ఎవరో కనిపెట్టు? పేర్లను తీసివేయడం ఎందుకు ఎంపిక కాదు అనేదానికి 5 ఉదాహరణలు



ఎవరో కనిపెట్టు? ఈ రోజుల్లో మీలో చాలామందికి ఈ ఆట తెలుసు అని నాకు ఖచ్చితంగా తెలుసు, ఇక్కడ క్లుప్త పునశ్చరణ. ఆట లక్ష్యం: 'అవును' మరియు 'నో' ప్రశ్నలు అడగడం ద్వారా మీ ప్రత్యర్థి ఎంచుకున్న కార్టూన్ పాత్ర పేరును కనుగొనండి, 'వ్యక్తి టోపీ ధరించారా?' లేదా 'వ్యక్తి అద్దాలు ధరిస్తాడా'? ప్రత్యర్థి ప్రతిస్పందన ఆధారంగా ఆటగాళ్లు అభ్యర్థులను తొలగిస్తారు మరియు వారి ప్రత్యర్థి యొక్క రహస్య పాత్రకు సంబంధించిన లక్షణాలను నేర్చుకుంటారు. ఇతర ఆటగాడి రహస్య పాత్రను గుర్తించిన మొదటి ఆటగాడు ఆటను గెలుస్తాడు.
తెలిసిందా. సంబంధిత లక్షణాలకు మాత్రమే ప్రాప్యత కలిగి ఉండటం ద్వారా డేటాసెట్ నుండి వ్యక్తిని గుర్తించాలి. వాస్తవానికి, ఆచరణలో దరఖాస్తు చేసిన గెస్ అనే భావనను మేము క్రమం తప్పకుండా చూస్తాము, కానీ వాస్తవ వ్యక్తుల లక్షణాలను కలిగి ఉన్న అడ్డు వరుసలు మరియు నిలువు వరుసలతో ఫార్మాట్ చేయబడిన డేటాసెట్లలో ఉపయోగించబడ్డాము. డేటాతో పనిచేసేటప్పుడు ప్రధాన వ్యత్యాసం ఏమిటంటే, ప్రజలు కొన్ని లక్షణాలను మాత్రమే యాక్సెస్ చేయడం ద్వారా నిజమైన వ్యక్తులను ముసుగు తీయగల సౌలభ్యాన్ని తక్కువ అంచనా వేస్తారు.
గెస్ హూ గేమ్ వివరిస్తుంది, ఎవరైనా కొన్ని లక్షణాలను మాత్రమే యాక్సెస్ చేయడం ద్వారా వ్యక్తులను గుర్తించవచ్చు. మీ డేటాసెట్ నుండి 'పేర్లు' (లేదా ఇతర డైరెక్ట్ ఐడెంటిఫైయర్లు) మాత్రమే తొలగించడం ఎందుకు అనామక టెక్నిక్గా విఫలమవుతుందనే దానికి ఇది ఒక సాధారణ ఉదాహరణగా పనిచేస్తుంది. ఈ బ్లాగ్లో, డేటా అనామక మార్గంగా నిలువు వరుసలను తీసివేయడంతో సంబంధం ఉన్న గోప్యతా ప్రమాదాల గురించి మీకు తెలియజేయడానికి మేము నాలుగు ఆచరణాత్మక కేసులను అందిస్తున్నాము.
అనామకానికి ఒక పద్ధతిగా పేర్లు తొలగించడం (ఇకపై) పనిచేయకపోవడానికి అనుసంధాన దాడుల ప్రమాదం చాలా ముఖ్యమైన కారణం. లింకేజ్ దాడితో, ఒక వ్యక్తిని ప్రత్యేకంగా గుర్తించడానికి మరియు ఈ వ్యక్తి గురించి (తరచుగా సున్నితమైన) సమాచారాన్ని తెలుసుకోవడానికి దాడి చేసేవారు అసలు డేటాను ఇతర యాక్సెస్ చేయగల డేటా సోర్స్లతో మిళితం చేస్తారు.
ఇప్పుడు ఉన్న ఇతర డేటా వనరుల లభ్యత లేదా భవిష్యత్తులో వర్తమానంగా మారడం ఇక్కడ కీలకం. మీ గురించి ఆలోచించండి. ఫేస్బుక్, ఇన్స్టాగ్రామ్ లేదా లింక్డ్ఇన్లో మీ స్వంత వ్యక్తిగత డేటాను లింకేజ్ దాడి కోసం దుర్వినియోగం చేసే అవకాశం ఎంత?
