


SAS ನ ದತ್ತಾಂಶ ತಜ್ಞರಿಂದ ಬಾಹ್ಯ ಮತ್ತು ವಸ್ತುನಿಷ್ಠ ದೃಷ್ಟಿಕೋನದಿಂದ ಸಿಂಥೋ ಮೂಲಕ ರಚಿಸಲಾದ ಸಂಶ್ಲೇಷಿತ ಡೇಟಾವನ್ನು ಮೌಲ್ಯಮಾಪನ ಮಾಡಲಾಗುತ್ತದೆ, ಮೌಲ್ಯೀಕರಿಸಲಾಗುತ್ತದೆ ಮತ್ತು ಅನುಮೋದಿಸಲಾಗುತ್ತದೆ.
ಸಿಂಥೋ ತನ್ನ ಬಳಕೆದಾರರಿಗೆ ಸುಧಾರಿತ ಗುಣಮಟ್ಟದ ಭರವಸೆಯ ವರದಿಯನ್ನು ನೀಡಲು ಹೆಮ್ಮೆಪಡುತ್ತದೆಯಾದರೂ, ಉದ್ಯಮದ ಪ್ರಮುಖರಿಂದ ನಮ್ಮ ಸಂಶ್ಲೇಷಿತ ಡೇಟಾದ ಬಾಹ್ಯ ಮತ್ತು ವಸ್ತುನಿಷ್ಠ ಮೌಲ್ಯಮಾಪನವನ್ನು ಹೊಂದುವ ಪ್ರಾಮುಖ್ಯತೆಯನ್ನು ನಾವು ಅರ್ಥಮಾಡಿಕೊಳ್ಳುತ್ತೇವೆ. ಅದಕ್ಕಾಗಿಯೇ ನಾವು ನಮ್ಮ ಸಿಂಥೆಟಿಕ್ ಡೇಟಾವನ್ನು ನಿರ್ಣಯಿಸಲು ವಿಶ್ಲೇಷಣೆಯಲ್ಲಿ ಮುಂಚೂಣಿಯಲ್ಲಿರುವ SAS ನೊಂದಿಗೆ ಸಹಕರಿಸುತ್ತೇವೆ.
ಮೂಲ ದತ್ತಾಂಶಕ್ಕೆ ಹೋಲಿಸಿದರೆ SAS ಡೇಟಾ-ನಿಖರತೆ, ಗೌಪ್ಯತೆ ರಕ್ಷಣೆ ಮತ್ತು ಸಿಂಥೋನ AI- ರಚಿತ ಸಿಂಥೆಟಿಕ್ ಡೇಟಾದ ಉಪಯುಕ್ತತೆಯ ಮೇಲೆ ವಿವಿಧ ಸಂಪೂರ್ಣ ಮೌಲ್ಯಮಾಪನಗಳನ್ನು ನಡೆಸುತ್ತದೆ. ತೀರ್ಮಾನದಂತೆ, SAS ಸಿಂಥೋನ ಸಂಶ್ಲೇಷಿತ ಡೇಟಾವನ್ನು ನಿಖರ, ಸುರಕ್ಷಿತ ಮತ್ತು ಮೂಲ ದತ್ತಾಂಶಕ್ಕೆ ಹೋಲಿಸಿದರೆ ಬಳಸಬಹುದಾಗಿದೆ ಎಂದು ಮೌಲ್ಯಮಾಪನ ಮಾಡಿದೆ ಮತ್ತು ಅನುಮೋದಿಸಿದೆ.
