Pogodi ko? 5 primjera zašto uklanjanje imena nije opcija



Pogodi ko? Iako sam siguran da većina vas poznaje ovu igru od davnina, evo kratkog rezimea. Cilj igre: otkrijte ime lika iz crtića koji je odabrao vaš protivnik postavljanjem pitanja "da" i "ne", poput "nosi li osoba šešir?" ili 'nosi li naočare'? Igrači eliminišu kandidate na osnovu odgovora protivnika i uče atribute koji se odnose na misteriozni karakter njihovog protivnika. Prvi igrač koji otkrije misteriozni lik drugog igrača pobjeđuje u igri.
U redu. Morate identificirati pojedinca iz skupa podataka tako što ćete imati pristup samo odgovarajućim atributima. Zapravo, redovito viđamo ovaj koncept „Pogodi tko“ koji se primjenjivao u praksi, ali se potom koristio na skupovima podataka formatiranim redovima i stupcima koji sadrže atribute stvarnih ljudi. Glavna razlika u radu s podacima je u tome što ljudi imaju tendenciju potcjenjivati lakoću kojom se stvarni pojedinci mogu razotkriti imajući pristup samo nekoliko atributa.
Kao što igra Pogodi ko prikazuje, neko može identifikovati pojedince tako što ima pristup samo nekoliko atributa. Služi kao jednostavan primjer zašto uklanjanje samo 'imena' (ili drugih direktnih identifikatora) iz vašeg skupa podataka ne uspijeva kao tehnika anonimizacije. Na ovom blogu pružamo četiri praktična slučaja kako bismo vas informirali o rizicima privatnosti povezanim s uklanjanjem stupaca kao načinom anonimizacije podataka.
Rizik od napada povezivanjem najvažniji je razlog zašto samo uklanjanje imena ne funkcionira (više) kao metoda za anonimizaciju. Napadom povezivanja napadač kombinira izvorne podatke s drugim pristupačnim izvorima podataka kako bi jedinstveno identificirao pojedinca i naučio (često osjetljive) podatke o toj osobi.
Ključno ovdje je dostupnost drugih izvora podataka koji su sada prisutni ili bi mogli postati prisutni u budućnosti. Mislite na sebe. Koliko se vaših osobnih podataka može pronaći na Facebooku, Instagramu ili LinkedInu koji bi se potencijalno mogli zloupotrijebiti za napad povezivanjem?
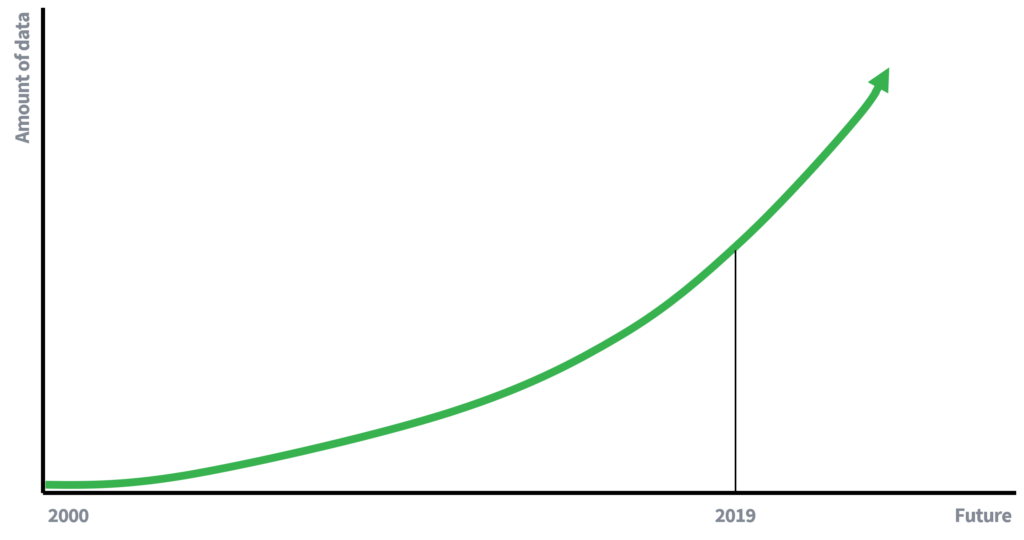
Ranijih dana dostupnost podataka bila je znatno ograničenija, što djelomično objašnjava zašto je uklanjanje imena bilo dovoljno za očuvanje privatnosti pojedinaca. Manje dostupnih podataka znači manje mogućnosti za povezivanje podataka. Međutim, sada smo (aktivni) sudionici u ekonomiji vođenoj podacima, gdje količina podataka raste eksponencijalnom brzinom. Više podataka i poboljšana tehnologija za prikupljanje podataka dovest će do povećanog potencijala za napade na povezivanje. Što bi se pisalo za 10 godina o opasnosti od napada povezivanjem?