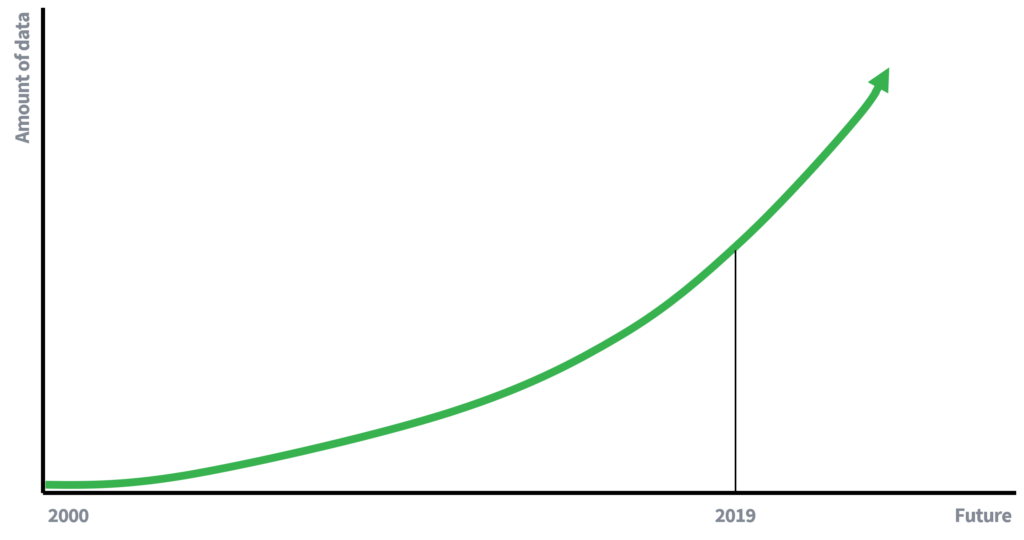
మునుపటి రోజుల్లో, డేటా లభ్యత చాలా పరిమితంగా ఉంది, ఇది వ్యక్తుల గోప్యతను కాపాడటానికి పేర్ల తొలగింపు ఎందుకు సరిపోతుందో పాక్షికంగా వివరిస్తుంది. తక్కువ అందుబాటులో ఉన్న డేటా అంటే డేటాను లింక్ చేయడానికి తక్కువ అవకాశాలు. ఏదేమైనా, మేము ఇప్పుడు డేటా-ఆధారిత ఆర్థిక వ్యవస్థలో (యాక్టివ్) భాగస్వాములుగా ఉన్నాము, ఇక్కడ డేటా మొత్తం విపరీతమైన రేటుతో పెరుగుతోంది. మరింత డేటా, మరియు డేటాను సేకరించడం కోసం సాంకేతికతను మెరుగుపరచడం అనుసంధాన దాడులకు సంభావ్యతను పెంచుతుంది. లింకేజ్ దాడి ప్రమాదం గురించి 10 సంవత్సరాలలో ఒకరు ఏమి వ్రాస్తారు?