ನಾವು ಟೆಲಿಕಾಂ ಡೇಟಾವನ್ನು "ಚರ್ನ್" ಭವಿಷ್ಯಕ್ಕಾಗಿ ಟಾರ್ಗೆಟ್ ಡೇಟಾವಾಗಿ ಬಳಸಿದ್ದೇವೆ. ಮೌಲ್ಯಮಾಪನದ ಗುರಿಯು ವಿವಿಧ ಮಂಥನ ಭವಿಷ್ಯ ಮಾದರಿಗಳನ್ನು ತರಬೇತಿ ಮಾಡಲು ಮತ್ತು ಪ್ರತಿ ಮಾದರಿಯ ಕಾರ್ಯಕ್ಷಮತೆಯನ್ನು ನಿರ್ಣಯಿಸಲು ಸಂಶ್ಲೇಷಿತ ಡೇಟಾವನ್ನು ಬಳಸುವುದು. ಮಂಥನ ಭವಿಷ್ಯವು ಒಂದು ವರ್ಗೀಕರಣ ಕಾರ್ಯವಾಗಿರುವುದರಿಂದ, SAS ಮುನ್ನೋಟಗಳನ್ನು ಮಾಡಲು ಜನಪ್ರಿಯ ವರ್ಗೀಕರಣ ಮಾದರಿಗಳನ್ನು ಆಯ್ಕೆಮಾಡಿದೆ, ಅವುಗಳೆಂದರೆ:
ಸಿಂಥೆಟಿಕ್ ಡೇಟಾವನ್ನು ರಚಿಸುವ ಮೊದಲು, SAS ಯಾದೃಚ್ಛಿಕವಾಗಿ ಟೆಲಿಕಾಂ ಡೇಟಾಸೆಟ್ ಅನ್ನು ರೈಲು ಸೆಟ್ (ಮಾದರಿಗಳಿಗೆ ತರಬೇತಿ ನೀಡಲು) ಮತ್ತು ಹೋಲ್ಡ್ ಔಟ್ ಸೆಟ್ (ಮಾದರಿಗಳನ್ನು ಸ್ಕೋರ್ ಮಾಡಲು) ಆಗಿ ವಿಭಜಿಸುತ್ತದೆ. ಹೊಸ ದತ್ತಾಂಶಕ್ಕೆ ಅನ್ವಯಿಸಿದಾಗ ವರ್ಗೀಕರಣ ಮಾದರಿಯು ಎಷ್ಟು ಉತ್ತಮವಾಗಿ ಕಾರ್ಯನಿರ್ವಹಿಸುತ್ತದೆ ಎಂಬುದರ ಬಗ್ಗೆ ಪಕ್ಷಪಾತವಿಲ್ಲದ ಮೌಲ್ಯಮಾಪನಕ್ಕೆ ಸ್ಕೋರಿಂಗ್ಗಾಗಿ ಪ್ರತ್ಯೇಕ ಹಿಡಿತವನ್ನು ಹೊಂದಿಸುವುದು ಅನುಮತಿಸುತ್ತದೆ.
ರೈಲು ಸೆಟ್ ಅನ್ನು ಇನ್ಪುಟ್ ಆಗಿ ಬಳಸಿಕೊಂಡು, ಸಿಂಥೋ ತನ್ನ ಸಿಂಥೋ ಎಂಜಿನ್ ಅನ್ನು ಸಿಂಥೆಟಿಕ್ ಡೇಟಾಸೆಟ್ ಅನ್ನು ಉತ್ಪಾದಿಸಲು ಬಳಸಿತು. ಬೆಂಚ್ಮಾರ್ಕಿಂಗ್ಗಾಗಿ, ಒಂದು ನಿರ್ದಿಷ್ಟ ಮಿತಿಯನ್ನು ತಲುಪಲು (ಕೆ-ಅನಾಮಧೇಯತೆಯ) ವಿವಿಧ ಅನಾಮಧೇಯತೆಯ ತಂತ್ರಗಳನ್ನು ಅನ್ವಯಿಸಿದ ನಂತರ SAS ರೈಲು ಸೆಟ್ನ ಅನಾಮಧೇಯ ಆವೃತ್ತಿಯನ್ನು ಸಹ ರಚಿಸಿದೆ. ಹಿಂದಿನ ಹಂತಗಳು ನಾಲ್ಕು ಡೇಟಾಸೆಟ್ಗಳಾಗಿ ಪರಿಣಮಿಸಿದವು:
ಡೇಟಾಸೆಟ್ಗಳು 1, 3 ಮತ್ತು 4 ಅನ್ನು ಪ್ರತಿ ವರ್ಗೀಕರಣ ಮಾದರಿಯನ್ನು ತರಬೇತಿ ಮಾಡಲು ಬಳಸಲಾಯಿತು, ಇದರ ಪರಿಣಾಮವಾಗಿ 12 (3 x 4) ತರಬೇತಿ ಪಡೆದ ಮಾದರಿಗಳು. ಗ್ರಾಹಕರ ಮಂಥನದ ಮುನ್ಸೂಚನೆಯಲ್ಲಿ ಪ್ರತಿ ಮಾದರಿಯ ನಿಖರತೆಯನ್ನು ಅಳೆಯಲು SAS ತರುವಾಯ ತಡೆಹಿಡಿಯುವ ಡೇಟಾಸೆಟ್ ಅನ್ನು ಬಳಸಿತು.
