


A Syntho által generált szintetikus adatokat a SAS adatszakértői külső és objektív szemszögből értékelik, validálják és jóváhagyják.
Bár a Syntho büszke arra, hogy fejlett minőségbiztosítási jelentést kínál felhasználóinak, megértjük annak fontosságát is, hogy az iparág vezetőitől külső és objektív értékelést készítsünk szintetikus adatainkról. Ezért dolgozunk együtt a SAS-szal, az analitika piacvezetőjével, hogy értékeljük szintetikus adatainkat.
A SAS különféle alapos értékeléseket végez a Syntho mesterséges intelligencia által generált szintetikus adatainak az adatok pontosságáról, a magánélet védelméről és használhatóságáról az eredeti adatokhoz képest. Következtetésként a SAS úgy értékelte és jóváhagyta a Syntho szintetikus adatait, hogy azok pontosak, biztonságosak és használhatóak az eredeti adatokhoz képest.
Céladatként olyan távközlési adatokat használtunk, amelyeket a „lemorzsolódás” előrejelzésére használunk. Az értékelés célja az volt, hogy szintetikus adatok felhasználásával különböző lemorzsolódás-előrejelzési modelleket tanítsunk, és értékeljük az egyes modellek teljesítményét. Mivel a lemorzsolódás előrejelzése egy osztályozási feladat, a SAS népszerű osztályozási modelleket választott ki az előrejelzésekhez, többek között:
A szintetikus adatok generálása előtt a SAS véletlenszerűen felosztotta a távközlési adatkészletet egy vonatkészletre (a modellek betanítására) és egy holdout készletre (a modellek pontozására). A pontozáshoz külön megtartási készlet lehetővé teszi annak elfogulatlan értékelését, hogy az osztályozási modell milyen jól működik új adatokra alkalmazva.
A vonatkészletet bemenetként használva a Syntho a Syntho Engine-jét használta szintetikus adatkészlet létrehozására. A teljesítményértékeléshez a SAS létrehozta a vonatkészlet anonimizált változatát is, miután különféle anonimizálási technikákat alkalmazott egy bizonyos küszöb (a k-anonimitás) elérése érdekében. Az előbbi lépések négy adatkészletet eredményeztek:
Az 1., 3. és 4. adatkészletet használtuk az egyes osztályozási modellek betanításához, ami 12 (3 x 4) betanított modellt eredményezett. A SAS ezt követően a visszatartási adatkészletet használta az egyes modellek pontosságának mérésére az ügyfelek lemorzsolódásának előrejelzésében.