ఇలస్ట్రేషన్ 1
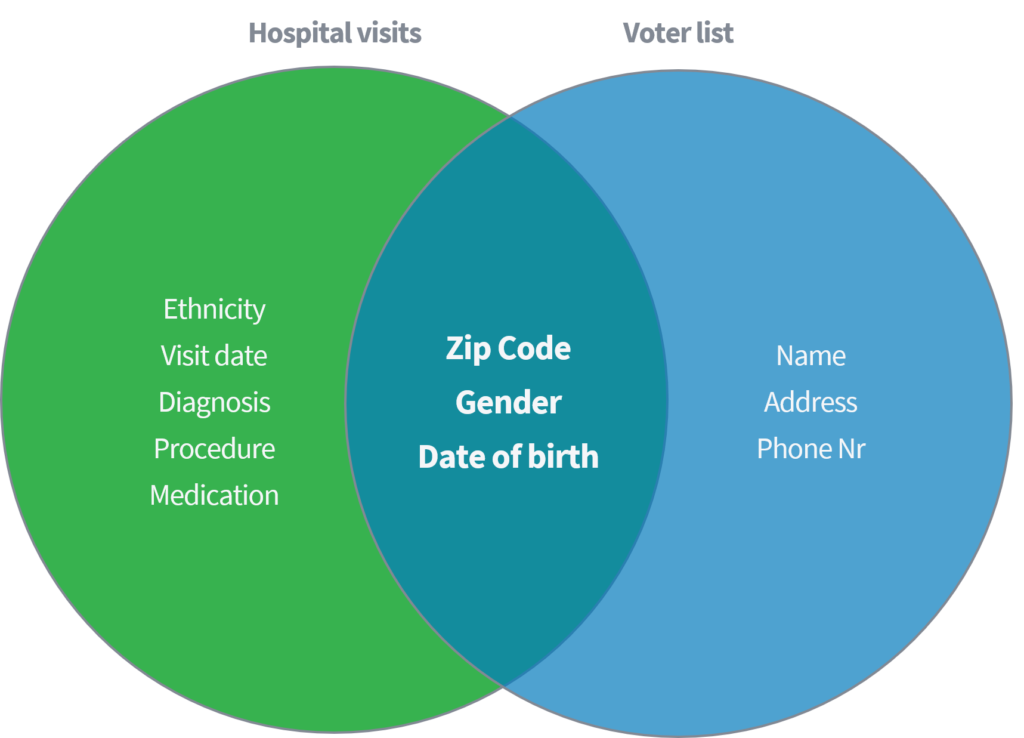
యునైటెడ్ స్టేట్స్లో బహిరంగంగా అందుబాటులో ఉన్న ఓటింగ్ రిజిస్ట్రార్కు 'హాస్పిటల్ విజిట్స్' యొక్క పబ్లిక్ అందుబాటులో ఉన్న డేటా సెట్ని లింక్ చేయడం ద్వారా వ్యక్తుల నుండి సున్నితమైన మెడికల్ డేటాను ఎలా గుర్తించాలో మరియు తిరిగి పొందగలుగుతున్నామో స్వీనీ (2002) ఒక అకాడెమిక్ పేపర్లో ప్రదర్శించింది. పేర్లు మరియు ఇతర డైరెక్ట్ ఐడెంటిఫైయర్లను తొలగించడం ద్వారా రెండు డేటాసెట్లు సరిగ్గా అజ్ఞాతం చేయబడ్డాయి.
ఇలస్ట్రేషన్ 2
మూడు పారామితులు (1) జిప్ కోడ్, (2) లింగం మరియు (3) పుట్టిన తేదీ మాత్రమే ఆధారంగా, మొత్తం US జనాభాలో 87% రెండు డేటాసెట్ల నుండి పైన పేర్కొన్న లక్షణాలను సరిపోల్చడం ద్వారా తిరిగి గుర్తించవచ్చని ఆమె చూపించింది. 'జిప్ కోడ్' కు ప్రత్యామ్నాయంగా 'కంట్రీ' కలిగి ఉండటంతో స్వీనీ తన పనిని పునరావృతం చేసింది. అదనంగా, మొత్తం US జనాభాలో 18% (1) స్వదేశం, (2) లింగం మరియు (3) పుట్టిన తేదీ గురించి సమాచారాన్ని కలిగి ఉన్న డేటాసెట్ని యాక్సెస్ చేయడం ద్వారా మాత్రమే గుర్తించవచ్చని ఆమె నిరూపించింది. Facebook, LinkedIn లేదా Instagram వంటి పైన పేర్కొన్న పబ్లిక్ సోర్స్ల గురించి ఆలోచించండి. మీ దేశం, లింగం మరియు పుట్టిన తేదీ కనిపిస్తుందా లేదా ఇతర వినియోగదారులు దానిని తీసివేయగలరా?
ఇలస్ట్రేషన్ 3
| పాక్షిక-గుర్తింపుదారులు | US జనాభాలో ప్రత్యేకంగా గుర్తించిన % (248 మిలియన్లు) |
| 5 అంకెల జిప్, లింగం, పుట్టిన తేదీ | 87% |
| స్థానం, లింగం, పుట్టిన తేదీ | 53% |
| దేశంలో, లింగం, పుట్టిన తేదీ | 18% |
అనామక డేటాలో వ్యక్తులను అనామకపరచడం చాలా సులభం అని ఈ ఉదాహరణ చూపిస్తుంది. మొదట, ఈ అధ్యయనం భారీ ప్రమాదాన్ని సూచిస్తుంది US జనాభాలో 87% సులభంగా ఉపయోగించి గుర్తించవచ్చు కొన్ని లక్షణాలు. రెండవది, ఈ అధ్యయనంలో బహిర్గతమైన వైద్య డేటా అత్యంత సున్నితమైనది. హాస్పిటల్ సందర్శనల డేటాసెట్ నుండి బహిర్గతమైన వ్యక్తుల డేటా యొక్క ఉదాహరణలు జాతి, రోగ నిర్ధారణ మరియు మందులు. ఉదాహరణకు, బీమా కంపెనీల నుండి రహస్యంగా ఉంచే లక్షణాలు.
