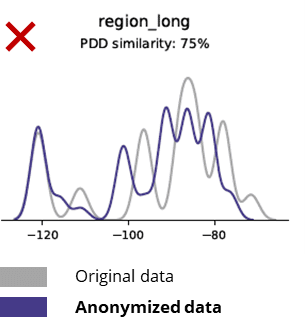
Tehnike anonimizacije uništavaju čak i osnovne obrasce, poslovnu logiku, odnose i statistiku (kao u primjeru ispod). Korištenje anonimiziranih podataka za osnovnu analitiku tako daje nepouzdane rezultate. U stvari, loš kvalitet anonimiziranih podataka učinio je gotovo nemogućim njihovo korištenje za napredne analitičke zadatke (npr. AI/ML modeliranje i nadzorne ploče).
Osnovna statistika pri poređenju sintetičkih podataka sa originalnim podacima
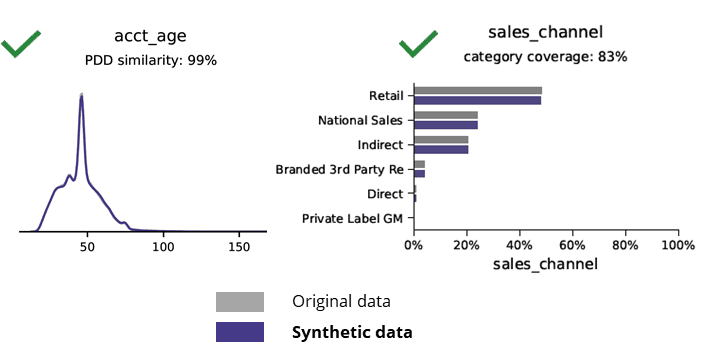
Sintetičko generiranje podataka pomoću AI čuva osnovne obrasce, poslovnu logiku, odnose i statistiku (kao u primjeru ispod). Korištenje sintetičkih podataka za osnovnu analitiku tako daje pouzdane rezultate. Ključno pitanje, da li sintetički podaci vrijede za napredne analitičke zadatke (npr. AI/ML modeliranje i nadzorne ploče)?
Sintetički podaci generirani umjetnom inteligencijom i napredna analitika
Sintetički podaci ne vrijede samo za osnovne obrasce (kao što je prikazano na prethodnim dijagramima), oni također hvataju duboke 'skrivene' statističke obrasce potrebne za napredne analitičke zadatke. Potonje je prikazano na stupčastom grafikonu ispod, što ukazuje da je tačnost modela obučenih na sintetičkim podacima u odnosu na modele obučene na originalnim podacima slična. Nadalje, sa površinom ispod krive (AUC*) blizu 0.5, modeli obučeni na anonimiziranim podacima imaju daleko najgore rezultate. Potpuni izvještaj sa svim naprednim analitičkim procjenama o sintetičkim podacima u poređenju sa originalnim podacima dostupan je na zahtjev.
*AUC: površina ispod krive je mjera za tačnost modela napredne analize, uzimajući u obzir istinite pozitivne, lažno pozitivne, lažno negativne i prave negativne. 0,5 znači da model predviđa nasumično i da nema prediktivnu moć, a 1 znači da je model uvijek ispravan i da ima punu prediktivnu moć.
Dodatno, ovi sintetički podaci se mogu koristiti za razumijevanje karakteristika podataka i glavnih varijabli potrebnih za stvarnu obuku modela. Unosi odabrani algoritmima na sintetičkim podacima u poređenju sa originalnim podacima bili su vrlo slični. Dakle, proces modeliranja se može obaviti na ovoj sintetičkoj verziji, što smanjuje rizik od kršenja podataka. Međutim, kada se izvode zaključke o pojedinačnim zapisima (npr. telefonski korisnik) preporučuje se ponovna obuka na originalnim podacima radi objašnjenja, većeg prihvatanja ili samo zbog regulative.