ಮೂಲ ದತ್ತಾಂಶಕ್ಕೆ ಹೋಲಿಸಿದರೆ SAS ಡೇಟಾ-ನಿಖರತೆ, ಗೌಪ್ಯತೆ ರಕ್ಷಣೆ ಮತ್ತು ಸಿಂಥೋನ AI- ರಚಿತ ಸಿಂಥೆಟಿಕ್ ಡೇಟಾದ ಉಪಯುಕ್ತತೆಯ ಮೇಲೆ ವಿವಿಧ ಸಂಪೂರ್ಣ ಮೌಲ್ಯಮಾಪನಗಳನ್ನು ನಡೆಸುತ್ತದೆ. ತೀರ್ಮಾನದಂತೆ, SAS ಸಿಂಥೋನ ಸಂಶ್ಲೇಷಿತ ಡೇಟಾವನ್ನು ನಿಖರ, ಸುರಕ್ಷಿತ ಮತ್ತು ಮೂಲ ದತ್ತಾಂಶಕ್ಕೆ ಹೋಲಿಸಿದರೆ ಬಳಸಬಹುದಾಗಿದೆ ಎಂದು ಮೌಲ್ಯಮಾಪನ ಮಾಡಿದೆ ಮತ್ತು ಅನುಮೋದಿಸಿದೆ.
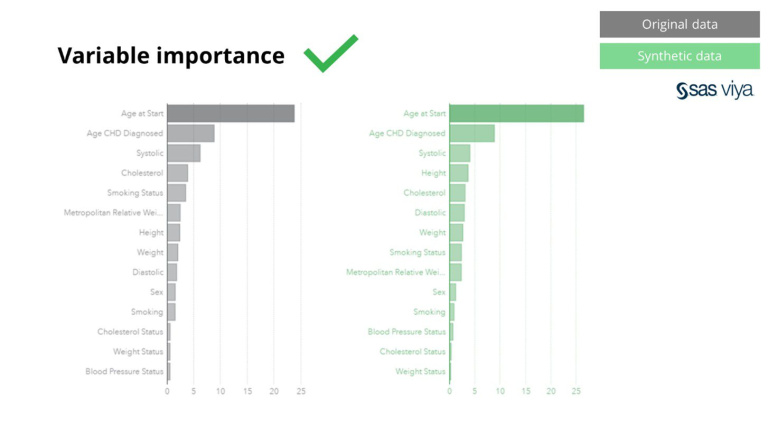
ಸಿಂಥೋದಿಂದ ಸಂಶ್ಲೇಷಿತ ಡೇಟಾವು ಮೂಲ ಮಾದರಿಗಳಿಗೆ ಮಾತ್ರವಲ್ಲದೆ, ಸುಧಾರಿತ ವಿಶ್ಲೇಷಣಾ ಕಾರ್ಯಗಳಿಗೆ ಅಗತ್ಯವಿರುವ ಆಳವಾದ 'ಗುಪ್ತ' ಅಂಕಿಅಂಶಗಳ ಮಾದರಿಗಳನ್ನು ಸಹ ಸೆರೆಹಿಡಿಯುತ್ತದೆ. ಎರಡನೆಯದನ್ನು ಬಾರ್ ಚಾರ್ಟ್ನಲ್ಲಿ ಪ್ರದರ್ಶಿಸಲಾಗಿದೆ, ಇದು ಸಿಂಥೆಟಿಕ್ ಡೇಟಾದ ಮೇಲೆ ತರಬೇತಿ ಪಡೆದ ಮಾದರಿಗಳ ನಿಖರತೆ ಮತ್ತು ಮೂಲ ಡೇಟಾದ ಮೇಲೆ ತರಬೇತಿ ಪಡೆದ ಮಾದರಿಗಳಂತೆಯೇ ಇರುತ್ತದೆ ಎಂದು ಸೂಚಿಸುತ್ತದೆ. ಆದ್ದರಿಂದ, ಮಾದರಿಗಳ ನಿಜವಾದ ತರಬೇತಿಗಾಗಿ ಸಂಶ್ಲೇಷಿತ ಡೇಟಾವನ್ನು ಬಳಸಬಹುದು. ಮೂಲ ಡೇಟಾಗೆ ಹೋಲಿಸಿದರೆ ಸಿಂಥೆಟಿಕ್ ಡೇಟಾದ ಅಲ್ಗಾರಿದಮ್ಗಳಿಂದ ಆಯ್ಕೆ ಮಾಡಲಾದ ಇನ್ಪುಟ್ಗಳು ಮತ್ತು ವೇರಿಯಬಲ್ ಪ್ರಾಮುಖ್ಯತೆಯು ತುಂಬಾ ಹೋಲುತ್ತದೆ. ಆದ್ದರಿಂದ, ನೈಜ ಸೂಕ್ಷ್ಮ ಡೇಟಾವನ್ನು ಬಳಸುವುದಕ್ಕೆ ಪರ್ಯಾಯವಾಗಿ ಸಿಂಥೆಟಿಕ್ ಡೇಟಾದಲ್ಲಿ ಮಾಡೆಲಿಂಗ್ ಪ್ರಕ್ರಿಯೆಯನ್ನು ಮಾಡಬಹುದು ಎಂದು ತೀರ್ಮಾನಿಸಲಾಗಿದೆ.