డేటాసెట్లోని నిర్దిష్ట వ్యక్తుల లక్షణాలు లేదా ప్రవర్తన గురించి సమాచారం ఉన్న వ్యక్తులకు ఉన్నతమైన జ్ఞానం లేదా సమాచారం ఉన్నప్పుడు పేర్లు వంటి డైరెక్ట్ ఐడెంటిఫైయర్లను మాత్రమే తొలగించే మరో ప్రమాదం తలెత్తుతుంది.. వారి జ్ఞానం ఆధారంగా, దాడి చేసిన వ్యక్తి నిర్దిష్ట డేటా రికార్డులను వాస్తవ వ్యక్తులకు లింక్ చేయగలడు.
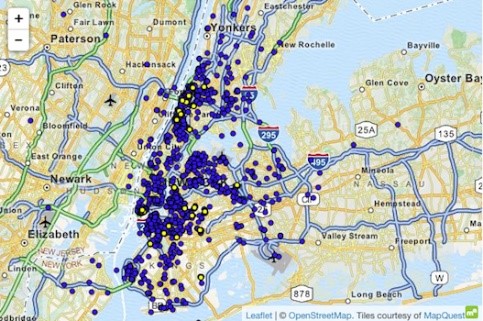
అత్యున్నత పరిజ్ఞానాన్ని ఉపయోగించి డేటాసెట్పై దాడికి ఉదాహరణ న్యూయార్క్ టాక్సీ కేసు, ఇక్కడ అటోకర్ (2014) నిర్దిష్ట వ్యక్తులను ముసుగు తీయగలిగాడు. ఉపాధి డేటాసెట్ న్యూయార్క్లో అన్ని టాక్సీ ప్రయాణాలను కలిగి ఉంది, ప్రారంభ కోఆర్డినేట్లు, ముగింపు కోఆర్డినేట్లు, ధర మరియు రైడ్ చిట్కా వంటి ప్రాథమిక లక్షణాలతో సుసంపన్నం చేయబడింది.
న్యూయార్క్ తెలిసిన సమాచారం ఉన్న వ్యక్తి అడల్ట్ క్లబ్ 'హస్ట్లర్' కు టాక్సీ పర్యటనలను పొందగలిగాడు. 'ఎండ్ లొకేషన్' ను ఫిల్టర్ చేయడం ద్వారా, అతను ఖచ్చితమైన ప్రారంభ చిరునామాలను తీసివేసాడు మరియు తద్వారా తరచూ సందర్శకులను గుర్తించాడు. అదేవిధంగా, వ్యక్తి ఇంటి చిరునామా తెలిసినప్పుడు టాక్సీ సవారీలను తగ్గించవచ్చు. అనేక మంది ప్రముఖ సినీ తారల సమయం మరియు స్థానం గాసిప్ సైట్లలో కనుగొనబడింది. ఈ సమాచారాన్ని NYC టాక్సీ డేటాకు లింక్ చేసిన తర్వాత, వారి టాక్సీ రైడ్లు, వారు చెల్లించిన మొత్తం మరియు వారు టిప్ చేశారా అనే విషయాన్ని సులభంగా పొందవచ్చు.
ఇలస్ట్రేషన్ 4
డ్రాప్-ఆఫ్ కోఆర్డినేట్స్ హస్ట్లర్
బ్రాడ్లీ కూపర్
జెస్సికా ఆల్బా
'ఈ డేటా విలువలేనిది' లేదా 'ఈ డేటాతో ఎవరూ ఏమీ చేయలేరు' అనేది ఒక సాధారణ వాదన. ఇది తరచుగా తప్పుడు అభిప్రాయం. అత్యంత అమాయక డేటా కూడా ప్రత్యేకమైన 'వేలిముద్ర'ను ఏర్పరుస్తుంది మరియు వ్యక్తులను తిరిగి గుర్తించడానికి ఉపయోగించబడుతుంది. డేటా విలువలేనిది అని నమ్మకం నుండి వచ్చిన ప్రమాదం ఇది, అయితే అది కాదు.
