Gettu hver? 5 dæmi hvers vegna það er ekki möguleiki að fjarlægja nöfn



Gettu hver? Þó að ég sé viss um að flest ykkar þekkið þennan leik frá upphafi, hér er stutt samantekt. Markmið leiksins: uppgötvaðu nafn teiknimyndapersónunnar sem andstæðingurinn valdi með því að spyrja „já“ og „nei“ spurninga, eins og „ber manneskjan hatt?“ eða „er maðurinn með gleraugu“? Leikmenn útrýma frambjóðendum út frá viðbrögðum andstæðingsins og læra eiginleika sem tengjast leyndardómspersónu andstæðingsins. Fyrsti leikmaðurinn sem reiknar út leyndardómspersónu hins leikmannsins vinnur leikinn.
Þú fékkst það. Maður verður að bera kennsl á einstaklinginn úr gagnasafni með því að hafa aðeins aðgang að samsvarandi eiginleikum. Reyndar sjáum við reglulega þetta hugtak um Giska á hverjir beittu í reynd en síðan notaðir á gagnasett sem eru sniðin með röðum og dálkum sem innihalda eiginleika raunverulegs fólks. Aðalmunurinn þegar unnið er með gögn er að fólk hefur tilhneigingu til að vanmeta hversu auðvelt er að afhjúpa raunverulega einstaklinga með því að hafa aðgang að örfáum eiginleikum.
Eins og leikurinn Guess Who sýnir, getur einhver greint einstaklinga með því að hafa aðgang að örfáum eiginleikum. Það þjónar sem einfalt dæmi um hvers vegna að fjarlægja aðeins „nöfn“ (eða önnur bein auðkenni) úr gagnasafninu þínu mistekst sem nafnleyndartækni. Í þessu bloggi veitum við fjögur hagnýt tilfelli til að upplýsa þig um friðhelgi einkalífsins í tengslum við að fjarlægja dálka sem leið til nafnleyndar gagna.
Hættan á tengingarárásum er mikilvægasta ástæðan fyrir því að eingöngu að fjarlægja nöfn virkar ekki (lengur) sem aðferð til nafnleyndar. Með tengingarárás sameinar árásarmaðurinn frumgögnin með öðrum aðgengilegum gagnaheimildum til að auðkenna einstakling á einstakan hátt og læra (oft viðkvæmar) upplýsingar um þennan einstakling.
Lykilatriðið hér er framboð annarra gagnaauðlinda sem eru til staðar núna eða geta orðið til staðar í framtíðinni. Hugsaðu um sjálfan þig. Hversu mikið af eigin persónulegum gögnum er að finna á Facebook, Instagram eða LinkedIn sem gæti hugsanlega verið misnotuð vegna tengingarárása?
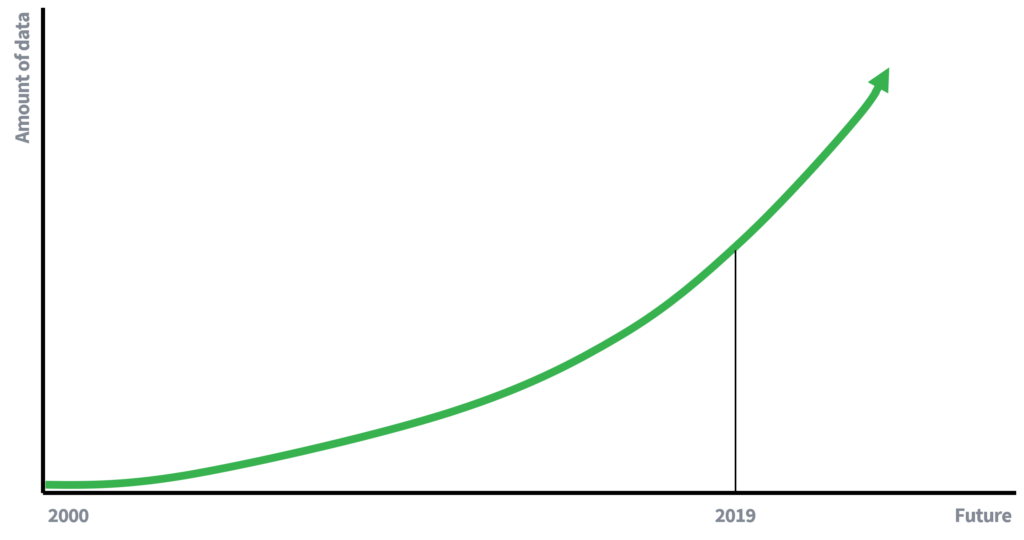
Fyrr á dögum var framboð gagna mun takmarkaðra, sem skýrir að hluta til hvers vegna fjarlæging nafna var nægjanleg til að varðveita friðhelgi einkalífs einstaklinga. Minni tiltæk gögn þýðir færri tækifæri til að tengja gögn. Hins vegar erum við núna (virkir) þátttakendur í gagnadrifnu hagkerfi, þar sem gagnamagnið eykst á veldisvísitölu. Fleiri gögn og bætt tækni til að safna gögnum mun leiða til aukinnar möguleika á tengingarárásum. Hvað myndi maður skrifa eftir 10 ár um hættuna á tengingarárás?