Ilustracija 1
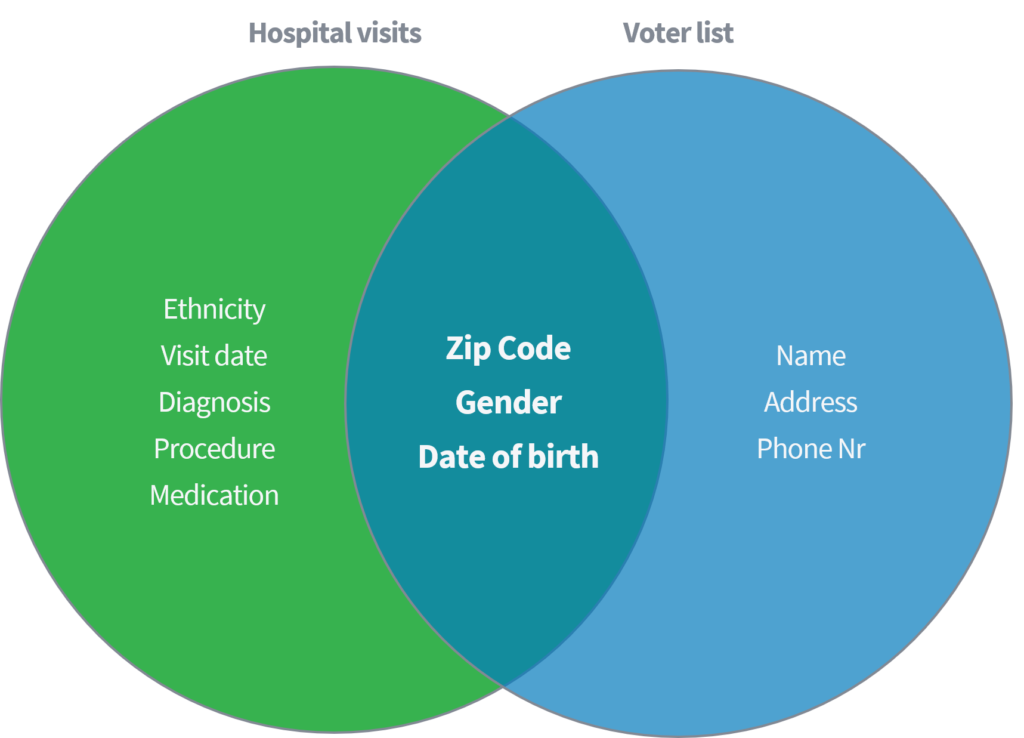
Sweeney (2002) je u jednom akademskom radu pokazala kako je uspjela identificirati i dohvatiti osjetljive medicinske podatke od pojedinaca na osnovu povezivanja javno dostupnog skupa podataka o „bolničkim posjetima“ s javno dostupnim matičnim zapisnikom u Sjedinjenim Državama. Za oba skupa podataka se pretpostavlja da su ispravno anonimizirani brisanjem imena i drugih direktnih identifikatora.
Ilustracija 2
Na temelju samo tri parametra (1) poštanski broj, (2) spol i (3) datum rođenja, pokazala je da se 87% ukupne populacije SAD-a može ponovno identificirati podudaranjem gore navedenih atributa iz oba skupa podataka. Sweeney je zatim ponovila svoj rad sa "državom" kao zamjenom za "poštanski broj". Osim toga, pokazala je da se 18% ukupne populacije SAD -a može identificirati samo ako ima pristup skupu podataka koji sadrži podatke o (1) matičnoj zemlji, (2) spolu i (3) datumu rođenja. Razmislite o gore spomenutim javnim izvorima, poput Facebooka, LinkedIna ili Instagrama. Jesu li vaša zemlja, spol i datum rođenja vidljivi ili drugi korisnici to mogu odbiti?