డేటా, AI మరియు ఇతర సాధనాలు మరియు డేటాలోని సంక్లిష్ట సంబంధాలను వెలికితీసేలా చేసే అల్గోరిథంల పెరుగుదలతో గుర్తింపు ప్రమాదం పెరుగుతుంది. పర్యవసానంగా, మీ డేటాసెట్ ఇప్పుడు కనుగొనబడకపోయినా, మరియు నేడు అనధికార వ్యక్తులకు బహుశా నిరుపయోగంగా ఉన్నప్పటికీ, అది రేపు కాకపోవచ్చు.
నెట్ఫ్లిక్స్ తమ ఆర్ అండ్ డి డిపార్ట్మెంట్ని క్రౌడ్సోర్స్ చేయడానికి ఉద్దేశించిన ఒక గొప్ప ఉదాహరణ, వారి మూవీ రికమెండేషన్ సిస్టమ్ను మెరుగుపరచడానికి ఓపెన్ నెట్ఫ్లిక్స్ పోటీని ప్రవేశపెట్టడం ద్వారా. 'సినిమాల కోసం వినియోగదారు రేటింగ్లను అంచనా వేయడానికి సహకార ఫిల్టరింగ్ అల్గోరిథంను మెరుగుపరిచినది US $ 1,000,000 బహుమతిని గెలుచుకుంటుంది'. సమూహానికి మద్దతు ఇవ్వడానికి, నెట్ఫ్లిక్స్ కింది ప్రాథమిక లక్షణాలను మాత్రమే కలిగి ఉన్న డేటాసెట్ను ప్రచురించింది: యూజర్ఐడి, మూవీ, గ్రేడ్ మరియు గ్రేడ్ తేదీ (కాబట్టి వినియోగదారు లేదా సినిమాపై మరింత సమాచారం లేదు).
ఇలస్ట్రేషన్ 5
| వినియోగదారుని గుర్తింపు | సినిమా | గ్రేడ్ తేదీ | గ్రేడ్ |
| 123456789 | మిషన్ అసాధ్యం | 10-12-2008 | 4 |
ఒంటరిగా, డేటా నిష్ఫలమైనదిగా కనిపించింది. 'డేటాసెట్లో ప్రైవేట్గా ఉంచాల్సిన కస్టమర్ సమాచారం ఏదైనా ఉందా?' అనే ప్రశ్న అడిగినప్పుడు, సమాధానం:
'లేదు, కస్టమర్ గుర్తించే సమాచారం మొత్తం తీసివేయబడింది; రేటింగ్లు మరియు తేదీలు మాత్రమే మిగిలి ఉన్నాయి. ఇది మా గోప్యతా విధానాన్ని అనుసరిస్తుంది ... '
అయితే, ఆస్టిన్లోని టెక్సాస్ విశ్వవిద్యాలయం నుండి నారాయణన్ (2008) అందుకు విరుద్ధంగా నిరూపించారు. గ్రేడ్లు, గ్రేడ్ తేదీ మరియు ఒక వ్యక్తి యొక్క మూవీ కలయిక ఒక ప్రత్యేకమైన సినిమా-వేలిముద్రను రూపొందిస్తుంది. మీ స్వంత నెట్ఫ్లిక్స్ ప్రవర్తన గురించి ఆలోచించండి. ఒకే సెట్ సినిమాలను ఎంత మంది చూశారని మీరు అనుకుంటున్నారు? ఒకేసారి ఒకే సెట్ సినిమాలను ఎంతమంది చూశారు?
ప్రధాన ప్రశ్న, ఈ వేలిముద్రను ఎలా సరిపోల్చాలి? ఇది చాలా సులభం. ప్రసిద్ధ మూవీ-రేటింగ్ వెబ్సైట్ IMDb (ఇంటర్నెట్ మూవీ డేటాబేస్) నుండి వచ్చిన సమాచారం ఆధారంగా, ఇలాంటి వేలిముద్ర ఏర్పడవచ్చు. పర్యవసానంగా, వ్యక్తులను తిరిగి గుర్తించవచ్చు.