AUC prema algoritmu grupiranom po metodi
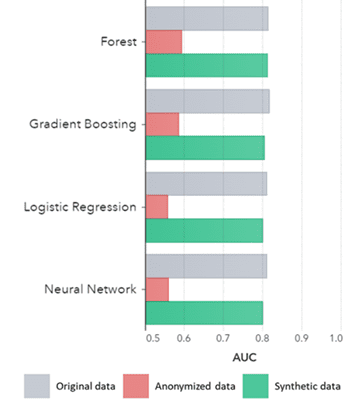
Zaključci:
- Modeli obučeni na sintetičkim podacima u poređenju sa modelima obučenim na originalnim podacima pokazuju vrlo slične performanse
- Modeli obučeni na anonimiziranim podacima s 'klasičnim tehnikama anonimizacije' pokazuju lošije performanse u usporedbi s modelima obučenim na originalnim ili sintetičkim podacima
- Generisanje sintetičkih podataka je jednostavno i brzo jer tehnika radi potpuno isto po skupu podataka i tipu podataka.
Slučajevi korištenja sintetičkih podataka koji dodaju vrijednost
Slučaj upotrebe 1: Sintetički podaci za razvoj modela i naprednu analitiku
Imati jaku osnovu podataka sa lakim i brzim pristupom upotrebljivim, visokokvalitetnim podacima je od suštinskog značaja za razvoj modela (npr. kontrolne table [BI] i napredna analitika [AI & ML]). Međutim, mnoge organizacije pate od neoptimalne baze podataka što rezultira 3 ključna izazova:
- Pristup podacima traje godinama zbog propisa o privatnosti, internih procesa ili skladišta podataka
- Klasične tehnike anonimizacije uništavaju podatke, čineći podatke više neprikladnim za analizu i naprednu analitiku (smeće ulazi = smeće izlazi)
- Postojeća rješenja nisu skalabilna jer rade različito po skupu podataka i tipu podataka i ne mogu rukovati velikim bazama podataka s više tablica
Pristup sintetičkim podacima: razviti modele s jednako dobrim kao i stvarnim sintetičkim podacima za:
- Smanjite upotrebu izvornih podataka bez ometanja programera
- Otključajte lične podatke i imajte pristup više podataka koji su prethodno bili ograničeni (npr. Zbog privatnosti)
- Lak i brz pristup relevantnim podacima
- Skalabilno rješenje koje radi isto za svaki skup podataka, tip podataka i za velike baze podataka
Ovo omogućava organizaciji da izgradi jaku osnovu podataka sa lakim i brzim pristupom upotrebljivim, visokokvalitetnim podacima za otključavanje podataka i iskorištavanje mogućnosti podataka.
Slučaj upotrebe 2: pametni sintetički testni podaci za testiranje, razvoj i isporuku softvera
Testiranje i razvoj sa visokokvalitetnim testnim podacima su neophodni za isporuku najsavremenijih softverskih rješenja. Korištenje originalnih proizvodnih podataka izgleda očigledno, ali nije dozvoljeno zbog (privatnosti) propisa. Alternativa Test Data Management (TDM) alati uvode “legacy-by-design” da dobijete ispravne podatke testa:
- Ne odražavaju proizvodne podatke i poslovna logika i referentni integritet nisu sačuvani
- Radite sporo i dugotrajno
- Potreban je ručni rad
Pristup sintetičkim podacima: Testirajte i razvijajte sa sintetičkim testnim podacima generiranim od umjetne inteligencije kako biste isporučili najmodernija softverska rješenja pametna sa:
- Podaci slični proizvodnji sa očuvanom poslovnom logikom i referentnim integritetom
- Lako i brzo generiranje podataka pomoću vrhunske umjetne inteligencije
- Privatnost po dizajnu
- Lako, brzo i agile
Ovo omogućava organizaciji da testira i razvija sa testnim podacima sledećeg nivoa kako bi isporučila najsavremenija softverska rešenja!
Više informacija
Zainteresovani? Za više informacija o sintetičkim podacima, posjetite Syntho web stranicu ili kontaktirajte Wim Kees Janssen. Za više informacija o SAS-u, posjetite www.sas.com ili kontaktirajte kees@syntho.ai.
U ovom slučaju upotrebe, Syntho, SAS i NL AIC rade zajedno kako bi postigli željene rezultate. Syntho je stručnjak za sintetičke podatke generirane umjetnom inteligencijom, a SAS je tržišni lider u analitici i nudi softver za istraživanje, analizu i vizualizaciju podataka.
* Predviđa 2021. – Strategije podataka i analitike za upravljanje, skaliranje i transformaciju digitalnog poslovanja, Gartner, 2020.

Sačuvajte svoj vodič za sintetičke podatke sada!
- Šta su sintetički podaci?
- Zašto ga organizacije koriste?
- Klijentski slučajevi sa sintetičkim podacima koji dodaju vrijednost
- Kako započeti