Mynd 1
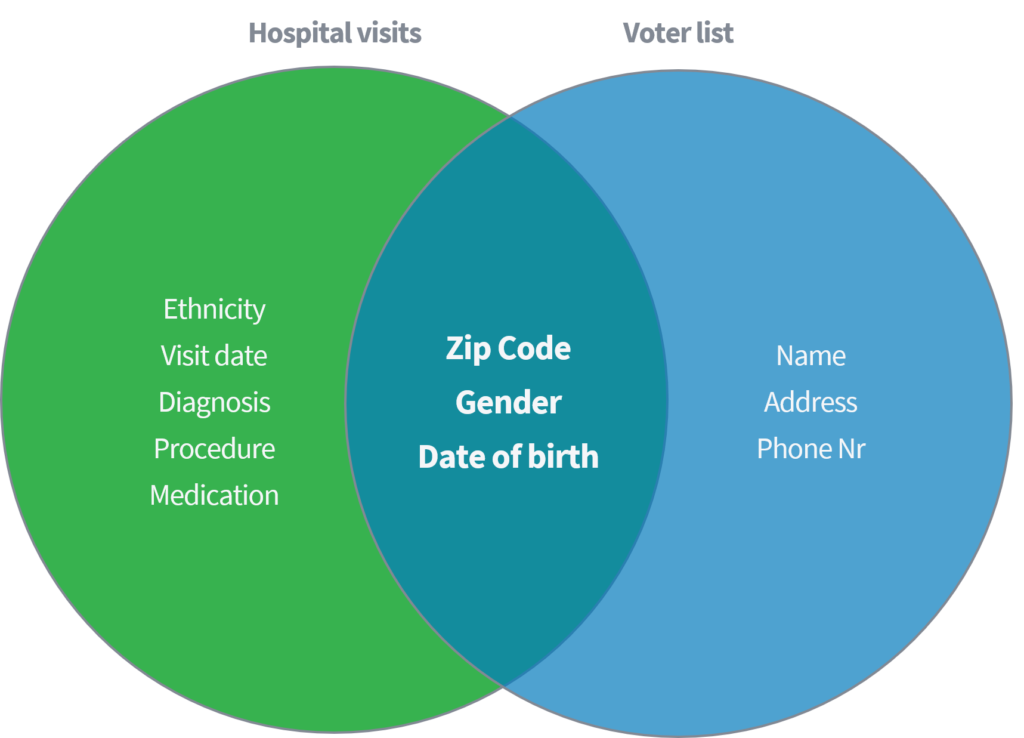
Sweeney (2002) sýndi fram á í fræðiritum hvernig hún gat greint og sótt viðkvæm læknisfræðileg gögn frá einstaklingum á grundvelli þess að tengja fyrirliggjandi gagnasafn „sjúkrahúsheimsókna“ við opinberan kjörritara í Bandaríkjunum. Báðar gagnasettin voru talin vera rétt nafnleynd með því að eyða nöfnum og öðrum beinum auðkennum.
Mynd 2
Byggt á aðeins þremur breytum (1) póstnúmer, (2) kyni og (3) fæðingardag, sýndi hún að hægt væri að auðkenna 87% alls bandarísks íbúa með því að passa áðurnefnda eiginleika frá báðum gagnasöfnunum. Sweeney endurtók síðan vinnu sína með því að hafa „land“ sem valkost við „póstnúmer“. Að auki sýndi hún fram á að aðeins væri hægt að bera kennsl á 18% af öllum bandarískum íbúum með því að hafa aðgang að gagnasafni sem inniheldur upplýsingar um (1) heimaland, (2) kyn og (3) fæðingardag. Hugsaðu um áðurnefndar opinberar heimildir, eins og Facebook, LinkedIn eða Instagram. Er land þitt, kyn og fæðingardagur sýnilegur eða geta aðrir notendur dregið það frá?