సినిమా చూసే ప్రవర్తన సున్నితమైన సమాచారంగా భావించబడకపోయినా, మీ స్వంత ప్రవర్తన గురించి ఆలోచించండి-ఇది పబ్లిక్గా వెళితే మీకు అభ్యంతరం ఉందా? నారాయణన్ తన పేపర్లో అందించిన ఉదాహరణలు రాజకీయ ప్రాధాన్యతలు ('జీసస్ ఆఫ్ నజరేత్' మరియు 'ది గోస్పెల్ ఆఫ్ జాన్') మరియు లైంగిక ప్రాధాన్యతలు ('బెంట్' మరియు 'క్వీర్ యాజ్ జానపద' రేటింగ్లు) సులభంగా స్వేదనం చేయబడతాయి.
GDPR సూపర్-ఉత్తేజకరమైనది కాకపోవచ్చు లేదా బ్లాగ్ అంశాలలో వెండి బుల్లెట్ కాదు. అయినప్పటికీ, వ్యక్తిగత డేటాను ప్రాసెస్ చేసేటప్పుడు నేరుగా నిర్వచనాలను పొందడం సహాయపడుతుంది. ఈ బ్లాగ్ డేటాను అనామకపరచడానికి మరియు డేటా ప్రాసెసర్గా మీకు అవగాహన కల్పించడానికి ఒక మార్గంగా నిలువు వరుసలను తొలగించడం అనే సాధారణ అపోహ గురించి, GDPR ప్రకారం అనామక నిర్వచనాన్ని అన్వేషించడం ప్రారంభిద్దాం.
GDPR నుండి పారాయణం 26 ప్రకారం, అనామక సమాచారం ఇలా నిర్వచించబడింది:
'గుర్తించబడిన లేదా గుర్తించదగిన సహజ వ్యక్తి లేదా వ్యక్తిగత డేటాతో సంబంధం లేని సమాచారం అనామకంగా అందించబడుతుంది.
సహజమైన వ్యక్తికి సంబంధించిన వ్యక్తిగత డేటాను ప్రాసెస్ చేయడం వలన, నిర్వచనంలో భాగం 2 మాత్రమే సంబంధితంగా ఉంటుంది. నిర్వచనాన్ని అనుసరించడానికి, డేటా విషయం (వ్యక్తి) గుర్తించబడదు లేదా ఇకపై గుర్తించబడదని నిర్ధారించుకోవాలి. ఈ బ్లాగ్లో సూచించినట్లుగా, కొన్ని లక్షణాల ఆధారంగా వ్యక్తులను గుర్తించడం చాలా సులభం. కాబట్టి, డేటాసెట్ నుండి పేర్లను తీసివేయడం అనామకీకరణ యొక్క GDPR నిర్వచనానికి అనుగుణంగా లేదు.
మేము సాధారణంగా పరిగణించబడే ఒకదాన్ని సవాలు చేసాము మరియు దురదృష్టవశాత్తూ, డేటా అనామకీకరణ యొక్క తరచుగా వర్తించే విధానాన్ని సవాలు చేసాము: పేర్లను తొలగించడం. హూ హూ గేమ్ మరియు దీని గురించి నాలుగు ఇతర ఉదాహరణలు:
పేర్లను తొలగించడం అనామకత్వంగా విఫలమవుతుందని చూపబడింది. ఉదాహరణలు అద్భుతమైన కేసులు అయినప్పటికీ, ప్రతి ఒక్కటి తిరిగి గుర్తింపు యొక్క సరళతను చూపుతాయి మరియు వ్యక్తుల గోప్యతపై సంభావ్య ప్రతికూల ప్రభావం.
ముగింపులో, మీ డేటాసెట్ నుండి పేర్ల తొలగింపు అనామక డేటాకి దారితీయదు. అందువల్ల, మేము రెండు పదాలను పరస్పరం మార్చుకోకుండా ఉండటం మంచిది. అజ్ఞాతీకరణ కోసం మీరు ఈ విధానాన్ని వర్తించరని నేను హృదయపూర్వకంగా ఆశిస్తున్నాను. మరియు, మీరు ఇంకా అలా చేస్తే, మీరు మరియు మీ బృందం గోప్యతా నష్టాలను పూర్తిగా అర్థం చేసుకున్నారని నిర్ధారించుకోండి మరియు బాధిత వ్యక్తుల తరపున ఆ నష్టాలను అంగీకరించడానికి అనుమతించబడతాయి.
సింథోని సంప్రదించండి మరియు సింథటిక్ డేటా విలువను అన్వేషించడానికి మా నిపుణులలో ఒకరు కాంతి వేగంతో మిమ్మల్ని సంప్రదిస్తారు!