ಕ್ಲಾಸಿಕ್ ಅನಾಮಧೇಯತೆಯ ತಂತ್ರಗಳು ಸಾಮಾನ್ಯವಾಗಿ ವ್ಯಕ್ತಿಗಳನ್ನು ಪತ್ತೆಹಚ್ಚಲು ಅಡ್ಡಿಯಾಗುವಂತೆ ಮೂಲ ಡೇಟಾವನ್ನು ಕುಶಲತೆಯಿಂದ ನಿರ್ವಹಿಸುತ್ತವೆ. ಅವರು ಡೇಟಾವನ್ನು ಕುಶಲತೆಯಿಂದ ನಿರ್ವಹಿಸುತ್ತಾರೆ ಮತ್ತು ಆ ಮೂಲಕ ಪ್ರಕ್ರಿಯೆಯಲ್ಲಿ ಡೇಟಾವನ್ನು ನಾಶಪಡಿಸುತ್ತಾರೆ. ನೀವು ಹೆಚ್ಚು ಅನಾಮಧೇಯಗೊಳಿಸಿದರೆ, ನಿಮ್ಮ ಡೇಟಾವನ್ನು ಉತ್ತಮವಾಗಿ ರಕ್ಷಿಸಲಾಗುತ್ತದೆ, ಆದರೆ ನಿಮ್ಮ ಡೇಟಾ ಹೆಚ್ಚು ನಾಶವಾಗುತ್ತದೆ. ಇದು ವಿಶೇಷವಾಗಿ AI ಮತ್ತು ಮಾಡೆಲಿಂಗ್ ಕಾರ್ಯಗಳಿಗೆ ವಿನಾಶಕಾರಿಯಾಗಿದೆ, ಅಲ್ಲಿ "ಮುನ್ಸೂಚಕ ಶಕ್ತಿ" ಅವಶ್ಯಕವಾಗಿದೆ, ಏಕೆಂದರೆ ಕೆಟ್ಟ ಗುಣಮಟ್ಟದ ಡೇಟಾವು AI ಮಾದರಿಯಿಂದ ಕೆಟ್ಟ ಒಳನೋಟಗಳಿಗೆ ಕಾರಣವಾಗುತ್ತದೆ. SAS ಇದನ್ನು ಪ್ರದರ್ಶಿಸಿತು, ಕರ್ವ್ ಅಡಿಯಲ್ಲಿ (AUC*) ಪ್ರದೇಶವು 0.5 ಕ್ಕೆ ಹತ್ತಿರದಲ್ಲಿದೆ, ಅನಾಮಧೇಯ ಡೇಟಾದ ಮೇಲೆ ತರಬೇತಿ ಪಡೆದ ಮಾದರಿಗಳು ಅತ್ಯಂತ ಕೆಟ್ಟದಾಗಿ ಕಾರ್ಯನಿರ್ವಹಿಸುತ್ತವೆ ಎಂದು ತೋರಿಸುತ್ತದೆ.