Mynd 3
| Svipuð auðkenni | % einstaklega auðkennd af bandarískum íbúum (248 milljónir) |
| 5 stafa ZIP, kyn, fæðingardagur | 87% |
| staður, kyn, fæðingardagur | 53% |
| land, kyn, fæðingardagur | 18% |
Þetta dæmi sýnir að það getur verið ótrúlega auðvelt að afnema einstaklinga í að því er virðist nafnlausum gögnum. Í fyrsta lagi bendir þessi rannsókn á mikla áhættu, eins og Auðvelt er að bera kennsl á 87% Bandaríkjamanna með því að nota það fáein einkenni. Í öðru lagi voru afhjúpuð læknisfræðileg gögn í þessari rannsókn mjög viðkvæm. Dæmi um gögn einstaklinga sem verða fyrir áhrifum úr gagnasafni sjúkrahúsheimilda eru ma þjóðerni, greining og lyfjameðferð. Eiginleikar sem maður getur frekar leynt, til dæmis frá tryggingafélögum.
Önnur hætta á því að fjarlægja aðeins bein auðkenni, svo sem nöfn, kemur upp þegar upplýstir einstaklingar hafa yfirburða þekkingu eða upplýsingar um eiginleika eða hegðun tiltekinna einstaklinga í gagnasafninu. Á grundvelli þekkingar þeirra gæti árásarmaðurinn þá getað tengt tilteknar gagnaskrár við raunverulegt fólk.
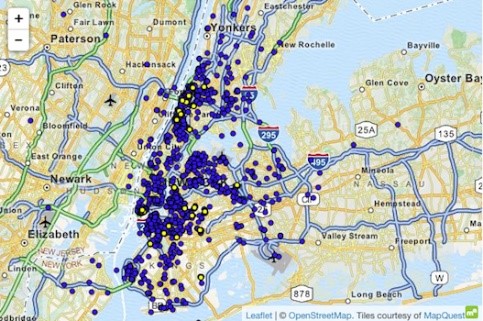
Dæmi um árás á gagnasafn með betri þekkingu er leigubílamálið í New York, þar sem Atockar (2014) gat afhjúpað tiltekna einstaklinga. Gagnasafnið sem notað var innihélt allar leigubílaferðir í New York, auðgaðar með grunneiginleikum eins og upphafshnitum, endahnitum, verði og þjórfé ferðarinnar.
Upplýstur einstaklingur sem veit að New York var fær um að leigubílaferðir til fullorðinsfélagsins 'Hustler'. Með því að sía „lokastaðsetninguna“ dró hann ályktun um upphafsföngin og benti þar með á ýmsa tíða gesti. Á sama hátt mætti ráða leigubílaferðir þegar heimili heimilisfang einstaklingsins var þekkt. Tími og staðsetning nokkurra fræga kvikmyndastjarna fannst á slúðurstöðum. Eftir að hafa tengt þessar upplýsingar við NYC leigubílagögnin var auðvelt að komast að leigubílaferðum þeirra, upphæðinni sem þeir greiddu og hvort þeir hefðu gefið ábendingu.
Mynd 4
brottfararhnit Hustler
Bradley Cooper
Jessica Alba
Algeng röksemdafærsla er „þessi gögn eru einskis virði“ eða „enginn getur gert neitt með þessum gögnum“. Þetta er oft misskilningur. Jafnvel saklausustu gögnin geta myndað einstakt „fingrafar“ og notað til að bera kennsl á einstaklinga aftur. Það er áhættan sem stafar af þeirri trú að gögnin sjálf séu einskis virði en ekki.
Hættan á auðkenningu mun aukast með aukningu gagna, AI og annarra tækja og reiknirita sem gera kleift að afhjúpa flókin tengsl í gögnum. Þar af leiðandi, jafnvel þó að ekki sé hægt að afhjúpa gagnasafnið þitt núna og væntanlega er gagnslaust fyrir óviðkomandi í dag, þá er það kannski ekki á morgun.
Frábært dæmi er tilfellið þar sem Netflix ætlaði að fjölmenna til rannsókna- og þróunardeildar síns með því að kynna opna Netflix samkeppni um að bæta kerfi meðmæli um kvikmyndir. „Sá sem bætir síunaráætlunina fyrir samvinnu til að spá fyrir um einkunnir notenda fyrir kvikmyndir hlýtur 1,000,000 Bandaríkjadala verðlaun“. Til að styðja við fjöldann birti Netflix gagnasafn sem innihélt aðeins eftirfarandi grunneiginleika: userID, bíómynd, dagsetningu einkunnar og einkunn (svo engar frekari upplýsingar um notandann eða myndina sjálfa).