A SAS különféle alapos értékeléseket végez a Syntho mesterséges intelligencia által generált szintetikus adatainak az adatok pontosságáról, a magánélet védelméről és használhatóságáról az eredeti adatokhoz képest. Következtetésként a SAS úgy értékelte és jóváhagyta a Syntho szintetikus adatait, hogy azok pontosak, biztonságosak és használhatóak az eredeti adatokhoz képest.
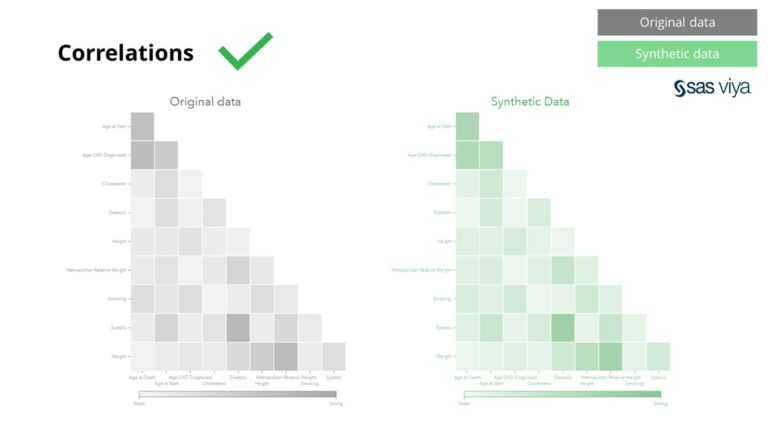
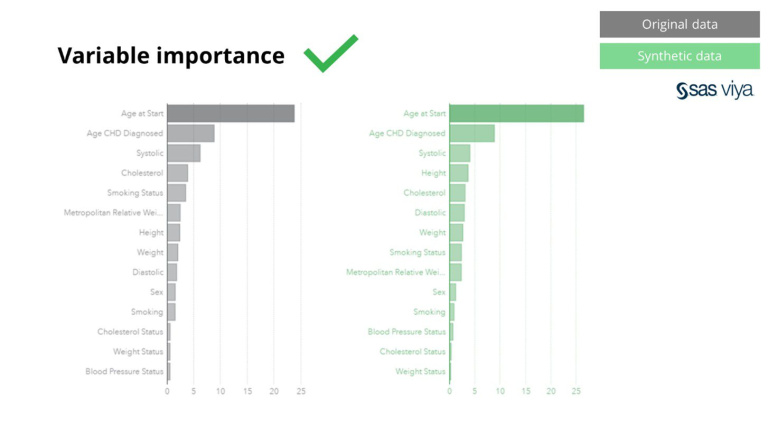
A Syntho szintetikus adatai nem csak az alapvető mintákra vonatkoznak, hanem mély „rejtett” statisztikai mintákat is rögzítenek, amelyek a fejlett elemzési feladatokhoz szükségesek. Ez utóbbit az oszlopdiagram mutatja, jelezve, hogy a szintetikus adatokon betanított modellek és az eredeti adatokon betanított modellek pontossága hasonló. Így a szintetikus adatok felhasználhatók a modellek tényleges betanítására. A szintetikus adatokon az algoritmusok által kiválasztott bemenetek és változó fontosság az eredeti adatokhoz képest nagyon hasonló volt. Ebből az a következtetés vonható le, hogy a modellezési folyamat elvégezhető szintetikus adatokon, mint a valódi érzékeny adatok felhasználásának alternatívája.
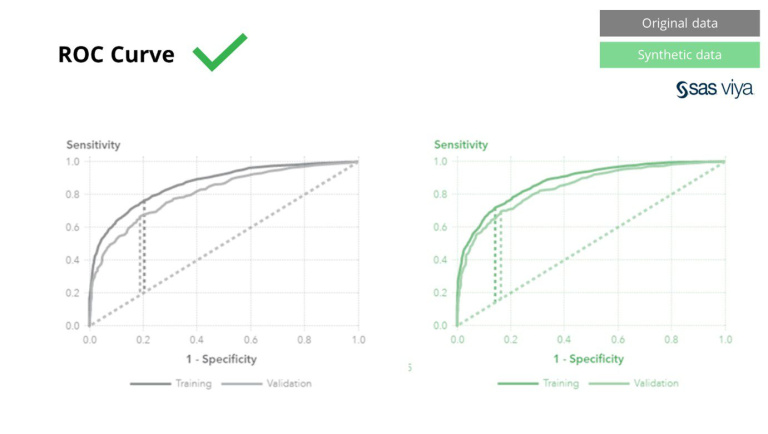
A klasszikus anonimizálási technikák közös jellemzője, hogy az eredeti adatokat manipulálják, hogy megakadályozzák az egyének visszakövetését. Adatokat manipulálnak, és ezáltal az adatokat megsemmisítik a folyamat során. Minél többet anonimizál, annál jobban védik adatait, de annál jobban megsemmisülnek. Ez különösen pusztító a mesterséges intelligencia és a modellezési feladatok esetében, ahol a „jósló erő” elengedhetetlen, mivel a rossz minőségű adatok rossz betekintést eredményeznek az AI-modellből. A SAS ezt 0.5-höz közeli görbe alatti területtel (AUC*) mutatta be, ami azt mutatja, hogy az anonimizált adatokon betanított modellek teljesítenek messze a legrosszabbul.
A változók közötti összefüggéseket és kapcsolatokat a szintetikus adatok pontosan megőrizték.
A görbe alatti terület (AUC), a modell teljesítményének mérésére szolgáló mérőszám konzisztens maradt.
Ezenkívül a változó fontossága, amely a modell változóinak prediktív erejét jelezte, érintetlen maradt a szintetikus adatok és az eredeti adatkészlet összehasonlításakor.
A SAS ezen megfigyelései és a SAS Viya használatával magabiztosan megállapíthatjuk, hogy a Syntho Engine által generált szintetikus adatok minőségileg valóban egyenrangúak a valós adatokkal. Ez hitelesíti a szintetikus adatok használatát a modellfejlesztéshez, és megnyitja az utat a szintetikus adatokkal rendelkező fejlett elemzések előtt.