Ilustracija 3
| Kvazi identifikatori | % jedinstveno identificiranih američkih stanovnika (248 miliona) |
| Petocifreni poštanski broj, pol, datum rođenja | 87% |
| mjesto, spol, datum rođenja | 53% |
| zemlja, spol, datum rođenja | 18% |
Ovaj primjer pokazuje da može biti izuzetno lako deanonimizirati pojedince u naizgled anonimnim podacima. Prvo, ovo istraživanje ukazuje na ogromnu veličinu rizika, kao što je 87% američkog stanovništva može se lako identificirati pomoću nekoliko karakteristika. Drugo, izloženi medicinski podaci u ovoj studiji bili su vrlo osjetljivi. Primjeri podataka izloženih pojedinaca iz skupa podataka o posjetama bolnici uključuju etničku pripadnost, dijagnozu i lijekove. Svojstva koja se radije mogu držati u tajnosti, na primjer, od osiguravajućih kompanija.
Drugi rizik uklanjanja samo direktnih identifikatora, poput imena, javlja se kada informirani pojedinci imaju superiorno znanje ili informacije o osobinama ili ponašanju određenih pojedinaca u skupu podataka. Na osnovu njihovog znanja, napadač bi tada mogao biti u mogućnosti povezati specifične podatke sa stvarnim ljudima.
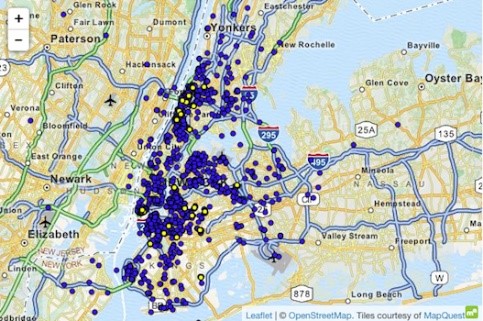
Primjer napada na skup podataka koristeći vrhunsko znanje je slučaj taksija u New Yorku, gdje je Atockar (2014) uspio razotkriti određene pojedince. Zaposleni skup podataka sadržavao je sva putovanja taksijem u New Yorku, obogaćen osnovnim atributima poput koordinata početka, krajnjih koordinata, cijene i vrha vožnje.
Upućeni pojedinac koji zna da je New York uspio izvesti taksi u klub za odrasle 'Hustler'. Filtrirajući "krajnju lokaciju", on je izveo tačne početne adrese i tako identificirao različite česte posjetitelje. Slično, može se zaključiti vožnja taksijem kada je poznata kućna adresa pojedinca. Vrijeme i lokacija nekoliko poznatih filmskih zvijezda otkriveni su na trač stranicama. Nakon povezivanja ovih podataka s podacima taksija u New Yorku, bilo je lako izvesti njihove vožnje taksijem, iznos koji su platili i jesu li dali napojnicu.
Ilustracija 4
izlazne koordinate Hustler
Bradley Cooper
jessica Alba
Uobičajena argumentacija je „ovi podaci su bezvrijedni“ ili „niko ne može ništa učiniti s tim podacima“. Ovo je često pogrešno mišljenje. Čak i najnevinji podaci mogu formirati jedinstveni „otisak prsta“ i koristiti se za ponovnu identifikaciju pojedinaca. To je rizik proizašao iz vjerovanja da su sami podaci bezvrijedni, a nisu.
Rizik identifikacije će se povećati sa povećanjem podataka, umjetne inteligencije i drugih alata i algoritama koji omogućuju otkrivanje složenih odnosa u podacima. Slijedom toga, čak i ako se vaš skup podataka ne može otkriti sada, a vjerojatno je beskoristan za neovlaštene osobe danas, to možda neće biti sutra.
Sjajan primjer je slučaj u kojem je Netflix namjeravao okupiti svoje odjele za istraživanje i razvoj uvođenjem otvorenog Netflixovog natjecanja za poboljšanje svog sistema preporuka filmova. 'Onaj koji poboljša kolaborativni algoritam filtriranja kako bi predvidio ocjene korisnika za filmove osvaja nagradu od 1,000,000 USD'. Kako bi podržao publiku, Netflix je objavio skup podataka koji sadrži samo sljedeće osnovne atribute: korisnički ID, film, datum ocjene i ocjene (tako da nema dodatnih informacija o korisniku ili samom filmu).