Mynd 5
| Notandanafn | Movie | Dagsetning einkunnar | Grade |
| 123456789 | Verkefni ómögulegt | 10-12-2008 | 4 |
Í einangrun, gögnin virtust tilgangslaus. Þegar spurt var „Eru einhverjar viðskiptavinaupplýsingar í gagnasafninu sem ætti að halda lokuðum?“ Var svarið:
'Nei, allar auðkenningarupplýsingar viðskiptavina hafa verið fjarlægðar; allt sem er eftir eru einkunnir og dagsetningar. Þetta fylgir persónuverndarstefnu okkar ... '
Hins vegar sannaði Narayanan (2008) frá háskólanum í Texas í Austin annað. Samsetning einkunnar, dagsetning einkunnar og kvikmynd einstaklings myndar einstakt kvikmyndafingrafar. Hugsaðu um þína eigin Netflix hegðun. Hversu margir heldurðu að hafi horft á sömu bíómyndina? Hversu margir horfðu á sömu bíómyndina á sama tíma?
Aðalspurning, hvernig á að passa þetta fingrafar? Það var frekar einfalt. Byggt á upplýsingum frá hinni þekktu kvikmyndamatsvef IMDb (Internet Movie Database) gæti svipað fingrafar myndast. Þar af leiðandi væri hægt að bera kennsl á einstaklinga aftur.
Þó að ekki sé talið að hegðun við bíómynd sé viðkvæmar upplýsingar, hugsaðu þá um þína eigin hegðun-væri þér sama þótt hún yrði opinber? Dæmi sem Narayanan gaf upp í blaði sínu eru pólitískar óskir (einkunnir um „Jesú frá Nasaret“ og „Jóhannesarguðspjall“) og kynferðislegar óskir (einkunnir „Bent“ og „Queer as folk“) sem auðvelt væri að eyða.
GDPR er kannski ekki ofurspennandi, né silfurskotið meðal bloggefni. Samt er gagnlegt að koma skilgreiningunum á framfæri við vinnslu persónuupplýsinga. Þar sem þetta blogg er um algengan misskilning að fjarlægja dálka sem leið til að nafnleynd gagna og mennta þig sem gagnavinnsluforrit, skulum við byrja á því að kanna skilgreininguna á nafnleynd samkvæmt GDPR.
Samkvæmt 26. lið frá GDPR eru nafnlausar upplýsingar skilgreindar sem:
„upplýsingar sem varða ekki auðkenna eða auðkenna einstakling eða persónuupplýsingar sem eru gerðar nafnlausar á þann hátt að hinn skráði er ekki eða ekki lengur auðkenndur.“
Þar sem maður vinnur persónuupplýsingar sem tengjast einstaklingi, þá er aðeins 2. hluti skilgreiningarinnar viðeigandi. Til að fara að skilgreiningunni verður maður að tryggja að hinn skráði (einstaklingur) sé ekki eða ekki lengur auðkenndur. Eins og fram kemur í þessu bloggi er hins vegar ótrúlega einfalt að bera kennsl á einstaklinga út frá nokkrum eiginleikum. Svo að fjarlægja nöfn úr gagnasafni er ekki í samræmi við skilgreiningu GDPR á nafnleynd.
Við skoruðum á eina algenga og því miður enn oft notaða nálgun nafnleyndar gagna: að fjarlægja nöfn. Í Guess Who leiknum og fjórum öðrum dæmum um:
það var sýnt að það tókst ekki að fjarlægja nöfn sem nafnleynd. Þrátt fyrir að dæmin séu sláandi tilvik, sýnir hvert þeirra einfaldleika endurmerkingar og hugsanleg neikvæð áhrif á friðhelgi einkalífs einstaklinga.
Að lokum leiðir afnám nafna úr gagnasafninu ekki til nafnlausra gagna. Þess vegna förum við betur að nota bæði hugtökin til skiptis. Ég vona innilega að þú notir ekki þessa aðferð til nafnleyndar. Og ef þú gerir það ennþá, vertu viss um að þú og teymið þitt skiljum að fullu friðhelgi einkalífsins og að þú sért heimilt að samþykkja þá áhættu fyrir hönd einstaklinganna sem verða fyrir áhrifum.
Hafðu samband við Syntho og einn af sérfræðingum okkar mun hafa samband við þig á ljóshraða til að kanna gildi gervigagna!