

El informe de control de calidad de Syntho evalúa los datos sintéticos generados y demuestra la precisión, privacidad y velocidad de los datos sintéticos en comparación con los datos originales.
En Syntho, entendemos la importancia de datos sintéticos confiables y precisos. Es por eso que proporcionamos un informe completo de garantía de calidad para cada ejecución de datos sintéticos. Nuestro informe de calidad incluye varias métricas como distribuciones, correlaciones, distribuciones multivariadas, métricas de privacidad y más. De esta manera, podrá evaluar fácilmente que los datos sintéticos que proporcionamos son de la más alta calidad y pueden usarse con el mismo nivel de precisión y confiabilidad que sus datos originales.
Echando un vistazo: esta sección ilustra los aspectos más destacados de nuestro informe de calidad de datos sintéticos. Nuestras evaluaciones examinan los datos sintéticos en comparación con los datos reales en varias dimensiones.
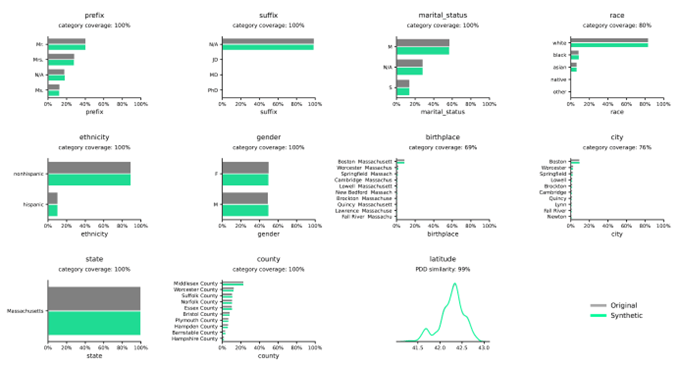
Distribuciones de datos sintéticos en comparación con datos reales
Las distribuciones ilustran la frecuencia de las variables dentro de categorías o valores determinados y Syntho Engine las captura con precisión.
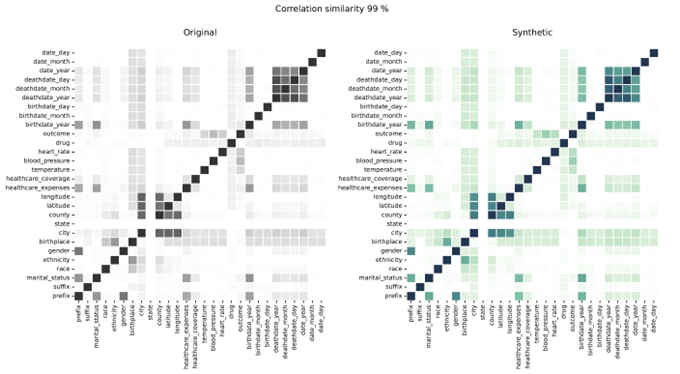
Correlaciones de datos sintéticos en comparación con datos reales
Las correlaciones muestran la relación entre variables, ilustrando el grado en que las variables están relacionadas. Syntho Engine captura con precisión estas relaciones.
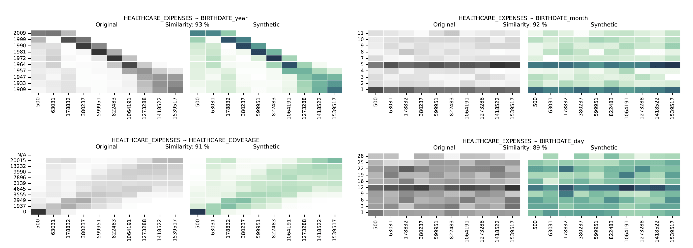
Distribuciones multivariadas de datos sintéticos en comparación con datos reales
Las distribuciones multivariadas y las correlaciones multivariadas nos llevan más allá de las dimensiones singulares y nos brindan una visión integral de cómo se relacionan múltiples variables. Syntho Engine captura estas relaciones.
La generación de datos sintéticos es compleja y existen dificultades que es necesario controlar. Con los algoritmos de IA, el sobreajuste es un riesgo y este también es el caso de la generación de datos sintéticos con IA. Por lo tanto, se debe controlar el riesgo de sobreajuste al generar datos sintéticos. El riesgo de sobreajuste se controla en Syntho Engine. Además de eso, el informe de Garantía de calidad (QA) de Syntho permite a las organizaciones demostrar que los datos sintéticos no se ajustan demasiado a los datos originales. También evaluamos aspectos más relacionados con la privacidad, que suelen utilizar los auditores internos.
Prueba de “coincidencias exactas” con el índice de coincidencia idéntica (IMR)
Demostración de que la proporción de registros de datos sintéticos que coinciden con un registro real de los datos originales no es significativamente mayor que la proporción que se puede esperar al analizar los datos del tren.
Prueba en “Partidos similares” con la distancia al registro más cercano (DCR)
Demostración de que la distancia normalizada para los registros de datos sintéticos hasta su registro real más cercano dentro de los datos originales no es significativamente menor que la distancia que se puede esperar al analizar los datos del tren.
Prueba en “Valores atípicos” con el Relación de distancia del vecino más cercano (NNDR)
Demostración de que la relación de distancia entre el registro sintético más cercano y el segundo más cercano a su registro más cercano dentro de los datos originales no es significativamente más cercana que la relación que se esperaría para los datos del tren.
Esta es solo una instantánea que resume la esencia de nuestro informe de control de calidad y exploración de la calidad de los datos sintéticos. Ofrece una comprensión matizada de distribuciones, correlaciones y distribuciones multivariadas como parte de datos sintéticos capturados por las capacidades avanzadas de Syntho Engine. Más detalles sobre nuestro informe de control de calidad están disponibles previa solicitud.