Ilustracija 5
| Korisnički broj | film | Datum ocjene | razred |
| 123456789 | Misija je nemoguća | 10-12-2008 | 4 |
Izolovano, podaci su izgledali uzaludni. Na pitanje 'Ima li podataka o korisniku u skupu podataka koje treba držati privatnima?', Odgovor je bio:
'Ne, svi podaci za identifikaciju korisnika su uklonjeni; preostaju samo ocjene i datumi. Ovo slijedi našu politiku privatnosti ... '
Međutim, Narayanan (2008) sa Univerziteta Texas u Austinu pokazao je suprotno. Kombinacija ocjena, datuma ocjene i filma pojedinca čini jedinstveni otisak prsta filma. Razmislite o svom ponašanju na Netflixu. Šta mislite, koliko je ljudi gledalo istu seriju filmova? Koliko je gledalo isti set filmova u isto vrijeme?
Glavno pitanje, kako uskladiti ovaj otisak prsta? Bilo je prilično jednostavno. Na osnovu informacija sa poznate web stranice za ocjenjivanje filmova IMDb (Internet Movie Database), mogao bi se formirati sličan otisak prsta. Posljedično, pojedinci bi se mogli ponovno identificirati.
Iako se ponašanje pri gledanju filmova ne može smatrati osjetljivom informacijom, razmislite o svom ponašanju-bi li vam smetalo da to postane javno? Primjeri koje je Narayanan naveo u svom radu su političke preferencije (ocjene o 'Isusu iz Nazareta' i 'Evanđelju po Ivanu') i seksualne preferencije (ocjene o 'Bent' i 'Queer as folk') koje se lako mogu destilirati.
GDPR možda nije super uzbudljiv, niti srebro među temama bloga. Ipak, korisno je razjasniti definicije prilikom obrade ličnih podataka. Budući da se ovaj blog bavi uobičajenim zabludama o uklanjanju stupaca kao načinu anonimizacije podataka i obrazovanju vas kao obrađivača podataka, počnimo s istraživanjem definicije anonimizacije prema GDPR -u.
Prema uvodnoj izjavi 26. GDPR -a, anonimni podaci definirani su kao:
„informacije koje se ne odnose na identificiranu ili identifikacijsku fizičku osobu ili lični podaci anonimni na takav način da se subjekt podataka ne može ili više ne može identificirati.“
Budući da se obrađuju lični podaci koji se odnose na fizičko lice, relevantan je samo drugi dio definicije. Kako bi se ispoštovala definicija, potrebno je osigurati da se subjekt podataka (pojedinac) ne može ili više ne može identificirati. Kako je naznačeno u ovom blogu, međutim, izuzetno je jednostavno identificirati pojedince na osnovu nekoliko atributa. Dakle, uklanjanje imena iz skupa podataka nije u skladu sa GDPR definicijom anonimizacije.
Osporili smo jedan često razmatrani i, nažalost, još uvijek često primjenjivan pristup anonimizacije podataka: uklanjanje imena. U igri Pogodi tko i četiri druga primjera o:
pokazalo se da uklanjanje imena ne uspijeva kao anonimizacija. Iako su primjeri upečatljivi slučajevi, svaki pokazuje jednostavnost ponovne identifikacije i potencijalni negativan uticaj na privatnost pojedinaca.
Zaključno, uklanjanje imena iz vašeg skupa podataka ne rezultira anonimnim podacima. Stoga je bolje da izbjegavamo korištenje oba pojma naizmjenično. Iskreno se nadam da nećete primijeniti ovaj pristup za anonimizaciju. I, ako to i dalje činite, pobrinite se da vi i vaš tim u potpunosti razumijete rizike privatnosti i da li vam je dopušteno prihvatiti te rizike u ime pogođenih pojedinaca.
Kontaktirajte Syntho i jedan od naših stručnjaka će vas kontaktirati brzinom svjetlosti kako bi istražio vrijednost sintetičkih podataka!