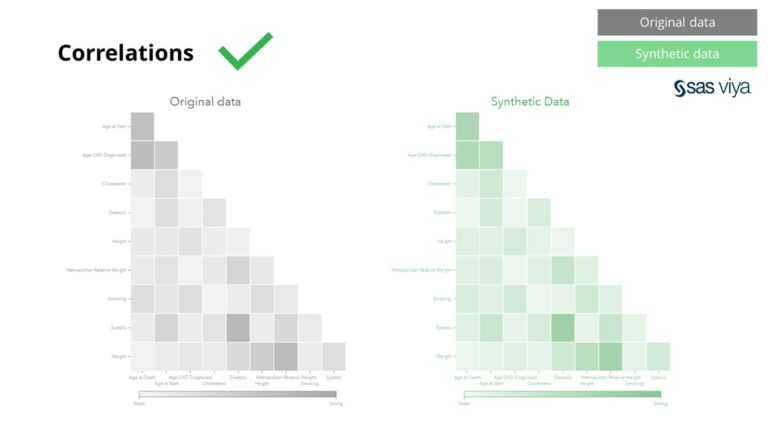
ಅಸ್ಥಿರಗಳ ನಡುವಿನ ಪರಸ್ಪರ ಸಂಬಂಧಗಳು ಮತ್ತು ಸಂಬಂಧಗಳನ್ನು ಸಂಶ್ಲೇಷಿತ ಡೇಟಾದಲ್ಲಿ ನಿಖರವಾಗಿ ಸಂರಕ್ಷಿಸಲಾಗಿದೆ.
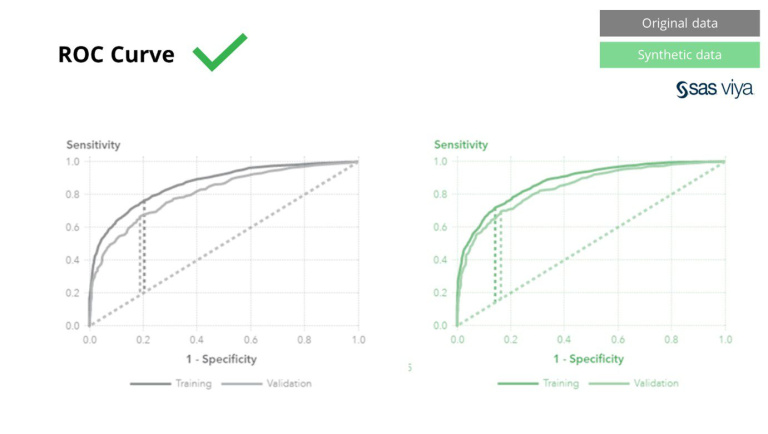
ಏರಿಯಾ ಅಂಡರ್ ದಿ ಕರ್ವ್ (AUC), ಮಾದರಿ ಕಾರ್ಯಕ್ಷಮತೆಯನ್ನು ಅಳೆಯುವ ಒಂದು ಮೆಟ್ರಿಕ್ ಸ್ಥಿರವಾಗಿ ಉಳಿಯಿತು.
ಇದಲ್ಲದೆ, ಒಂದು ಮಾದರಿಯಲ್ಲಿನ ಅಸ್ಥಿರಗಳ ಭವಿಷ್ಯಸೂಚಕ ಶಕ್ತಿಯನ್ನು ಸೂಚಿಸುವ ವೇರಿಯಬಲ್ ಪ್ರಾಮುಖ್ಯತೆಯು ಸಿಂಥೆಟಿಕ್ ಡೇಟಾವನ್ನು ಮೂಲ ಡೇಟಾಸೆಟ್ಗೆ ಹೋಲಿಸಿದಾಗ ಹಾಗೆಯೇ ಉಳಿಯುತ್ತದೆ.
ಎಸ್ಎಎಸ್ನ ಈ ಅವಲೋಕನಗಳ ಆಧಾರದ ಮೇಲೆ ಮತ್ತು ಎಸ್ಎಎಸ್ ವಿಯಾ ಬಳಸುವ ಮೂಲಕ, ಸಿಂಥೋ ಇಂಜಿನ್ನಿಂದ ಉತ್ಪತ್ತಿಯಾಗುವ ಸಂಶ್ಲೇಷಿತ ಡೇಟಾವು ಗುಣಮಟ್ಟದ ವಿಷಯದಲ್ಲಿ ನೈಜ ಡೇಟಾಗೆ ಸಮನಾಗಿರುತ್ತದೆ ಎಂದು ನಾವು ವಿಶ್ವಾಸದಿಂದ ತೀರ್ಮಾನಿಸಬಹುದು. ಇದು ಮಾದರಿ ಅಭಿವೃದ್ಧಿಗಾಗಿ ಸಿಂಥೆಟಿಕ್ ಡೇಟಾದ ಬಳಕೆಯನ್ನು ಮೌಲ್ಯೀಕರಿಸುತ್ತದೆ, ಸಂಶ್ಲೇಷಿತ ಡೇಟಾದೊಂದಿಗೆ ಸುಧಾರಿತ ವಿಶ್ಲೇಷಣೆಗೆ ದಾರಿ ಮಾಡಿಕೊಡುತ್ತದೆ.
